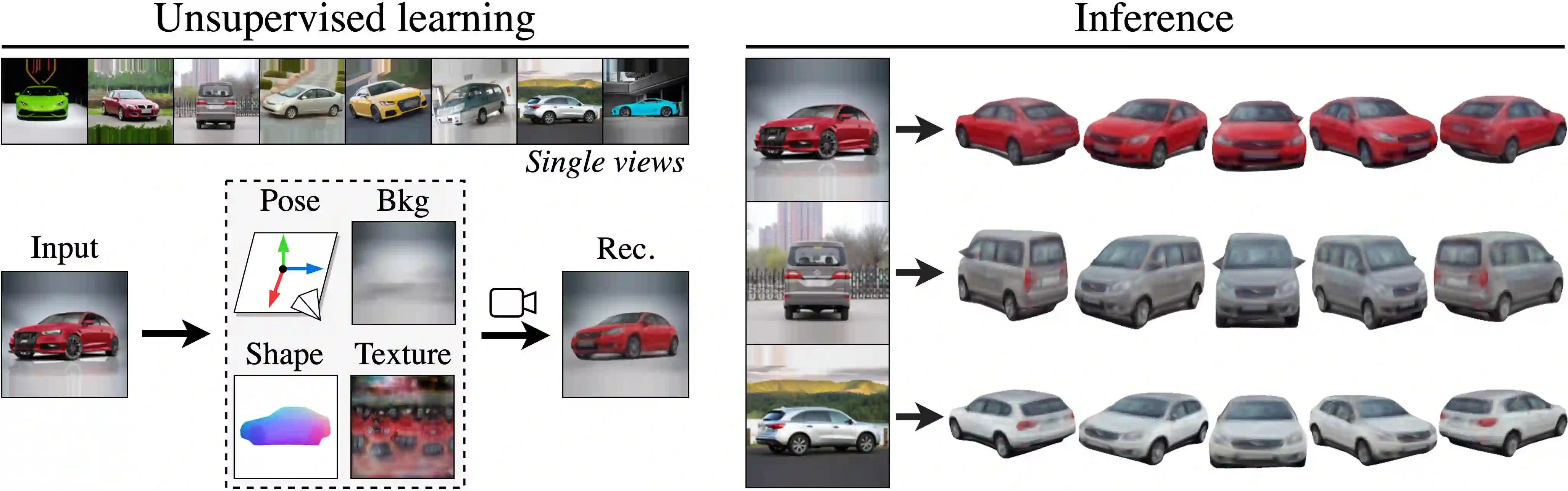
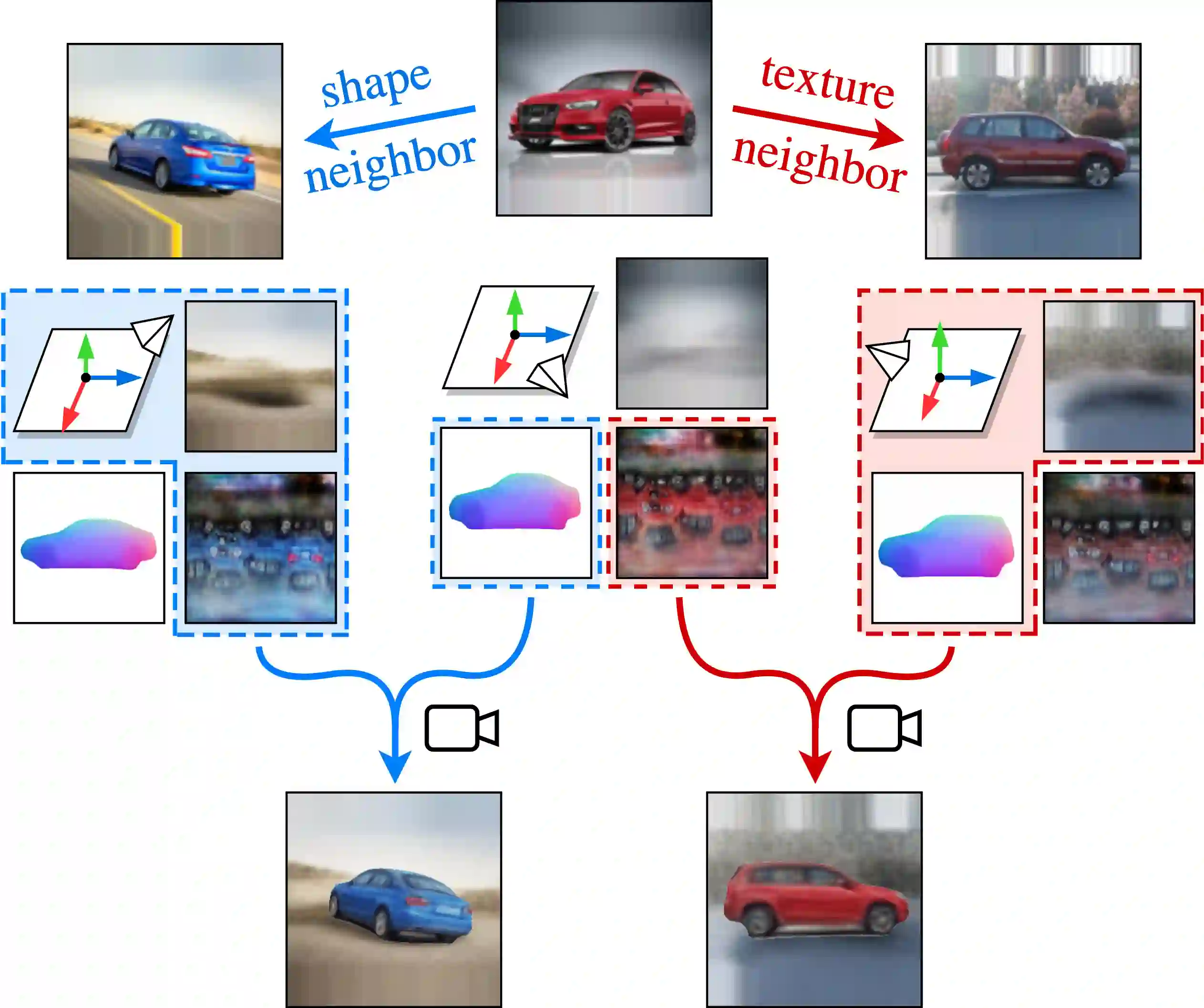
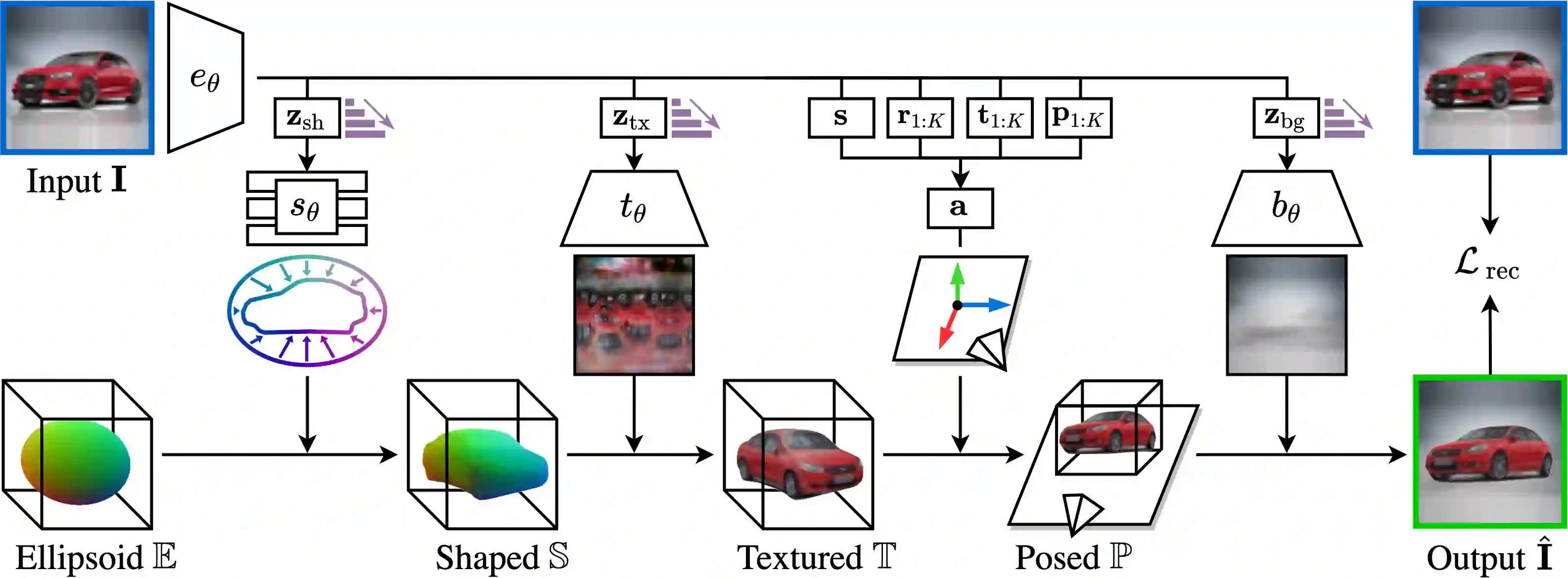
Approaches to single-view reconstruction typically rely on viewpoint annotations, silhouettes, the absence of background, multiple views of the same instance, a template shape, or symmetry. We avoid all of these supervisions and hypotheses by leveraging explicitly the consistency between images of different object instances. As a result, our method can learn from large collections of unlabelled images depicting the same object category. Our main contributions are two approaches to leverage cross-instance consistency: (i) progressive conditioning, a training strategy to