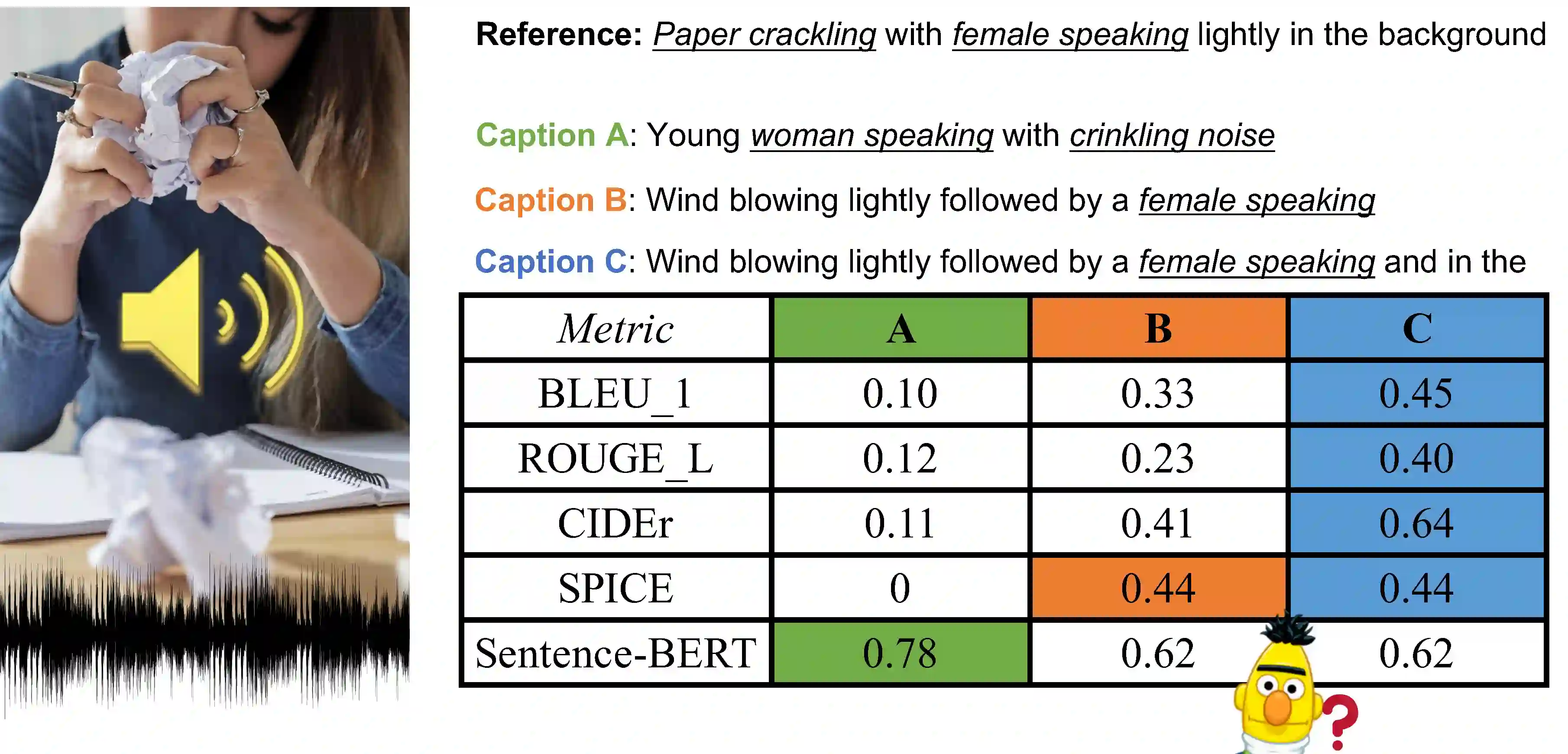
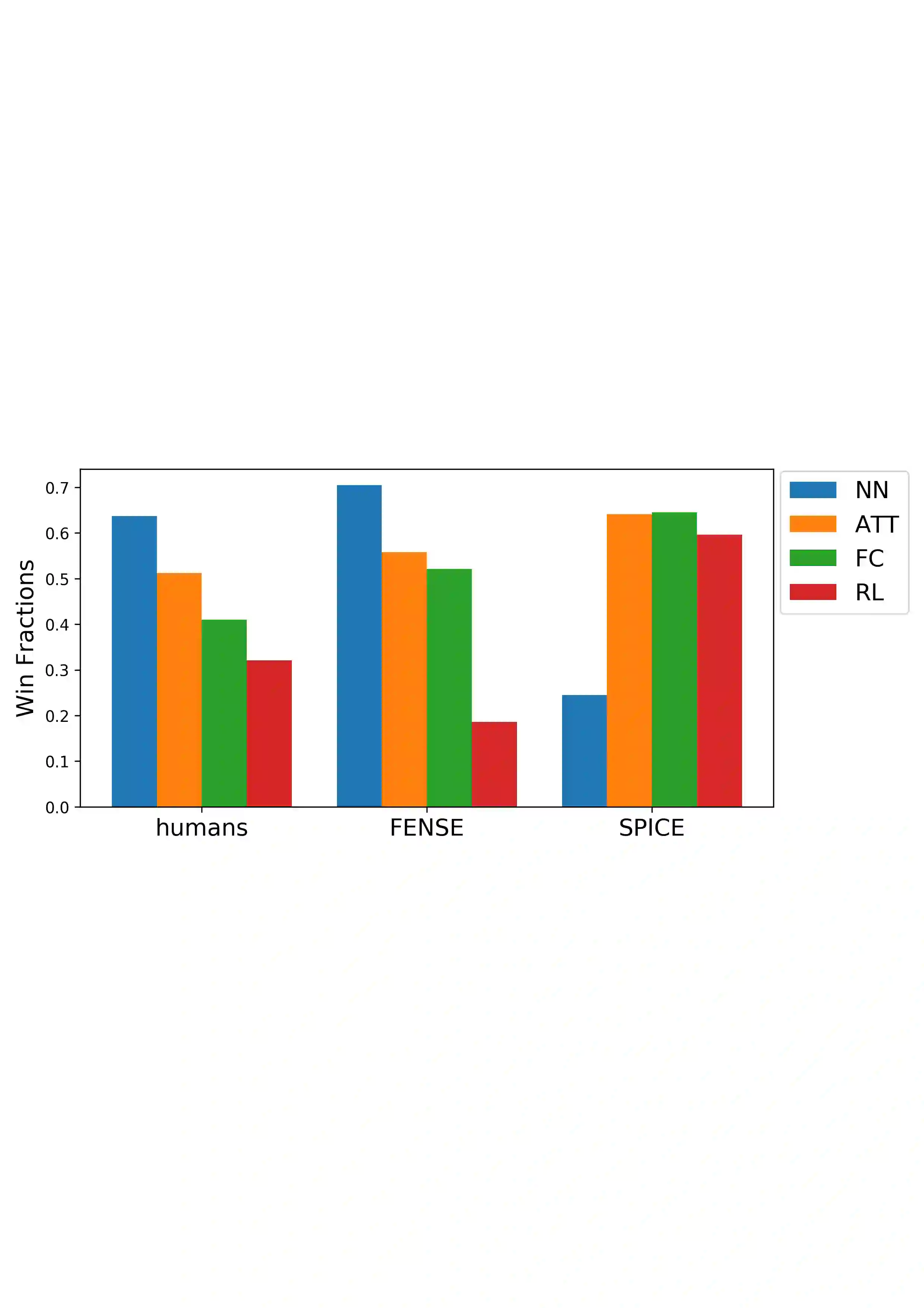
Automated audio captioning aims at generating textual descriptions for an audio clip. To evaluate the quality of generated audio captions, previous works directly adopt image captioning metrics like SPICE and CIDEr, without justifying their suitability in this new domain, which may mislead the development of advanced models. This problem is still unstudied due to the lack of human judgment datasets on caption quality. Therefore, we firstly construct two evaluation benchmarks, AudioCaps-Eval and Clotho-Eval. They are established with pairwise comparison instead of absolute rating to achieve better inter-annotator agreement. Current metrics are found in poor correlation with human annotations on these