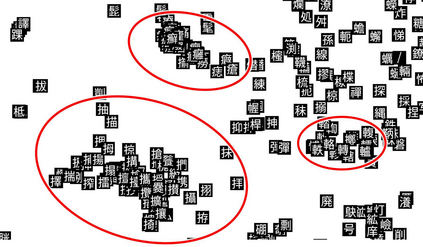
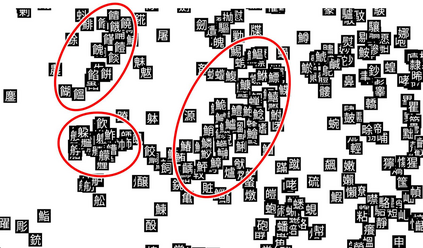
For analysing and/or understanding languages having no word boundaries based on morphological analysis such as Japanese, Chinese, and Thai, it is desirable to perform appropriate word segmentation before word embeddings. But it is inherently difficult in these languages. In recent years, various language models based on deep learning have made remarkable progress, and some of these methodologies utilizing character-level features have successfully avoided such a difficult problem. However, when a model is fed character-level features of the above languages, it often causes overfitting due to a large number of character types. In this paper, we propose a CE-CLCNN, character-level convolutional neural networks using a character encoder to tackle these problems. The proposed CE-CLCNN is an end-to-end learning model and has an image-based character encoder, i.e. the CE-CLCNN handles each character in the target document as an image. Through various experiments, we found and confirmed that our CE-CLCNN captured closely embedded features for visually and semantically similar characters and achieves state-of-the-art results on several open document classification tasks. In this paper we report the performance of our CE-CLCNN with the Wikipedia title estimation task and analyse the internal behaviour.
翻译:分析和(或)理解基于日语、中语和泰语等形态分析的没有字界界限的语言,最好在嵌入文字之前进行适当的字分解,但在这些语言中,这具有内在的困难。近年来,基于深层次学习的各种语言模式取得了显著进展,其中一些使用性格特征的方法成功地避免了这样一个难题。然而,如果将上述语言的性格特征作为特征特性级特征提供一个模型,则往往会由于许多字符类型而导致过于适合。在本文中,我们建议使用字符编码器来进行CE-CLCNN, 性格级神经神经网络,用于解决这些问题。拟议的CE-CLCNN是一个端到端学习模式,具有基于图像的字符编码器,即CE-CLCNN将目标文件中的每个字符都作为图像处理。我们通过各种实验发现并确认,我们的CE-CLCNN为视觉和语义性格相似的近嵌嵌嵌,并用若干开放文件标题的CMILIA任务,我们用CLU内部任务分析了我们的文件。