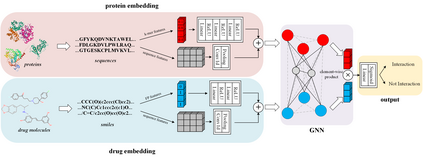
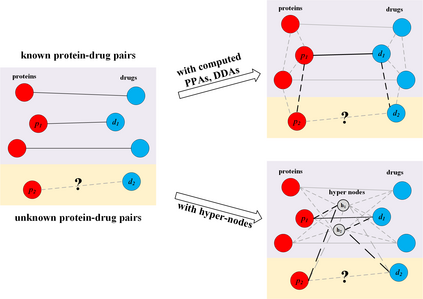
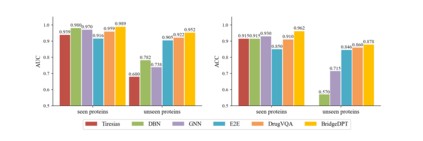
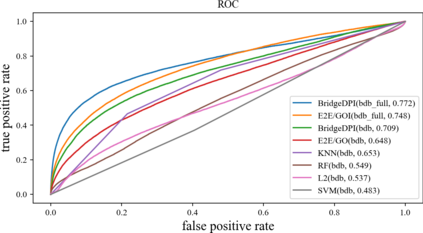
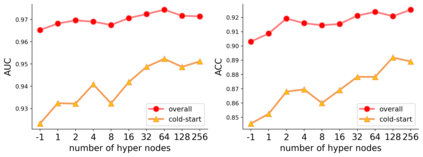
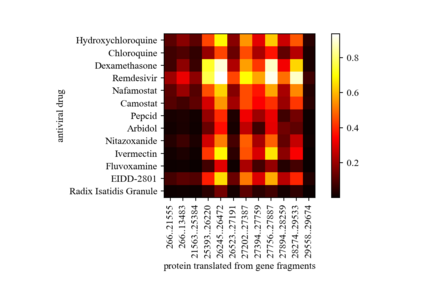
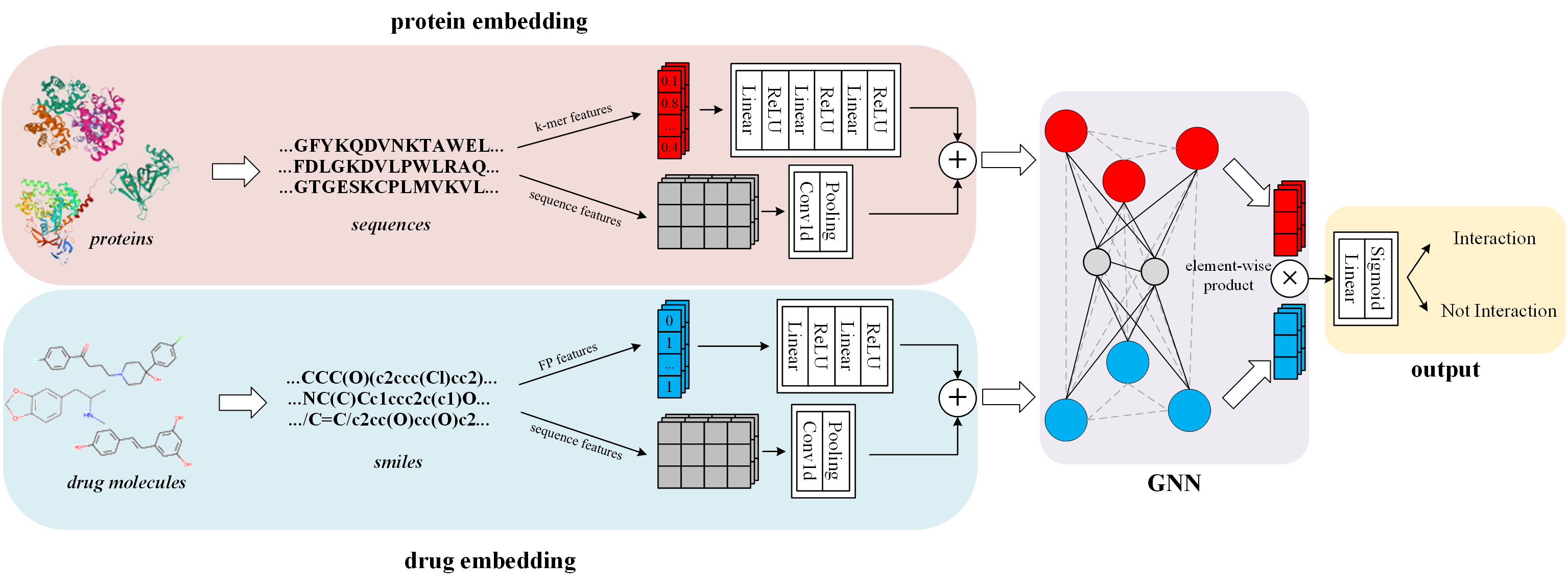
Motivation: Exploring drug-protein interactions (DPIs) work as a pivotal step in drug discovery. The fast expansion of available biological data enables computational methods effectively assist in experimental methods. Among them, deep learning methods extract features only from basic characteristics, such as protein sequences, molecule structures. Others achieve significant improvement by learning from not only sequences/molecules but the protein-protein and drug-drug associations (PPAs and DDAs). The PPAs and DDAs are generally obtained by using computational methods. However, existing computational methods have some limitations, resulting in low-quality PPAs and DDAs that hamper the prediction performance. Therefore, we hope to develop a novel supervised learning method to learn the PPAs and DDAs effectively and thereby improve the prediction performance of the specific task of DPI. Results: In this research, we propose a novel deep learning framework, namely BridgeDPI. BridgeDPI introduces a class of nodes named hyper-nodes, which bridge different proteins/drugs to work as PPAs and DDAs. The hyper-nodes can be supervised learned for the specific task of DPI since the whole process is an end-to-end learning. Consequently, such a model would improve prediction performance of DPI. In three real-world datasets, we further demonstrate that BridgeDPI outperforms state-of-the-art methods. Moreover, ablation studies verify the effectiveness of the hyper-nodes. Last, in an independent verification, BridgeDPI explores the candidate bindings among COVID-19's proteins and various antiviral drugs. And the predictive results accord with the statement of the World Health Organization and Food and Drug Administration, showing the validity and reliability of BridgeDPI.
翻译:动力:探索药物-蛋白质互动(DPIs)是药物发现的关键步骤。快速扩展现有生物数据使计算方法能够有效地协助实验方法。其中,深层次学习方法只能从蛋白序列、分子结构等基本特征中提取特征。其他方法通过学习序列/分子序列和蛋白质-蛋白质和药物协会(PPAAs和DDAs),不仅从序列/分子中学习,而且从蛋白质-蛋白质和药物协会(PPAAs和DDAs)学习,取得了显著的改进。PPPAs和DDAs通常通过计算方法获得。但是,现有的计算方法有一些局限性,导致低质量PPPAs和DDDDs的计算方法有效地帮助了计算方法。因此,我们希望开发一种受监督的受监督的学习方法,以便有效地学习PPPPAPA和DDADAs的基本特征,从而改进了新闻部具体任务的预测性能。结果:在这项研究中,我们从ODI的准确性研究中可以展示一个真正的数据,从PAILLLLLLLLA的成绩,然后再展示。