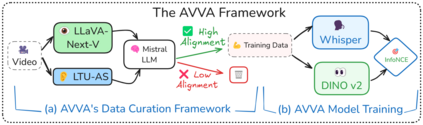
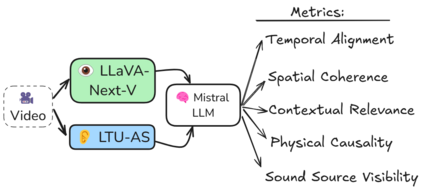
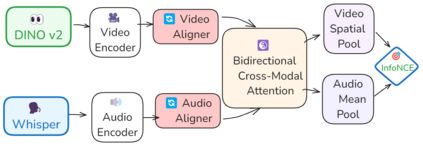
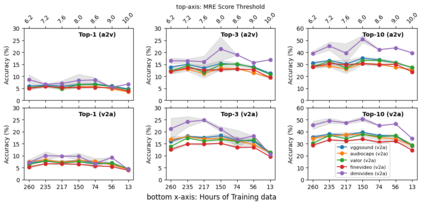
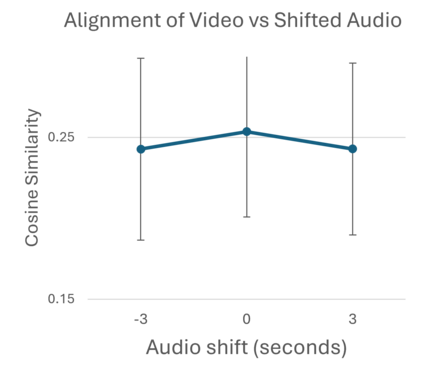
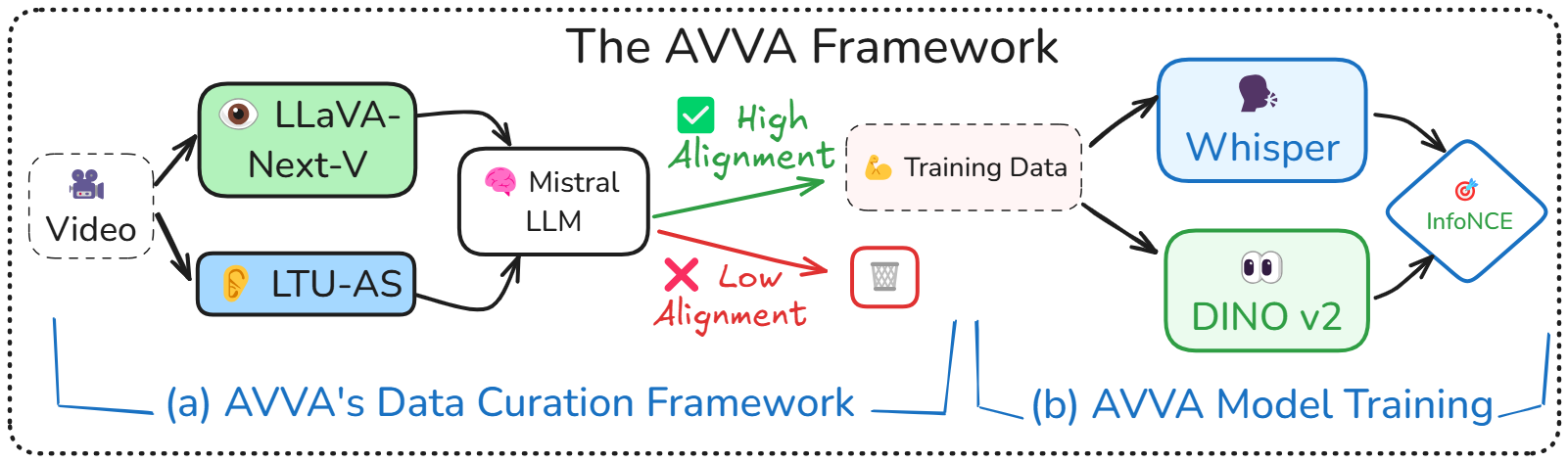
Integrating audio and visual data for training multimodal foundational models remains a challenge. The Audio-Video Vector Alignment (AVVA) framework addresses this by considering AV scene alignment beyond mere temporal synchronization, and leveraging Large Language Models (LLMs) for data curation. AVVA implements a scoring mechanism for selecting aligned training data segments. It integrates Whisper, a speech-based foundation model, for audio and DINOv2 for video analysis in a dual-encoder structure with contrastive learning on AV pairs. Evaluations on AudioCaps, VALOR, and VGGSound demonstrate the effectiveness of the proposed model architecture and data curation approach. AVVA achieves a significant improvement in top-k accuracies for video-to-audio retrieval on all datasets compared to DenseAV, while using only 192 hrs of curated training data. Furthermore, an ablation study indicates that the data curation process effectively trades data quality for data quantity, yielding increases in top-k retrieval accuracies on AudioCaps, VALOR, and VGGSound, compared to training on the full spectrum of uncurated data.
翻译:暂无翻译