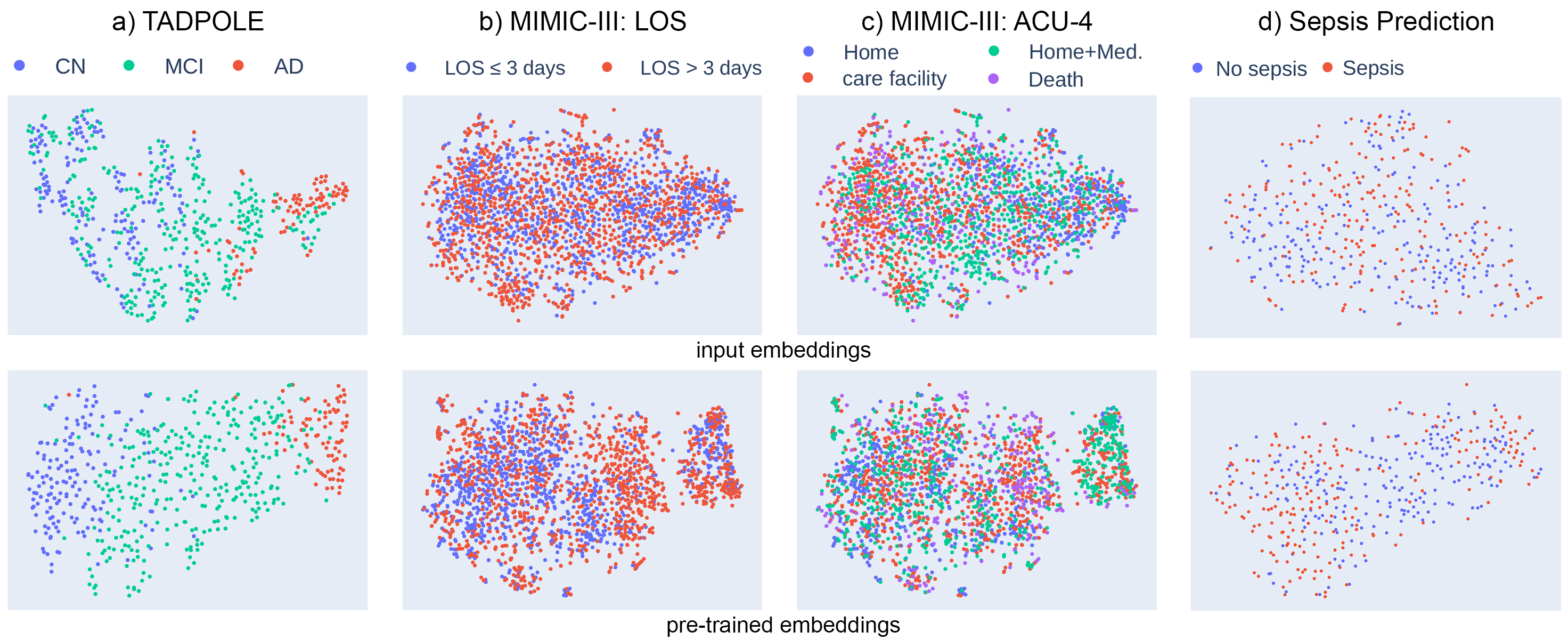
Pre-training has shown success in different areas of machine learning, such as Computer Vision, Natural Language Processing (NLP), and medical imaging. However, it has not been fully explored for clinical data analysis. An immense amount of clinical records are recorded, but still, data and labels can be scarce for data collected in small hospitals or dealing with rare diseases. In such scenarios, pre-training on a larger set of unlabelled clinical data could improve performance. In this paper, we propose novel unsupervised pre-training techniques designed for heterogeneous, multi-modal clinical data for patient outcome prediction inspired by masked language modeling (MLM), by leveraging graph deep learning over population graphs. To this end, we further propose a graph-transformer-based network, designed to handle heterogeneous clinical data. By combining masking-based pre-training with a transformer-based network, we translate the success of masking-based pre-training in other domains to heterogeneous clinical data. We show the benefit of our pre-training method in a self-supervised and a transfer learning setting, utilizing three medical datasets TADPOLE, MIMIC-III, and a Sepsis Prediction Dataset. We find that our proposed pre-training methods help in modeling the data at a patient and population level and improve performance in different fine-tuning tasks on all datasets.
翻译:培训前在计算机视野、自然语言处理和医学成像等不同机械学习领域表现出成功。然而,没有为临床数据分析进行充分的探索。记录了大量临床记录,但对于在小医院或处理罕见疾病收集的数据来说,数据和标签仍然稀少。在这种情形下,关于更大一套无标签临床数据的预先培训可以提高性能。在本文件中,我们提出新的未经监督的训练前技术,这些技术是为多种不同的、多种模式的临床数据设计的,用于在蒙面语言模型(MLM)的启发下对病人结果进行预测的预测。为此,我们进一步提出一个基于图表的变异网络,旨在处理多种多样的临床数据。通过将基于遮罩的预先培训与基于变异器的网络结合起来,我们把在其他领域进行基于掩蔽的预先培训的成功转化为多样化的临床数据。我们用三种医学数据集在TADPOLE前、MIMI-III和Simillis的学习环境上,利用三种医学数据集,利用我们在不同的人口调整模型和测试中找到不同的数据。