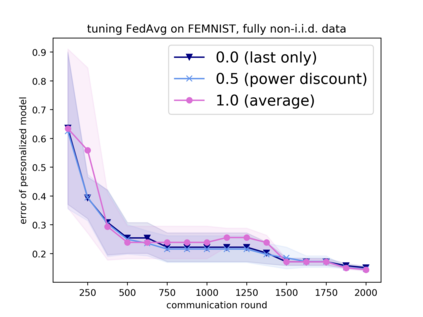
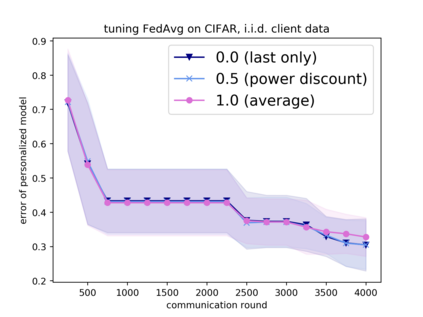
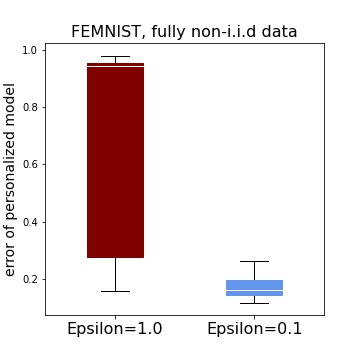
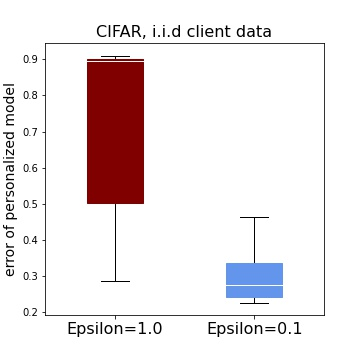
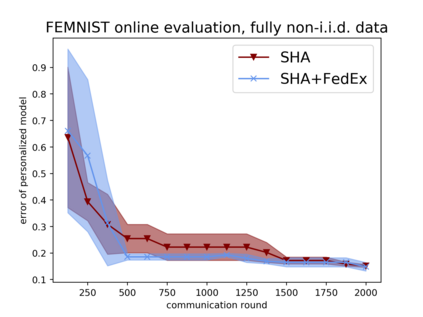
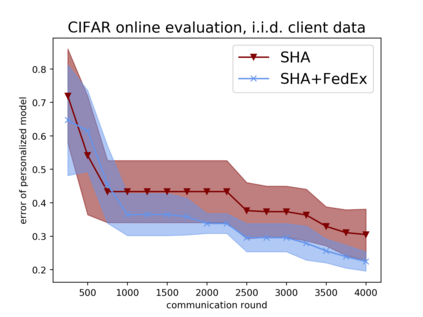
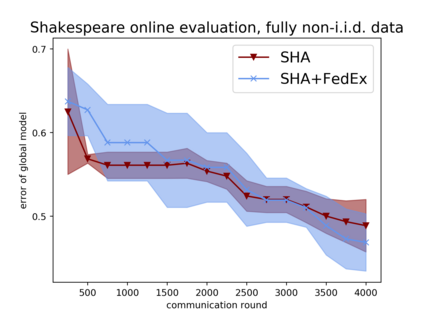
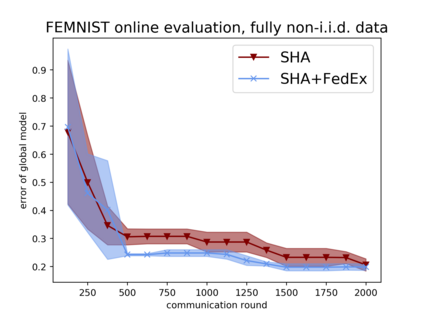
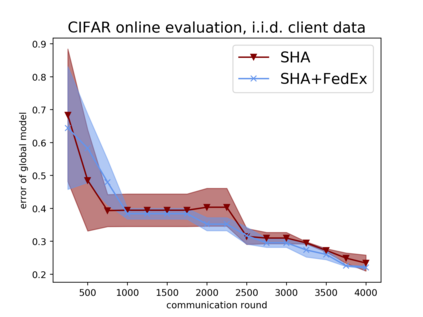
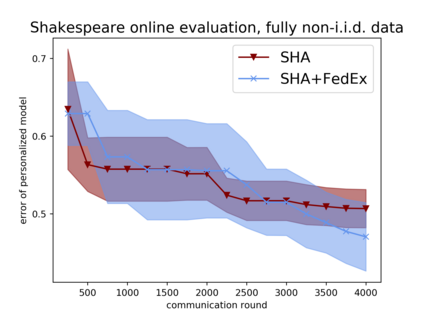
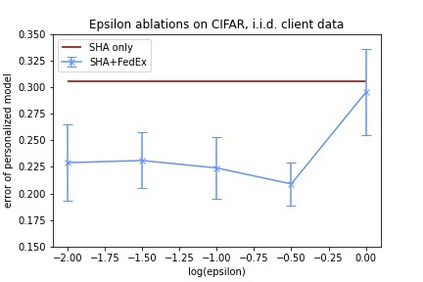
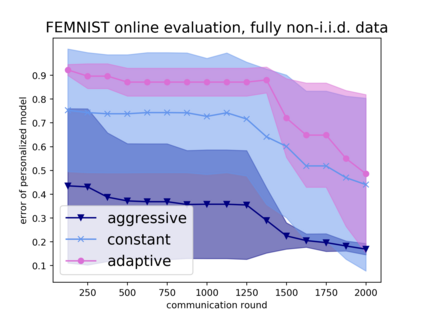
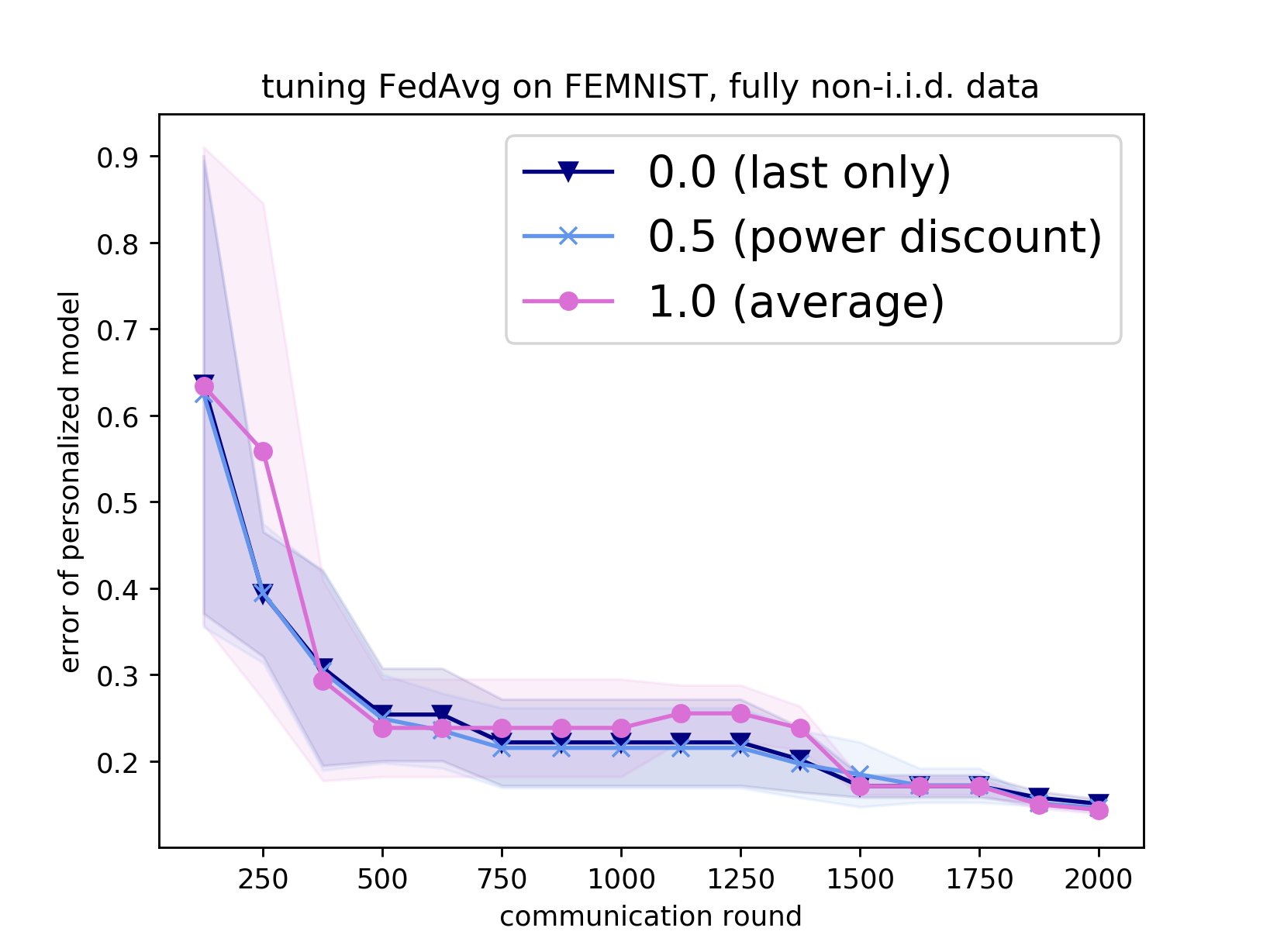
Tuning hyperparameters is a crucial but arduous part of the machine learning pipeline. Hyperparameter optimization is even more challenging in federated learning, where models are learned over a distributed network of heterogeneous devices; here, the need to keep data on device and perform local training makes it difficult to efficiently train and evaluate configurations. In this work, we investigate the problem of federated hyperparameter tuning. We first identify key challenges and show how standard approaches may be adapted