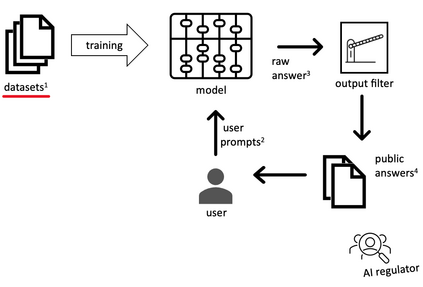
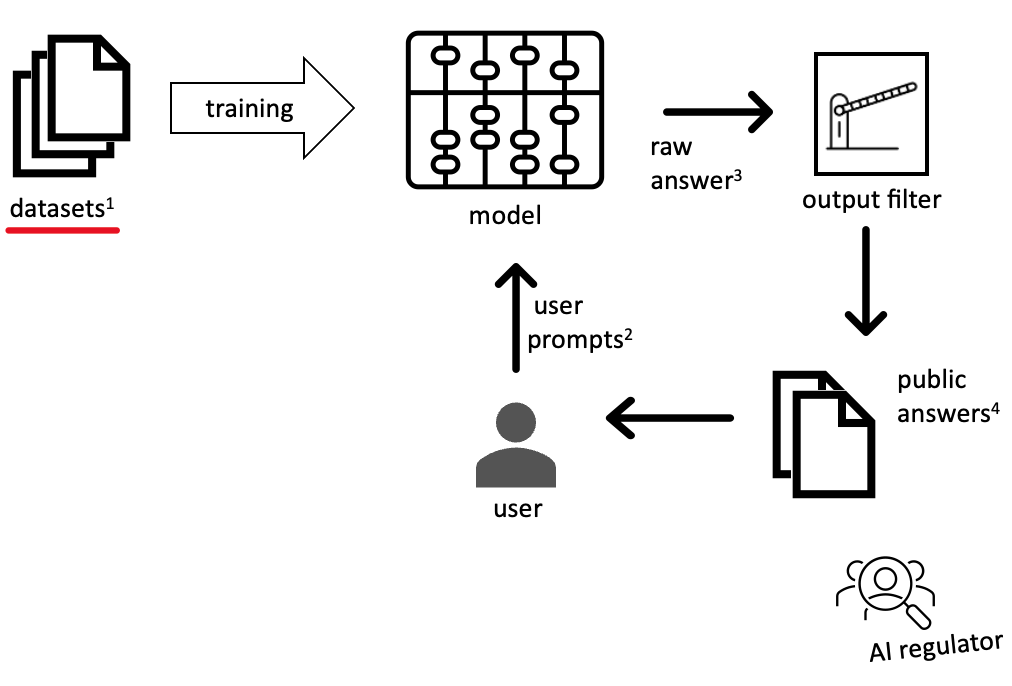
This paper explores how AI-owners can develop safeguards for AI-generated content by drawing from established codes of conduct and ethical standards in other content-creation industries. It delves into the current state of ethical awareness on Large Language Models (LLMs). By dissecting the mechanism of content generation by LLMs, four key areas (upstream/downstream and at user prompt/answer), where safeguards could be effectively applied, are identified. A comparative analysis of these four areas follows and includes an evaluation of the existing ethical safeguards in terms of cost, effectiveness, and alignment with established industry practices. The paper's key argument is that existing IT-related ethical codes, while adequate for traditional IT engineering, are inadequate for the challenges posed by LLM-based content generation. Drawing from established practices within journalism, we propose potential standards for businesses involved in distributing and selling LLM-generated content. Finally, potential conflicts of interest between dataset curation at upstream and ethical benchmarking downstream are highlighted to underscore the need for a broader evaluation beyond mere output. This study prompts a nuanced conversation around ethical implications in this rapidly evolving field of content generation.
翻译:暂无翻译