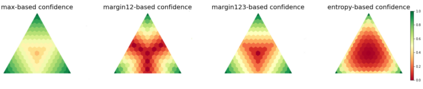
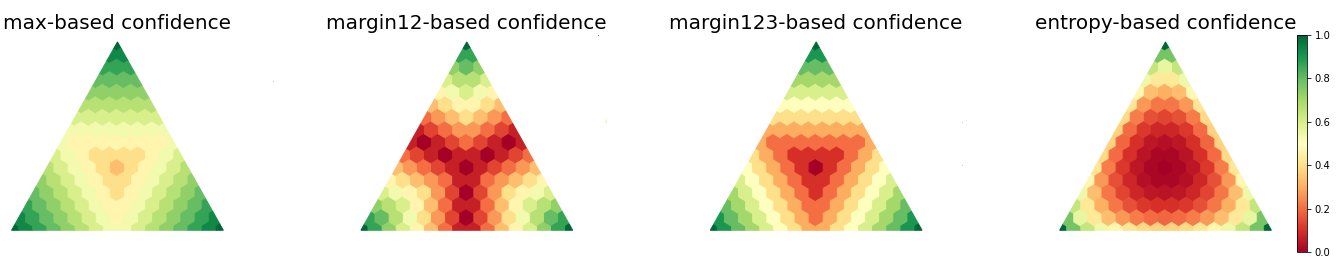
An important component in deploying machine learning (ML) in safety-critic applications is having a reliable measure of confidence in the ML model's predictions. For a classifier $f$ producing a probability vector $f(x)$ over the candidate classes, the confidence is typically taken to be $\max_i f(x)_i$. This approach is potentially limited, as it disregards the rest of the probability vector. In this work, we derive several confidence measures that depend on information beyond the maximum score, such as margin-based and entropy-based measures, and empirically evaluate their usefulness, focusing on NLP tasks with distribution shifts and Transformer-based models. We show that when models are evaluated on the out-of-distribution data ``out of the box'', using only the maximum score to inform the confidence measure is highly suboptimal. In the post-processing regime (where the scores of $f$ can be improved using additional in-distribution held-out data), this remains true, albeit less significant. Overall, our results suggest that entropy-based confidence is a surprisingly useful measure.
翻译:在安全级应用中部署机器学习(ML)的一个重要部分是对ML模型预测的可靠信任度。 对于在候选类中产生概率矢量(f(x)美元)的分类员来说,信任度一般为$max_i f(x)_i美元。这种方法可能有限,因为它忽略了概率矢量的其余部分。在这项工作中,我们获得了若干信任度的尺度,这些尺度取决于最高分以外的信息,例如基于边距和基于英特普的测量,以及实证地评估其效用,重点是以分布变换和基于变异器模型的NLP任务。我们显示,当对模型评价“盒子外”分配数据时,只使用最大分数来告知信任度是极不理想的。在后处理制度中(在后处理制度中,如果使用额外分布的搁置数据可以改进美元分数,这仍然是真实的,尽管不太重要。总体而言,我们的结果表明,基于英特普的信任度是一个令人惊讶的有用尺度。