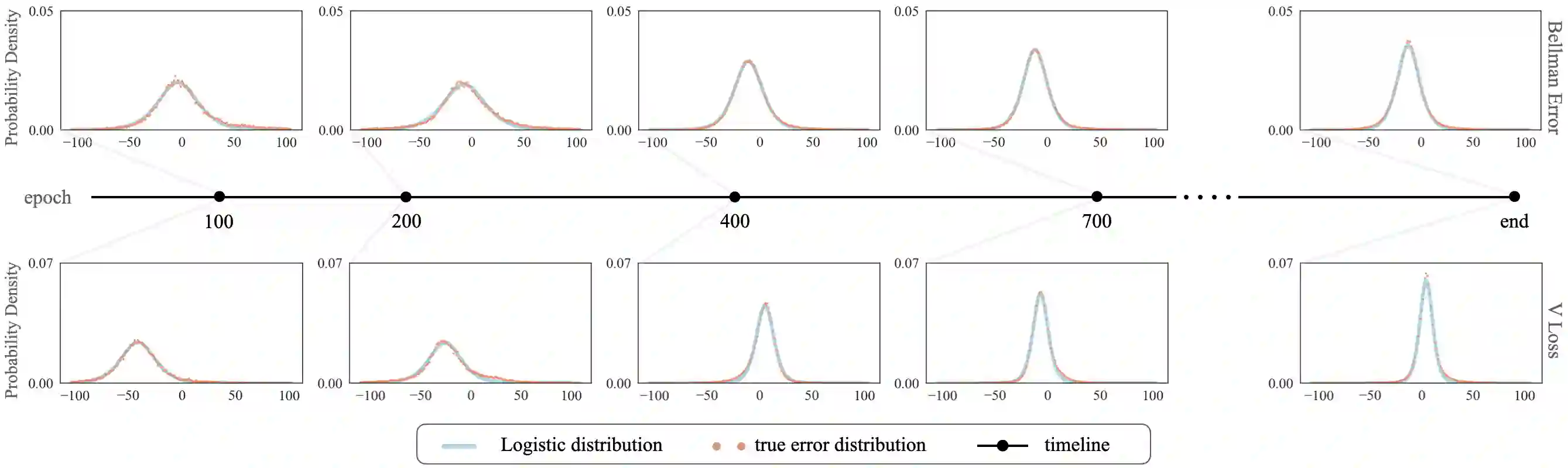
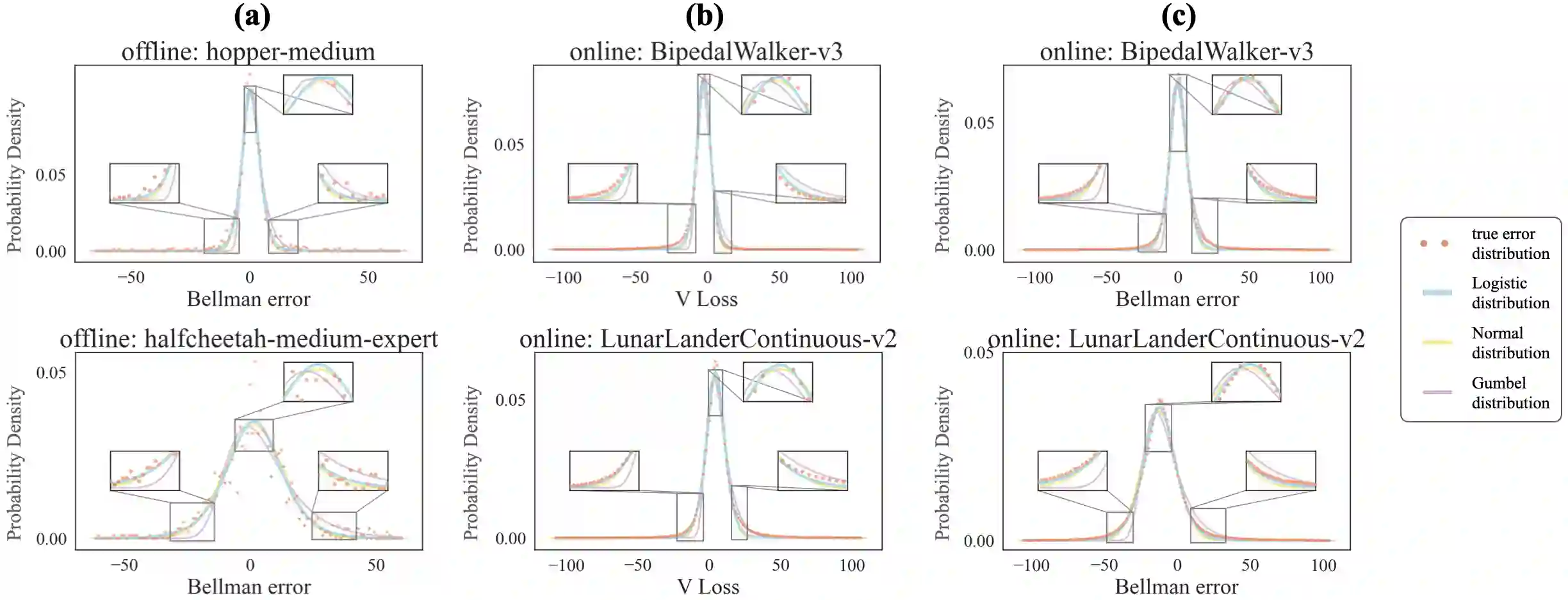
Modern reinforcement learning (RL) can be categorized into online and offline variants. As a pivotal aspect of both online and offline RL, current research on the Bellman equation revolves primarily around optimization techniques and performance enhancement rather than exploring the inherent structural properties of the Bellman error, such as its distribution characteristics. This study investigates the distribution of the Bellman approximation error in both online and offline settings through iterative exploration of the Bellman equation. We observed that both in online RL and offline RL, the Bellman error conforms to a Logistic distribution. Building upon this discovery, this study employed the Logistics maximum likelihood function (LLoss) as an alternative to the commonly used MSE Loss, assuming that Bellman errors adhere to a normal distribution. We validated our hypotheses through extensive numerical experiments across diverse online and offline environments. In particular, we applied corrections to the loss function across various baseline algorithms and consistently observed that the loss function with Logistic corrections outperformed the MSE counterpart significantly. Additionally, we conducted Kolmogorov-Smirnov tests to confirm the reliability of the Logistic distribution. This study's theoretical and empirical insights provide valuable groundwork for future investigations and enhancements centered on the distribution of Bellman errors.
翻译:暂无翻译