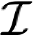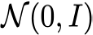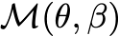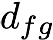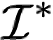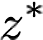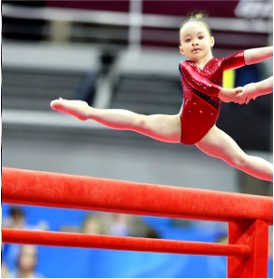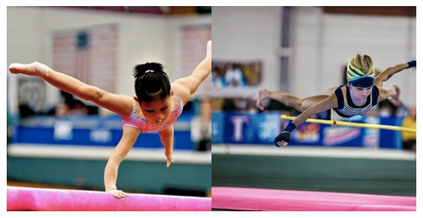Recent text-to-image generative models have exhibited remarkable abilities in generating high-fidelity and photo-realistic images. However, despite the visually impressive results, these models often struggle to preserve plausible human structure in the generations. Due to this reason, while generative models have shown promising results in aiding downstream image recognition tasks by generating large volumes of synthetic data, they remain infeasible for improving downstream human pose perception and understanding. In this work, we propose Diffusion model with Human Pose Correction (Diffusion HPC), a text-conditioned method that generates photo-realistic images with plausible posed humans by injecting prior knowledge about human body structure. We show that Diffusion HPC effectively improves the realism of human generations. Furthermore, as the generations are accompanied by 3D meshes that serve as ground truths, Diffusion HPC's generated image-mesh pairs are well-suited for downstream human mesh recovery task, where a shortage of 3D training data has long been an issue.
翻译:近期的文字到图像模型在产生高贞洁和摄影现实图像方面表现出了非凡的能力。然而,尽管取得了令人印象深刻的成果,这些模型往往在几代人中为维护貌似合理的人类结构而挣扎。由于这一原因,尽管基因模型在通过产生大量合成数据协助下游图像识别任务方面显示了令人乐观的结果,但它们仍然无法改善下游人类对人构成的感知和理解。在这项工作中,我们提出了与人类软体校正(Difmulation HPC)相融合模型(Difmage-mesh pats)一起的传播模型,这是一种有文字限制的方法,通过注入人类身体结构的先前知识,产生出貌似真实的人类形象图像。我们表明,Difmilling HPC有效地改进了人类几代人的现实主义。此外,随着三代代代相伴随的三代代相配方作为地面真理,Difmulation HPC所生成的图像-mesh 配对对于下游人的恢复任务来说非常适合,在其中长期存在问题的3D培训数据短缺的问题。</s>