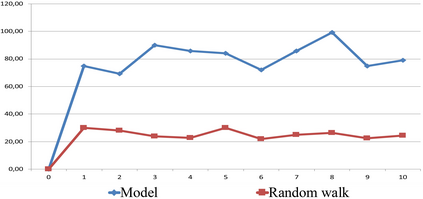
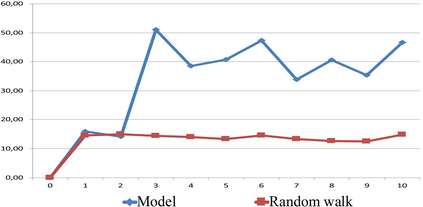
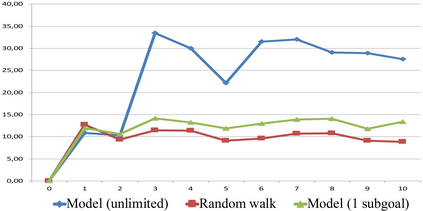
We propose a novel Reinforcement Learning model for discrete environments, which is inherently interpretable and supports the discovery of deep subgoal hierarchies. In the model, an agent learns information about environment in the form of probabilistic rules, while policies for (sub)goals are learned as combinations thereof. No reward function is required for learning; an agent only needs to be given a primary goal to achieve. Subgoals of a goal G from the hierarchy are computed as descriptions of states, which if previously achieved increase the total efficiency of the available policies for G. These state descriptions are introduced as new sensor predicates into the rule language of the agent, which allows for sensing important intermediate states and for updating environment rules and policies accordingly.
翻译:我们建议为离散的环境建立一个新型的强化学习模式,这种模式在本质上是可以解释的,并支持发现深小目标等级。在模式中,代理人以概率规则的形式学习有关环境的信息,而(子)目标的政策则作为组合学习。学习不需要奖励功能;只需要给代理人一个首要目标即可实现。从等级结构中得出的目标G的次级目标作为国家描述计算,如果以前达到,就会提高G现有政策的总效率。这些状态描述被作为新的感应层引入该代理人的规则语言,从而可以感测重要的中间国家,并据此更新环境规则和政策。