gradually specialize the model from category to instances in a curriculum learning fashion; (ii) swap reconstruction, a loss enforcing consistency between instances having similar shape or texture. Critical to the success of our method are also: our structured autoencoding architecture decomposing an image into explicit shape, texture, pose, and background; an adapted formulation of differential rendering, and; a new optimization scheme alternating between 3D and pose learning. We compare our approach, UNICORN, both on the diverse synthetic ShapeNet dataset - the classical benchmark for methods requiring multiple views as supervision - and on standard real-image benchmarks (Pascal3D+ Car, CUB-200) for which most methods require known templates and silhouette annotations. We also showcase applicability to more challenging real-world collections (CompCars, LSUN), where silhouettes are not available and images are not cropped around the object.
翻译:单视图重建的方法通常依赖于观点说明、 双光图、 背景的缺失、 同一实例的多重观点、 模板形状或对称性。 我们避免所有这些监督和假设, 明确利用不同对象实例图像的一致性。 因此, 我们的方法可以从大量未贴标签的图像中学习, 描述同一对象类别。 我们的主要贡献是利用交叉访问一致性的两种方法:(一) 渐进调节, 一种培训战略, 逐步将模型从类别逐渐专门化为课程学习时的范例;(二) 互换重建, 使类似形状或纹理的事例之间出现一致性。 我们方法成功的关键还包括: 我们结构化的自动编码架构将图像分解成清晰的形状、 纹理、 外观和背景; 调整差异转换和3D之间的新的优化计划。 我们比较了我们的方法, UNICORN, 两种方法都是在不同的合成 ShapeNet 数据集上, 一种是需要多重观点的方法的典型基准, 以及标准性目标或质变的图像基准( Pascal3D+ Charboral), 其中最熟悉的S- Chembilal 要求S- hest slifilling 和Charbass