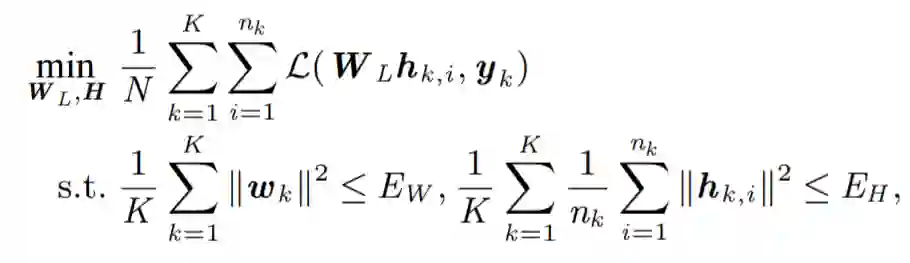来自宾夕法尼亚大学的研究者提出了一种层间 「剥离」的分析模型,该研究发表在顶级期刊《美国国家科学院院刊》上。
近年来,深层神经网络已经在诸多科学与工程问题上取得了优良的表现,但关于其良好的泛化性能和鲁棒性却一直缺乏令人满意的理论解释。由于深层神经网络高度非凸和非光滑的性质,想要提出一般性的理论框架困难重重,在这种情况下,如何尽可能地寻找一种近似模型,既能保持深层网络的基本性质,又能从数学角度给出严格的分析?
![]()
论文地址:https://www.pnas.org/content/118/43/e2103091118
近日,
宾夕法尼亚大学一团队发表在顶级期刊《美国国家科学院院刊》上的一篇文章 [1] 提出了一种层间「剥离」 的分析模型
,对上述问题给出了一种新思路。基于神经网络强大的表达能力,该模型将网络的部分层看作一个整体,将其输出特征看作一个可以适应网络训练过程的优化变量,着重研究了特征与后继层参数在网络训练中的相互作用。特别的,在仅剥离网络最后一层的情形,神经网络就被简化为了下面的形式:
![]()
Figure 1 层间剥离模型的数学表达式。
作为这一全新分析视角的应用,文章对去年美国科学院院士 David Donoho 及其团队提出的神经坍缩 (Neural Collapse) 现象 [2] 给出了严格的数学解释。神经坍缩描述了一种当不同类的训练样本数量平衡时,在深层神经网络的训练过程的最终阶段 (Terminal Phase of Training),网络最后一层的分类器和输出特征会各自形成一种被称为简单等角紧框架(Simplex Equiangular Tight Frame) 的特殊几何结构,并相互之间形成联合的特殊现象。这一几何结构中不同类的特征与分类器的夹角达到最大值,更难出现不同类之间相互混淆,因而神经坍缩现象解释了为何深度神经网络具有良好的泛化性能和鲁棒性,对理解深度学习的优良性能有着重大意义。
