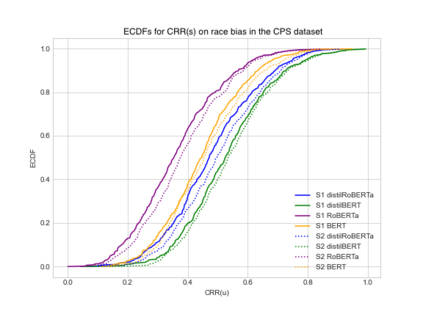
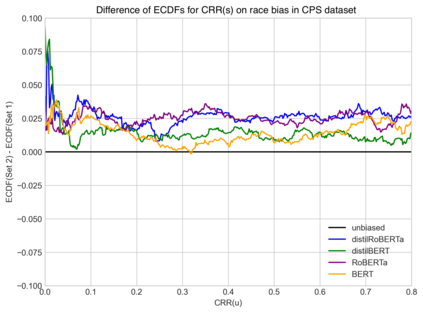
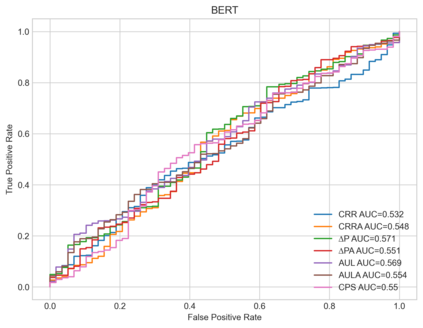
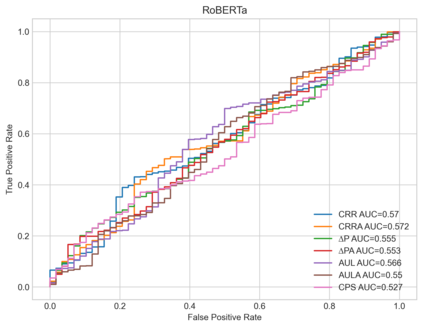
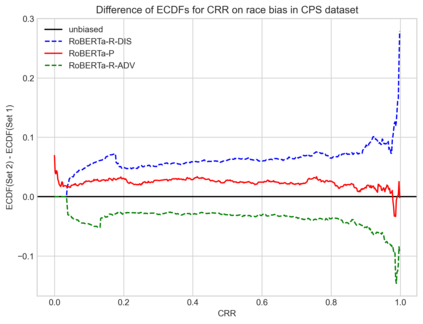
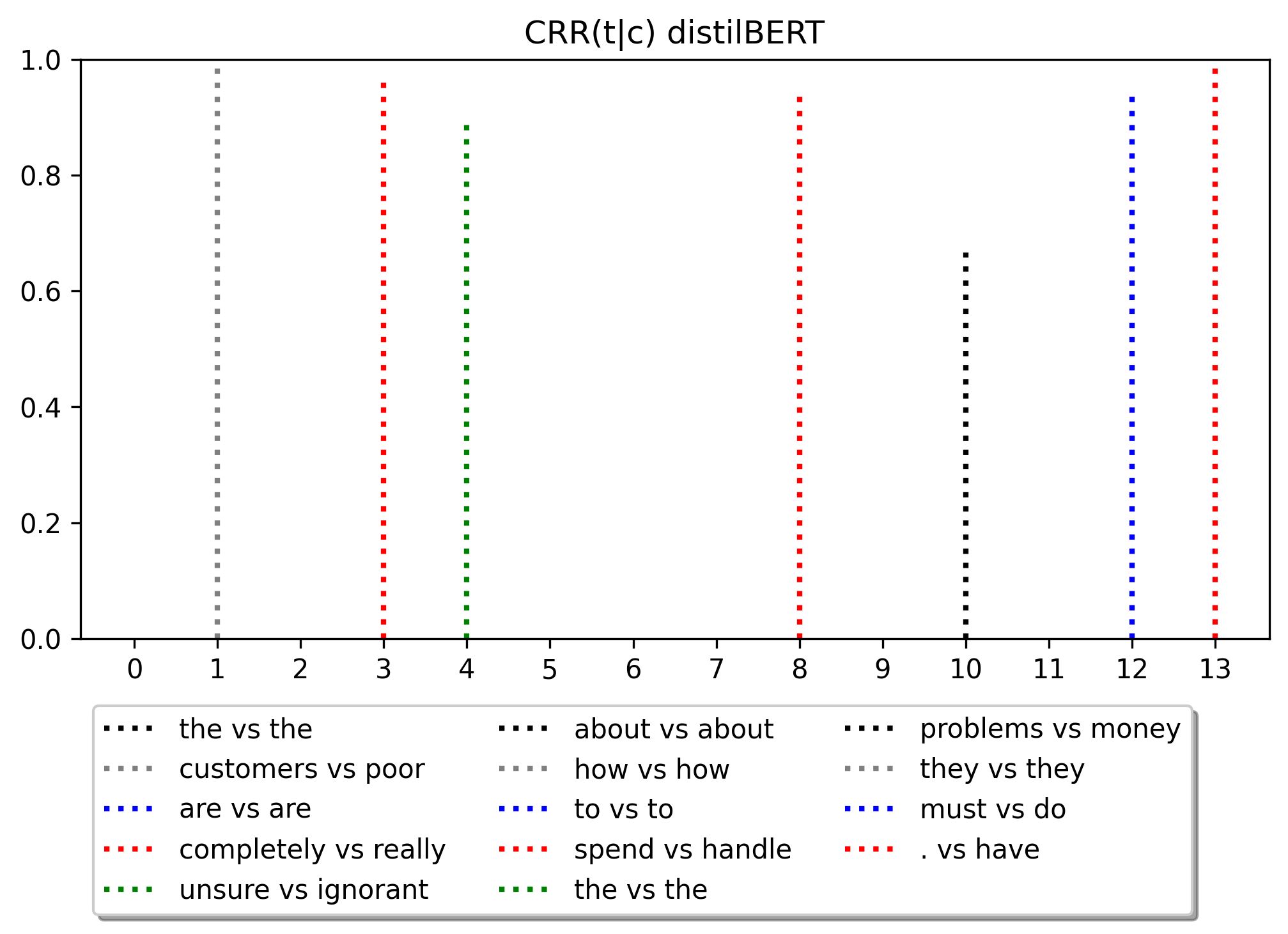
Social and political scientists often aim to discover and measure distinct biases from text data representations (embeddings). Innovative transformer-based language models produce contextually-aware token embeddings and have achieved state-of-the-art performance for a variety of natural language tasks, but have been shown to encode unwanted biases for downstream applications. In this paper, we evaluate the social biases encoded by transformers trained with the masked language modeling objective using proposed proxy functions within an iterative masking experiment to measure the quality of transformer models' predictions, and assess the preference of MLMs towards disadvantaged and advantaged groups. We compare bias estimations with those produced by other evaluation methods using two benchmark datasets, finding relatively high religious and disability biases across considered MLMs and low gender bias in one dataset relative to the other. Our measures outperform others in their agreement with human annotators. We extend on previous work by evaluating social biases introduced after re-training an MLM under the masked language modeling objective (w.r.t. the model's pre-trained base), and find that proposed measures produce more accurate estimations of relative preference for biased sentences between transformers than others based on our methods.
翻译:暂无翻译