
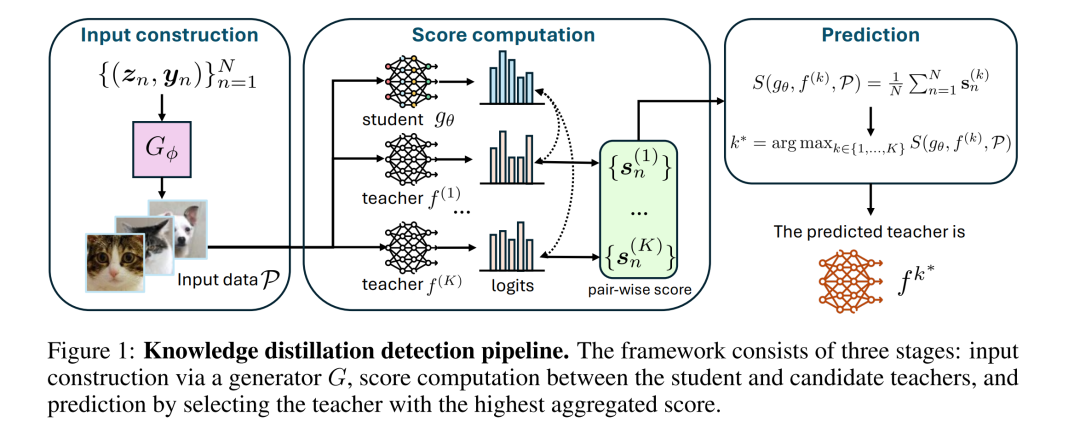
我们提出了知识蒸馏检测这一新任务,其目标是在一种实际场景下判断某个学生模型是否由给定教师模型蒸馏而来。在该场景中,研究者仅能访问学生模型的权重以及教师模型的 API。该问题的提出源于人们对模型来源(provenance)以及通过蒸馏进行未授权复制的担忧日益增加。 为解决这一任务,我们提出了一种与模型无关的检测框架,该框架结合了无数据输入合成与统计得分计算方法来实现蒸馏检测。该方法同时适用于分类模型和生成模型。 在图像分类与文本生成图像任务的多种架构上进行的实验表明,我们的方法在检测准确率上显著超越最强基线:在 CIFAR-10 上提升了 59.6%,在 ImageNet 上提升了 71.2%,在文本生成图像任务上提升了 20.0%。我们的代码已开源,链接为:https://github.com/shqii1j/distillation_detection。
成为VIP会员查看完整内容
相关内容

神经信息处理系统年会(Annual Conference on Neural Information Processing Systems)的目的是促进有关神经信息处理系统生物学,技术,数学和理论方面的研究交流。核心重点是在同行会议上介绍和讨论的同行评审新颖研究,以及各自领域的领导人邀请的演讲。在周日的世博会上,我们的顶级行业赞助商将就具有学术意义的主题进行讲座,小组讨论,演示和研讨会。星期一是教程,涵盖了当前的问询,亲和力小组会议以及开幕式演讲和招待会的广泛背景。一般会议在星期二至星期四举行,包括演讲,海报和示范。
官网地址:http://dblp.uni-trier.de/db/conf/nips/
Arxiv
219+阅读 · 2023年4月7日
Arxiv
84+阅读 · 2023年4月4日
Arxiv
150+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
219+阅读 · 2023年4月7日
Arxiv
84+阅读 · 2023年4月4日
Arxiv
150+阅读 · 2023年3月29日
Arxiv
84+阅读 · 2023年3月21日