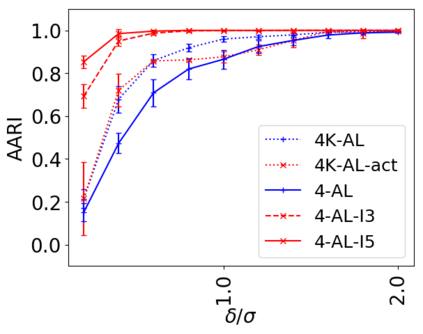
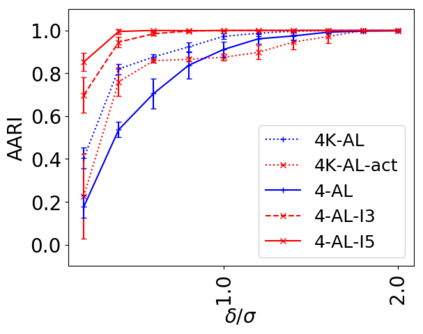
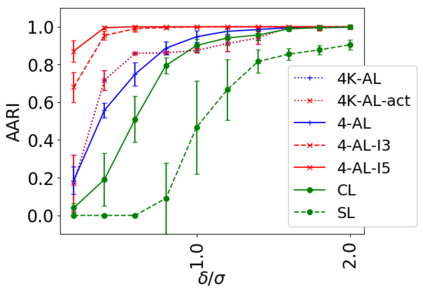
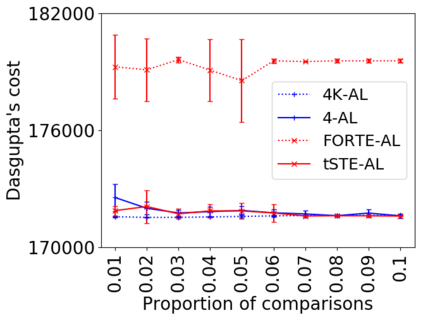
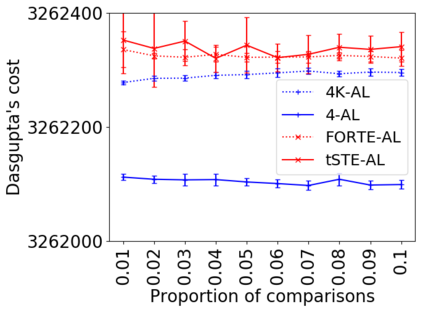
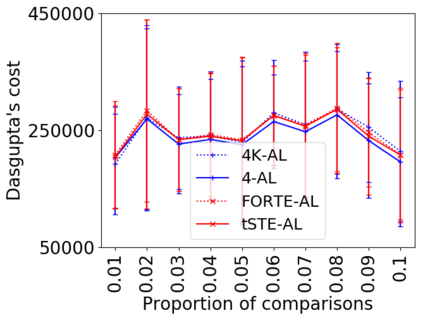
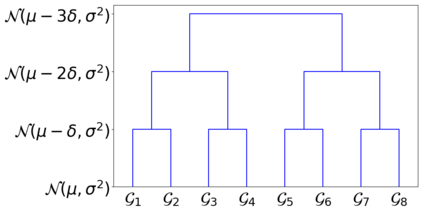
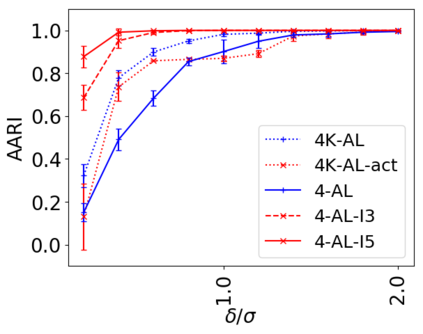
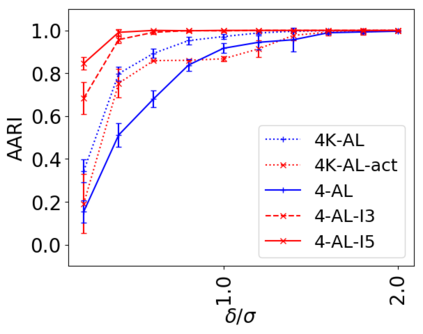
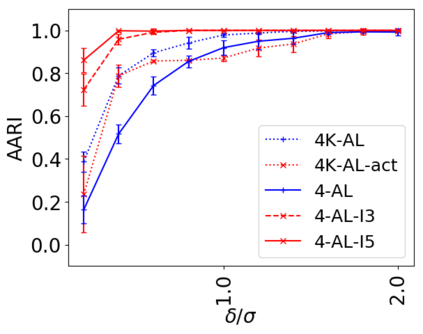
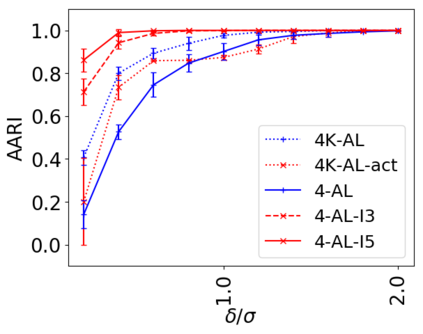
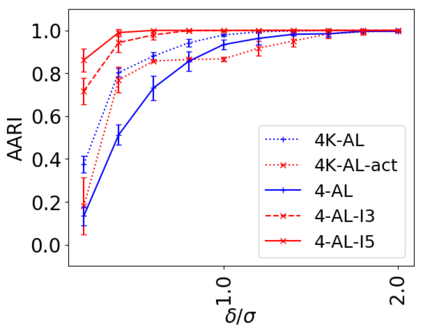
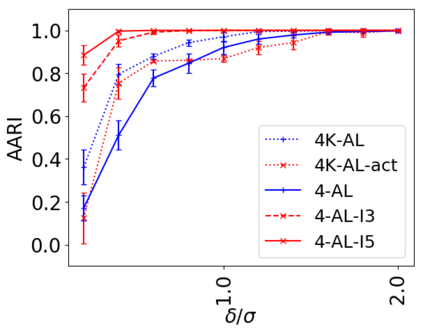
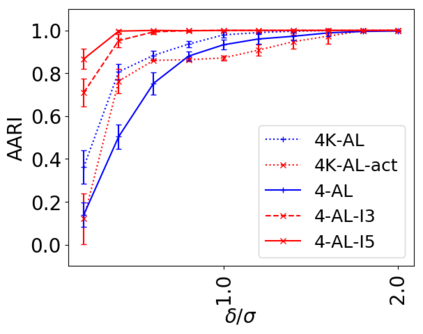
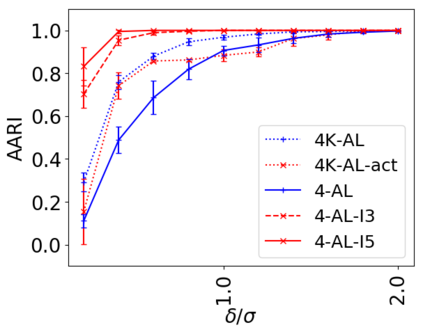
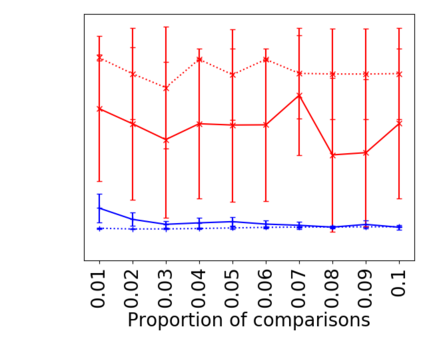
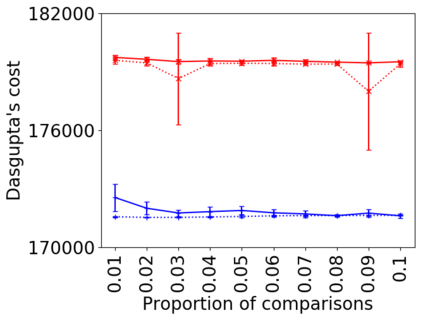
