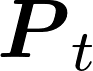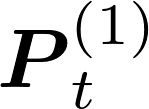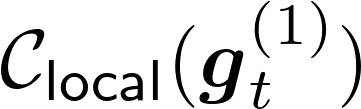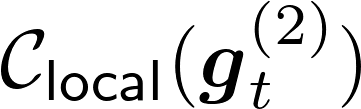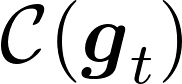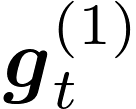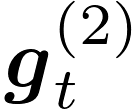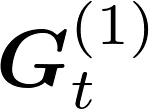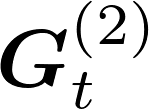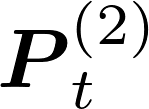Communication remains a central bottleneck in large-scale distributed machine learning, and gradient sparsification has emerged as a promising strategy to alleviate this challenge. However, existing gradient compressors face notable limitations: Rand-$K$\ discards structural information and performs poorly in practice, while Top-$K$\ preserves informative entries but loses the contraction property and requires costly All-Gather operations. In this paper, we propose ARC-Top-$K$, an {All-Reduce}-Compatible Top-$K$ compressor that aligns sparsity patterns across nodes using a lightweight sketch of the gradient, enabling index-free All-Reduce while preserving globally significant information. ARC-Top-$K$\ is provably contractive and, when combined with momentum error feedback (EF21M), achieves linear speedup and sharper convergence rates than the original EF21M under standard assumptions. Empirically, ARC-Top-$K$\ matches the accuracy of Top-$K$\ while reducing wall-clock training time by up to 60.7\%, offering an efficient and scalable solution that combines the robustness of Rand-$K$\ with the strong performance of Top-$K$.
翻译:暂无翻译