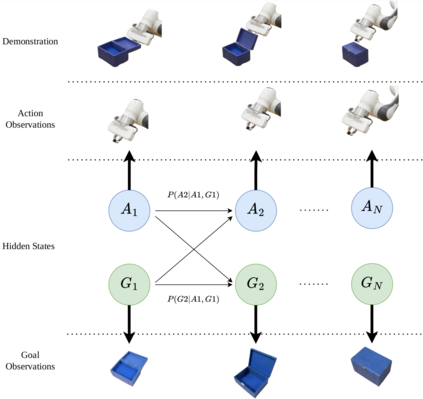
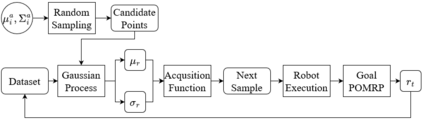
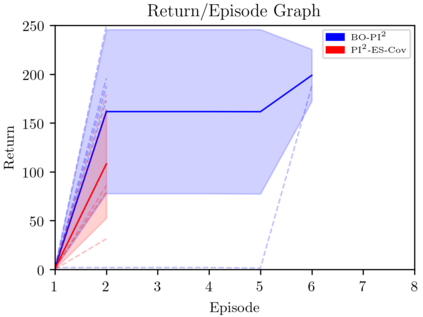
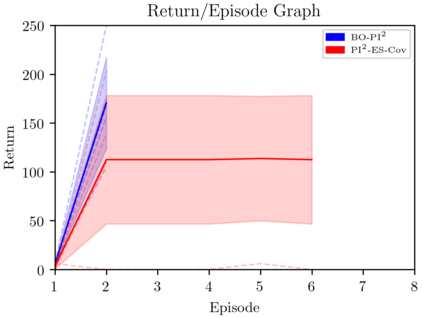
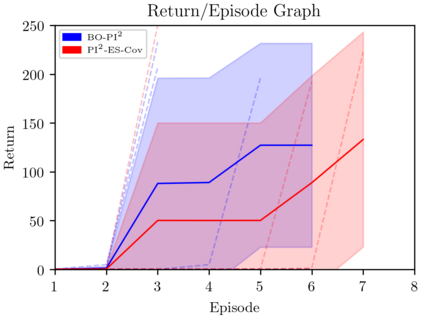
This paper introduces a novel Learning from Demonstration framework to learn robotic skills with keyframe demonstrations using a Dynamic Bayesian Network (DBN) and a Bayesian Optimized Policy Search approach to improve the learned skills. DBN learns the robot motion, perceptual change in the object of interest (aka skill sub-goals) and the relation between them. The rewards are also learned from the perceptual part of the DBN. The policy search part is a semiblack box algorithm, which we call BO-PI2 . It utilizes the action-perception relation to focus the high-level exploration, uses Gaussian Processes to model the expected-return and performs Upper Confidence Bound type low-level exploration for sampling the rollouts. BO-PI2 is compared against a stateof-the-art method on three different skills in a real robot setting with expert and naive user demonstrations. The results show that our approach successfully focuses the exploration on the failed sub-goals and the addition of reward-predictive exploration outperforms the state-of-the-art approach on cumulative reward, skill success, and termination time metrics.
翻译:本文介绍一个创新的示范学习框架,学习机器人技能,使用动态巴伊西亚网络(DBN)和巴伊西亚最佳政策搜索方法,利用关键框架演示学习机器人技能,提高学习技能。DBN学习机器人运动、兴趣对象(aka技能子目标)的观念变化以及两者之间的关系。奖励也从DBN的概念部分中学习。政策搜索部分是一个半黑盒算法,我们称之为BO-PI2。它利用行动-概念关系,将高级别探索的重点放在高斯进程上,利用高斯进程模拟预期回报和进行高信任型低级探索,以抽样展示推出。BO-PI2与在真正机器人环境中由专家进行和天真的用户演示的三种不同技能的先进方法相比较。结果显示,我们的方法成功地将探索重点放在失败的子目标上,并增加了奖赏前探索。它超越了在累积奖励、技能成功和终止时间指标方面采用的最新方法。