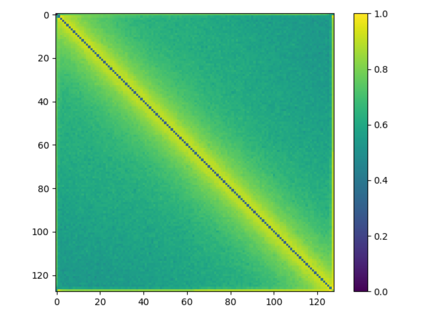
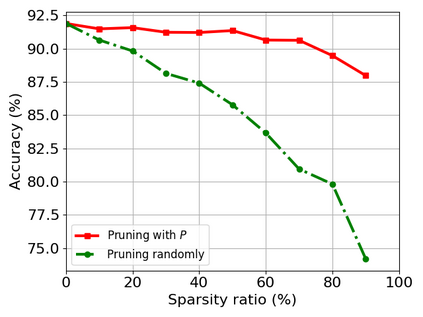
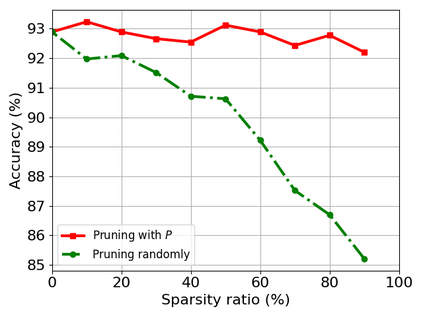
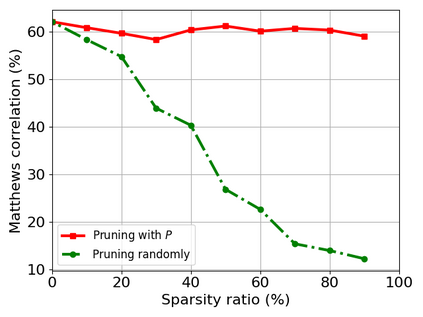
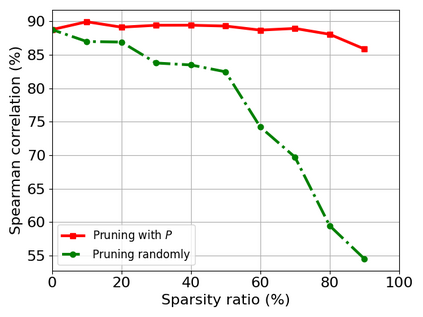
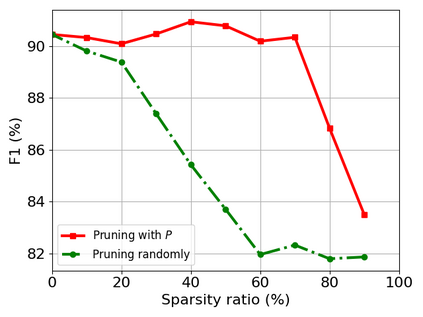
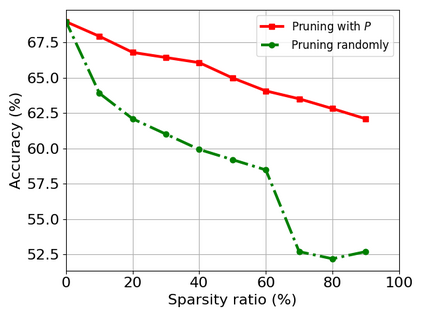
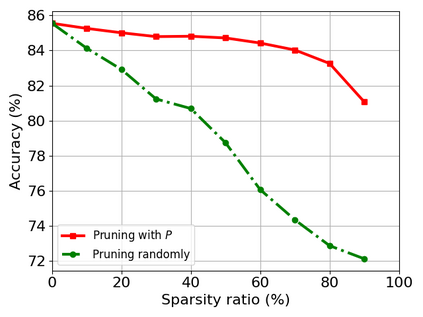
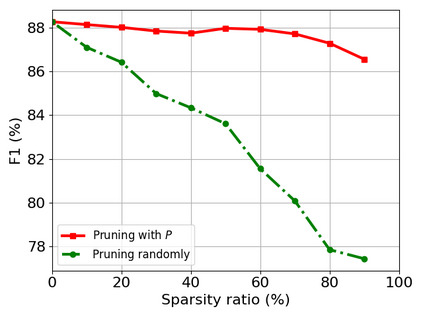
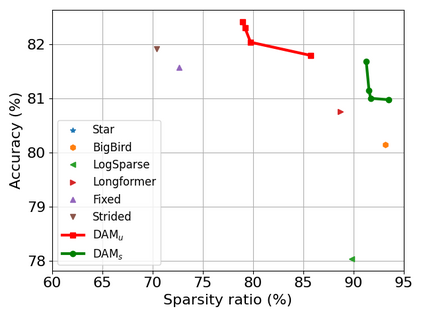
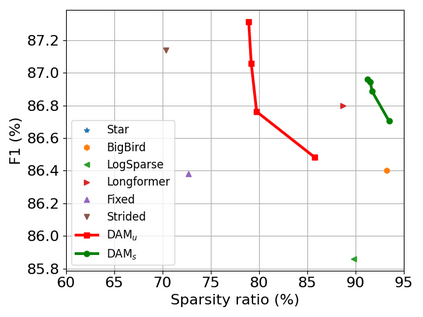
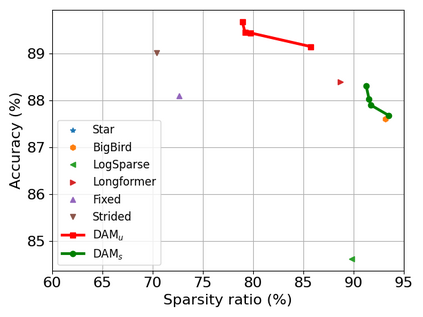
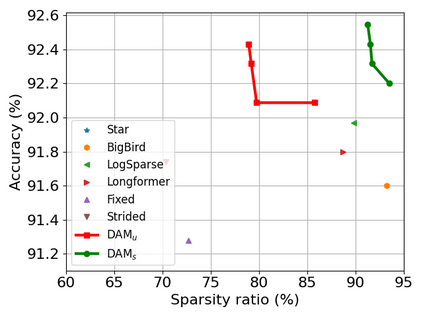
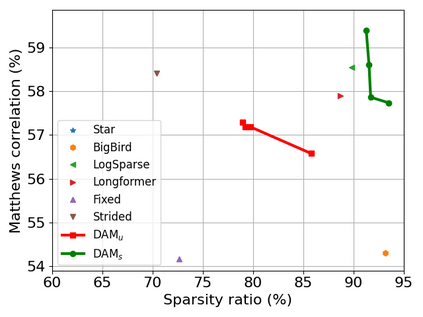
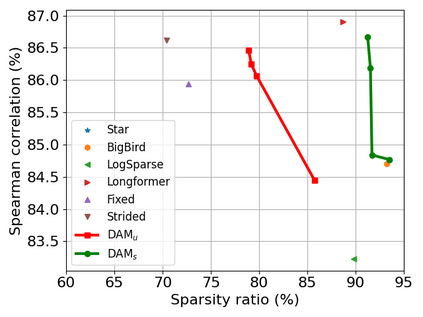
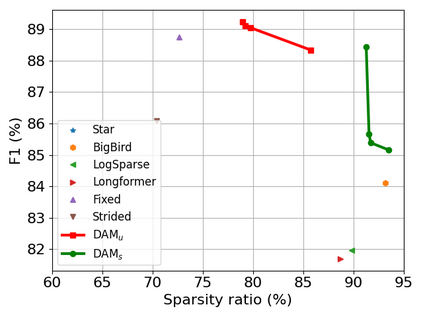
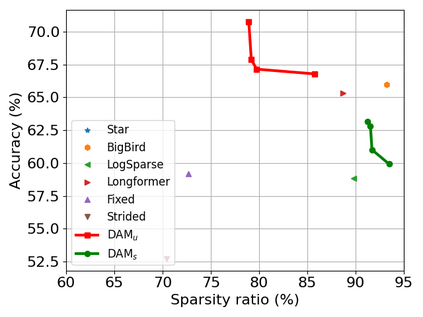
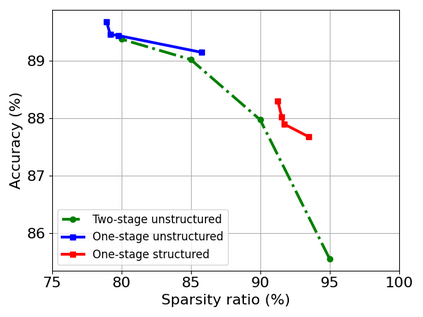
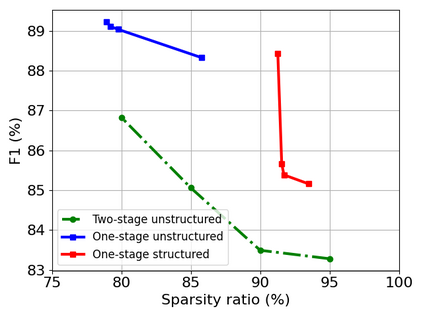
Transformer-based models are popular for natural language processing (NLP) tasks due to its powerful capacity. As the core component, self-attention module has aroused widespread interests. Attention map visualization of a pre-trained model is one direct method for understanding self-attention mechanism and some common patterns are observed in visualization. Based on these patterns, a series of efficient transformers are proposed with corresponding sparse attention