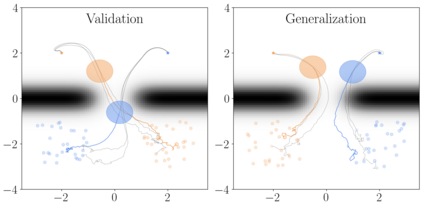
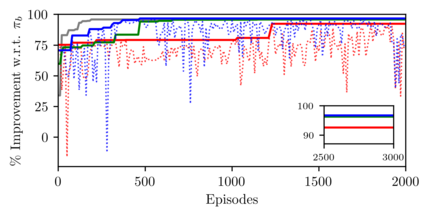
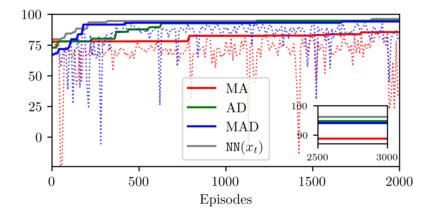
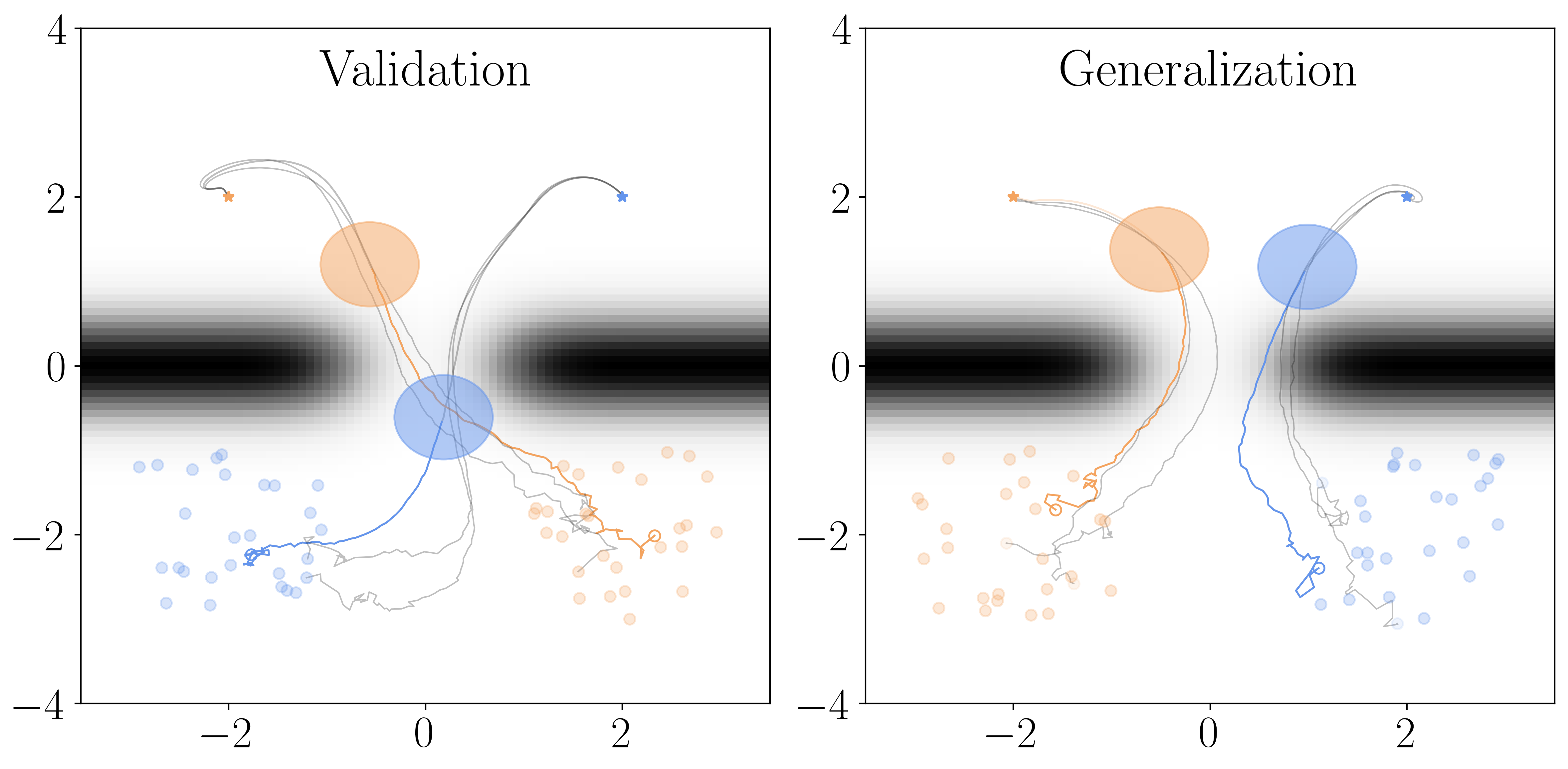
We introduce magnitude and direction (MAD) policies, a policy parameterization for reinforcement learning (RL) that preserves Lp closed-loop stability for nonlinear dynamical systems. Although complete in their ability to describe all stabilizing controllers, methods based on nonlinear Youla and system-level synthesis are significantly affected by the difficulty of parameterizing Lp-stable operators. In contrast, MAD policies introduce explicit feedback on state-dependent features - a key element behind the success of RL pipelines - without compromising closed-loop stability. This is achieved by describing the magnitude of the control input with a disturbance-feedback Lp-stable operator, while selecting its direction based on state-dependent features through a universal function approximator. We further characterize the robust stability properties of MAD policies under model mismatch. Unlike existing disturbance-feedback policy parameterizations, MAD policies introduce state-feedback components compatible with model-free RL pipelines, ensuring closed-loop stability without requiring model information beyond open-loop stability. Numerical experiments show that MAD policies trained with deep deterministic policy gradient (DDPG) methods generalize to unseen scenarios, matching the performance of standard neural network policies while guaranteeing closed-loop stability by design.
翻译:暂无翻译