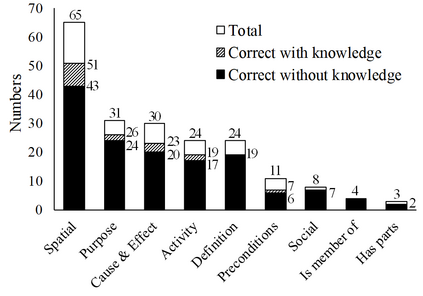
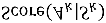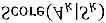A fundamental ability of humans is to utilize commonsense knowledge in language understanding and question answering. In recent years, many knowledge-enhanced Commonsense Question Answering (CQA) approaches have been proposed. However, it remains unclear: (1) How far can we get by exploiting external knowledge for CQA? (2) How much potential of knowledge has been exploited in current CQA models? (3) Which are the most promising directions for future CQA? To answer these questions, we benchmark knowledge-enhanced CQA by conducting extensive experiments on multiple standard CQA datasets using a simple and effective knowledge-to-text transformation framework. Experiments show that: (1) Our knowledge-to-text framework is effective and achieves state-of-the-art performance on CommonsenseQA dataset, providing a simple and strong knowledge-enhanced baseline for CQA; (2) The potential of knowledge is still far from being fully exploited in CQA -- there is a significant performance gap from current models to our models with golden knowledge; and (3) Context-sensitive knowledge selection, heterogeneous knowledge exploitation, and commonsense-rich language models are promising CQA directions.
翻译:人类的基本能力是在语言理解和回答问题时利用常识知识; 近年来,提出了许多加强知识的常识问题解答(CQA)方法,但尚不清楚:(1) 利用常识问题解答(CQA)的外部知识,我们能得到多大的外部知识? (2) 在目前的CQA模型中,知识的潜力有多少被利用?(3) 知识的潜力是未来CQA最有希望的方向?为了回答这些问题,我们用简单有效的知识到文字转换框架,对多标准CQA数据集进行广泛的试验,以此为增强知识的CQA基准。实验表明:(1) 我们的知识到文字框架是有效的,在常识质询(CQA)数据集上实现了最先进的业绩,为CQA提供了一个简单和强有力的知识强化基线;(2) 知识的潜力在CQA中仍然远远没有得到充分利用 -- -- 从目前的模式到我们具有黄金知识的模型,在业绩上存在着巨大的差距;(3) 环境敏感知识选择、千变式知识的利用和普通的QEri值语言模式是很有希望的。