![]()
Figure 2 神经坍缩现象的图示,红色棍代表最后一层分类器的方向,蓝色棍代表最后一层特征的平均值方向,蓝色小球代表最后一层的特征向量,绿色小球代表简单等角紧框架的方向,从左至右代表网络训练的过程,可以看到随着训练的进行,网络最后一层的特征与分类器都逐渐收敛到了简单等角紧框架的方向。
基于前面提到的层间剥离模型,文章中证明了在不同类的训练样本数量平衡时神经坍缩现象的全局最优性,从理论上揭示了为何神经坍缩现象在深层神经网络中广泛存在。更进一步的,文章考虑了不同类的训练样本数目不平衡的情况下的层间剥离模型,从理论分析中发现了一种全新的现象——非均衡坍缩(Minority Collapse)。非均衡坍缩指出,当训练样本中一些类的数目较多,而另一些类的数目较少时,神经坍缩中高度对称的简单等角紧框架结构被破坏,样本数较多的类在损失函数中占据了主导性地位,从而其对应的最后一层的特征和分类器可以相互之间张成更大的角度,而样本数较少的类则会被挤压到一起,相互之间的夹角随着样本数目比例的减少而减小。文章中对非均衡坍缩现象给出了严格的数学刻画,并经过大量的实验验证了这一现象的存在,且实验结果与理论值严格符合。非均衡坍缩表明将深度学习工具用于可信人工智能时可能会引起不公平现象。值得注意的是,这个发现是深度学习中极少数完全由理论分析预测的。这个工作由宾夕法尼亚大学苏炜杰和其团队的方聪和何杭峰等人完成。值得注意的是,方聪博士近期已回国执教于北京大学智能科学系。
![]()
Figure 3深度神经网络中的非均衡坍缩现象,横坐标R代表类之间样本数的比例,纵坐标代表样本数较少的类的最后一层特征之间的方向的余弦值。可以看到随着R从1增加到无穷大,这些样本数较少的类的特征从神经坍缩中最大化两两之间夹角的方向逐渐被挤压到相同的方向。ABCD四张图分别是VGG和ResNet两种网络结构在Fashion-MNIST和CIFAR10两个数据集上分别的结果。
