
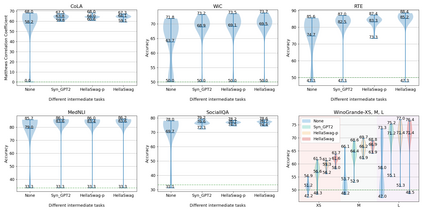
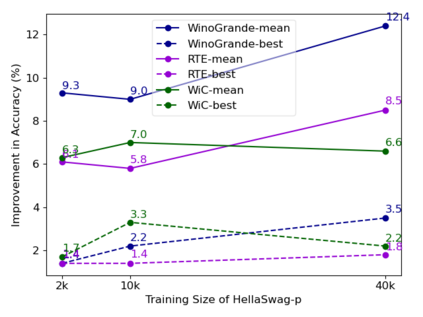
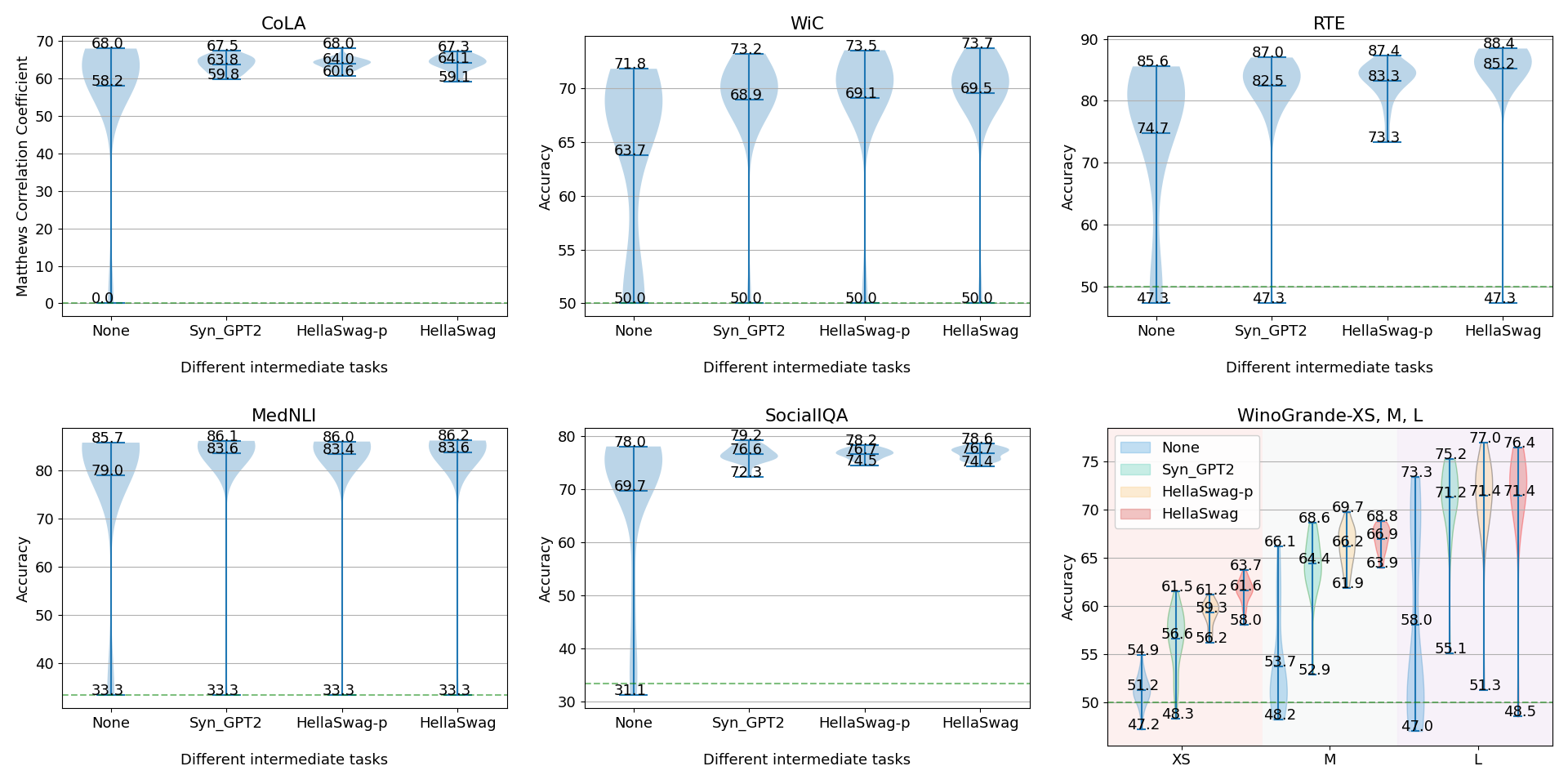
Supplementary Training on Intermediate Labeled-data Tasks (STILTs) is a widely applied technique, which first fine-tunes the pretrained language models on an intermediate task before on the target task of interest. While STILTs is able to further improve the performance of pretrained language models, it is still unclear why and when it works. Previous research shows that those intermediate tasks involving complex inference, such as commonsense reasoning, work especially well for RoBERTa. In this paper, we discover that the improvement from an intermediate task could be orthogonal to it containing reasoning or other complex skills -- a simple real-fake discrimination task synthesized by GPT2 can benefit diverse target tasks. We conduct extensive experiments to study the impact of different factors on STILTs. These findings suggest rethinking the role of intermediate fine-tuning in the STILTs pipeline.
翻译:关于中级标签数据任务的补充培训(STILTs)是一项广泛应用的技术,它首先将预先培训的语言模式微调成中间任务,然后进行中期任务;虽然STILTs能够进一步改进预先培训的语言模式的性能,但仍不清楚其原因和何时起作用;以前的研究表明,那些涉及复杂推论的中间任务,例如常识推理,尤其对RoBERTa特别有效;在本文中,我们发现,从中间任务中改进的内容可能与包含推理或其他复杂技能的中间任务相交替 -- -- 由GPT2综合的简单真实的歧视任务可以使不同的目标任务受益;我们进行了广泛的实验,研究不同因素对STILTs的影响;这些研究结果表明,重新考虑了中度微调在STLTs管道中的作用。

相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

