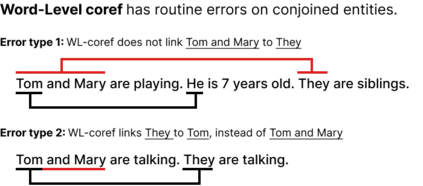
State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at https://github.com/KarelDO/wl-coref.
翻译:暂无翻译