datasets. To overcome their limitations, we propose a metric named FENSE, where we combine the strength of Sentence-BERT in capturing similarity, and a novel Error Detector to penalize erroneous sentences for robustness. On the newly established benchmarks, FENSE outperforms current metrics by 14-25% accuracy. Code, data and web demo available at: https://github.com/blmoistawinde/fense
翻译:自动音频字幕的目的是为音频剪辑制作文字描述。 为了评估生成的音频字幕的质量,先前的作品直接采用像像SPICE和CIDEr这样的图像字幕量度,而没有说明它们是否适合这一新领域,这可能会误导先进模型的开发。由于在字幕质量方面缺乏人文判断数据集,这一问题仍未研究。因此,我们首先建立了两个评价基准,即AudioCaps-Eval和Clotho-Eval。它们是通过对等比较而不是绝对评级来建立的,以达成更好的跨咨询协议。目前的测量指标与这些数据集的人类说明关系不大。为了克服其局限性,我们提出了名为FENESE的衡量标准,其中我们结合了判决-BERT在获取相似性方面的实力,以及一个新的错误检测器,以惩罚错误的强度。在新建立的基准上,FENSE比当前测量标准高出14-25%的精确度。 代码、数据和网络演示可在以下网址上查到:https://github.com/blimoistridene/filedectione。