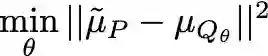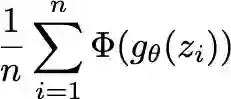Training even moderately-sized generative models with differentially-private stochastic gradient descent (DP-SGD) is difficult: the required level of noise for reasonable levels of privacy is simply too large. We advocate instead building off a good, relevant representation on public data, then using private data only for "transfer learning." In particular, we minimize the maximum mean discrepancy (MMD) between private target data and the generated distribution, using a kernel based on perceptual features from a public dataset. With the MMD, we can simply privatize the data-dependent term once and for all, rather than introducing noise at each step of optimization as in DP-SGD. Our algorithm allows us to generate CIFAR10-level images faithfully with $\varepsilon \approx 2$, far surpassing the current state of the art, which only models MNIST and FashionMNIST at $\varepsilon \approx 10$. Our work introduces simple yet powerful foundations for reducing the gap between private and non-private deep generative models.
翻译:培训甚至中等规模的基因模型也很难做到:合理隐私水平所需的噪音水平实在太高。我们主张在公共数据上建立良好的相关代表性,然后只使用私人数据进行“转移学习 ” 。 特别是,我们尽可能缩小私人目标数据与生成的分布之间的最大平均差异(MMD ), 使用基于公共数据集概念特征的内核。 有了MMD, 我们可以一劳永逸地将依赖数据的术语私有化, 而不是像DP-SGD那样在优化的每一步都引入噪音。 我们的算法允许我们忠实地制作CIRA10级图像, 价格为$\varepslon \ approx 2, 远远超过目前艺术状态, 只有MNIST和FashonMNIST 模型在$\varepsion \ approx 10美元上。 我们的工作为缩小私人和非私人深层基因模型之间的差距提供了简单又强大的基础。