masks. Besides above empirical results, universal approximability of Transformer-based models is also discovered from a theoretical perspective. However, above understanding and analysis of self-attention is based on a pre-trained model. To rethink the importance analysis in self-attention, we delve into dynamics of attention matrix importance during pre-training. One of surprising results is that the diagonal elements in the attention map are the most unimportant compared with other attention positions and we also provide a proof to show these elements can be removed without damaging the model performance. Furthermore, we propose a Differentiable Attention Mask (DAM) algorithm, which can be also applied in guidance of SparseBERT design further. The extensive experiments verify our interesting findings and illustrate the effect of our proposed algorithm.
翻译:基于变压器的模型因其强大的能力而受自然语言处理任务(NLP)的欢迎。作为核心组成部分,自我注意模块引起了广泛的兴趣。注意前训练模型的可视化是了解自我注意机制的直接方法,在视觉化中也观察到一些共同的模式。根据这些模式,提出了一系列高效变压器,并配有相应的微弱关注面罩。除了经验结果之外,还从理论角度发现了基于变压器的模型的通用近似性。但是,在理解和分析自我注意的基础上,有一个预先训练的模型。为了重新思考自我注意的重要性分析,我们在训练前将注意力矩阵的动态分解为重要。一个令人惊讶的结果是,与其它关注位置相比,注意图中的对角要素最为不重要,我们还提供证据,表明这些要素可以删除,但不会损害模型性能。此外,我们提议一种差异化的注意蒙像(DAM)算法,也可以进一步应用于对SprarkBERT设计的指导。广泛的实验证实了我们提出的算法的有趣结果和效果。