to form baselines for the federated setting. Then, by making a novel connection to the neural architecture search technique of weight-sharing, we introduce a new method, FedEx, to accelerate federated hyperparameter tuning that is applicable to widely-used federated optimization methods such as FedAvg and recent variants. Theoretically, we show that a FedEx variant correctly tunes the on-device learning rate in the setting of online convex optimization across devices. Empirically, we show that FedEx can outperform natural baselines for federated hyperparameter tuning by several percentage points on the Shakespeare, FEMNIST, and CIFAR-10 benchmarks, obtaining higher accuracy using the same training budget.
翻译:超光谱仪是机器学习管道中一个关键但艰巨的部分。超光谱优化在联合学习中甚至更加具有挑战性,因为通过分布式混合设备网络学习模型;这里,需要保留设备数据并进行本地培训使得难以高效地培训和评估配置。在这项工作中,我们调查了超光谱仪调试问题。我们首先找出了关键挑战,并展示了标准方法如何调整以形成配方环境的基线。然后,通过对权重共享神经结构搜索技术进行新颖的连接,我们引入了一种新的方法,即FedEx,以加速适用于广泛使用的联邦化优化方法(如FedAvg和最近的变体)的联邦化超光谱仪调整。理论上,我们显示FedEx的变式正确调整了在设置在线锥体优化各设备时的在线配置学习速率。我们从中可以看出,FedEx可以超越由莎士、FEMNIST和CIFAR-10基准进行若干百分点的节制超光度调整的自然基线。