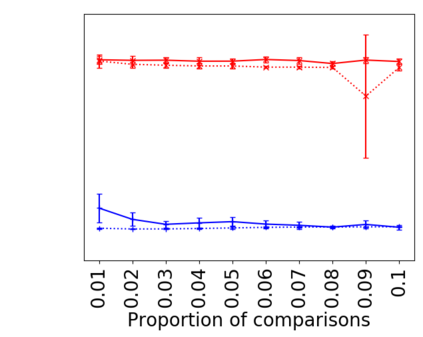
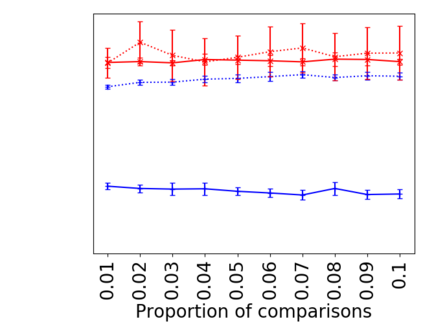
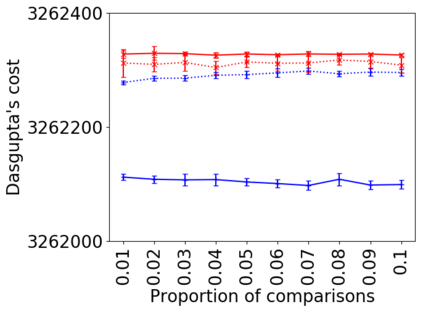
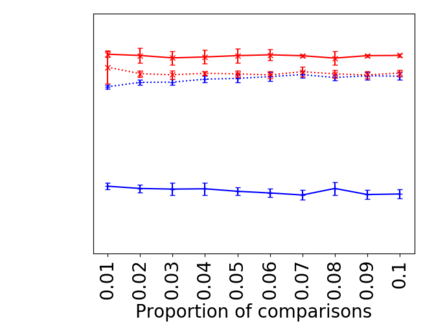
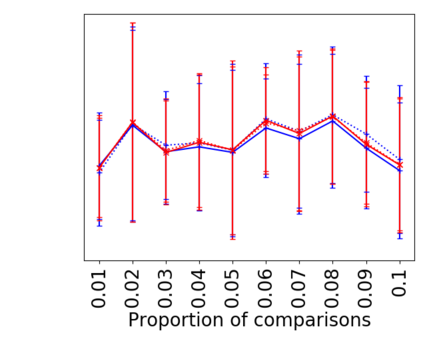
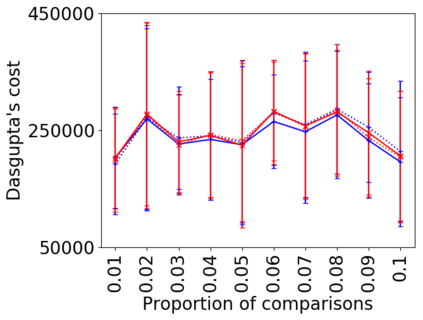
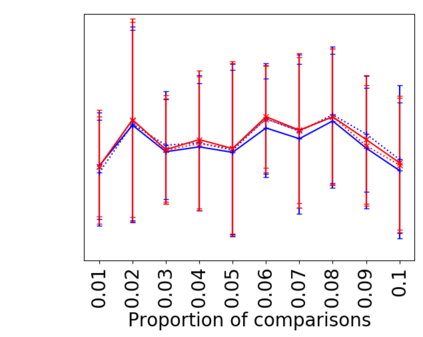
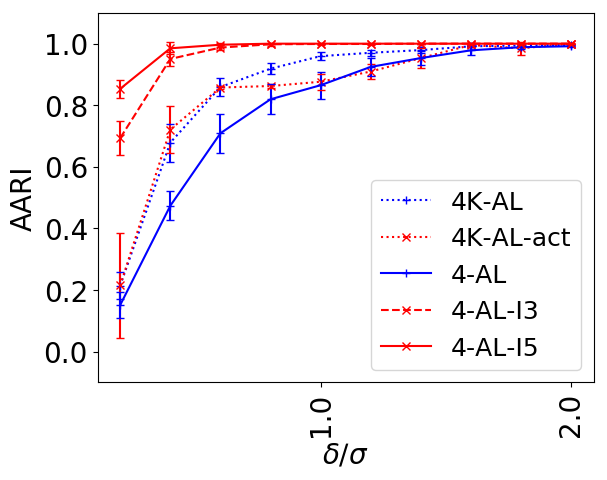
We address the classical problem of hierarchical clustering, but in a framework where one does not have access to a representation of the objects or their pairwise similarities. Instead, we assume that only a set of comparisons between objects is available, that is, statements of the form "objects $i$ and $j$ are more similar than objects $k$ and $l$." Such a scenario is commonly encountered in crowdsourcing applications. The focus of this work is to develop comparison-based hierarchical clustering algorithms that do not rely on the principles of ordinal embedding. We show that single and complete linkage are inherently comparison-based and we develop variants of average linkage. We provide statistical guarantees for the different methods under a planted hierarchical partition model. We also empirically demonstrate the performance of the proposed approaches on several datasets.
翻译:我们处理的是典型的等级分类问题,但是在这样一个框架内,人们无法获得物体的表示或其相近之处。相反,我们假设,只有对物体的一组比较,即“美元和美元与美元更类似”的表单。这种假设在众包应用中常见。这项工作的重点是开发基于比较的等级分类算法,这种算法不依赖星盘嵌入原则。我们表明,单一和完整的联系本质上是比较的,我们开发了平均联系的变体。我们为种植等级分割模式下的不同方法提供统计保障。我们还从经验上展示了若干数据集的拟议方法的绩效。