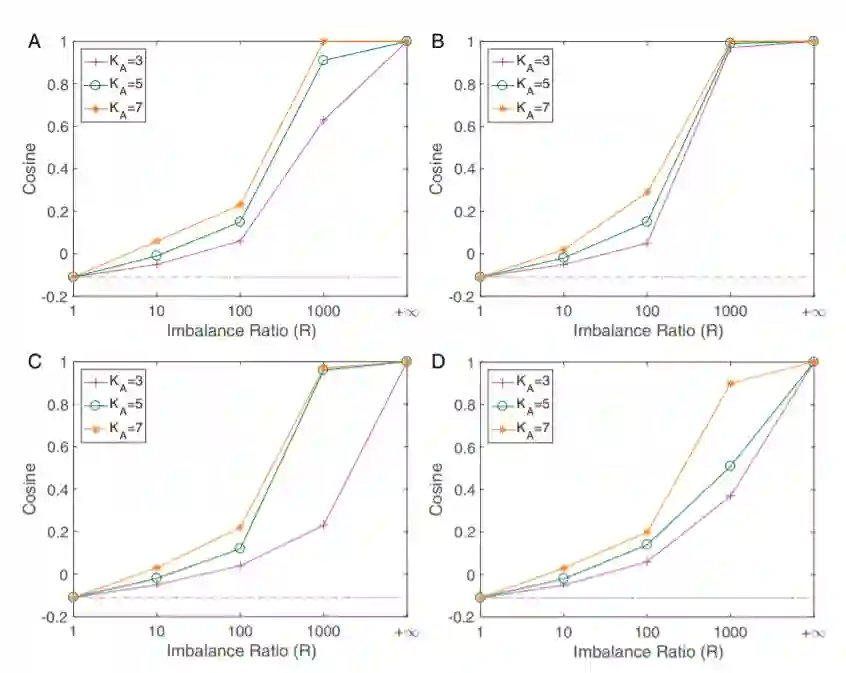
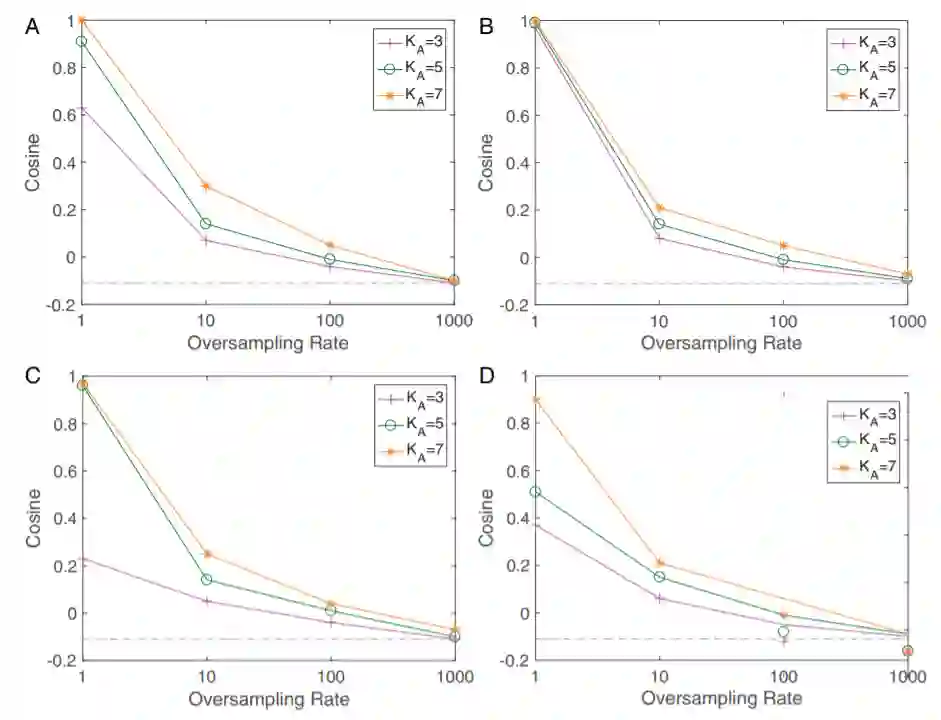
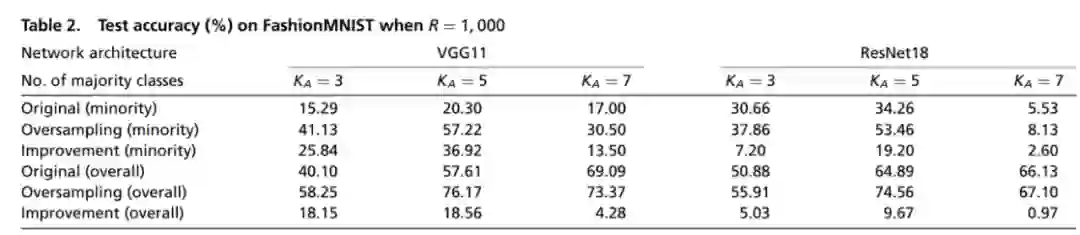
训练样本中的不平衡带来的公平性问题是机器学习领域长久以来的重要问题之一,常用的用来缓解这一问题的方法主要是重采样 (resampling) 和重赋权 (reweighting) 两种方法。在文章中,研究者通过层间剥离模型给出了这两种方法有效性的理论保证:文章从数学上严格证明了利用重采样和重赋权技术,深层神经网络的对称性可以被完全修复,神经坍缩中最大化不同类之间分类器和特征各自夹角的简单等角紧框架结构将会重新出现,这就解释了为何这两种技术可以显著提升网络的泛化性能。
![]()
Figure 4 重采样技术对于网络最后一层对称性的修复作用。可以看到随着重采样比例逐渐接近类之间的样本数比例,数据集不平衡造成的对称性破坏被重采样逐渐修复,最终在两个比例相等时完美地重现了神经坍缩地几何结构。ABCD四张图分别是VGG和ResNet两种网络结构在Fashion-MNIST和CIFAR10两个数据集上分别的结果。
![]()
Figure 5 重采样和原始训练的泛化性能比较。可以看到在多种条件下,重采样技术对网络泛化性能的都有显著提高。
在后续工作中,北大数院本科生冀文龙在苏炜杰教授的指导下完成的一篇文章 [3] 基于层间剥离模型对神经坍缩现象做出了进一步的理论分析,文章提出了一种无约束层间剥离模型,去掉了对特征和参数的约束,研究了在更真实的条件下,网络训练中参数的渐进行为。文章指出了神经坍缩现象的出现与神经网络的隐式正则化的关系,并在这一非凸问题上对于网络损失函数的几何景观和梯度下降的训练过程给出了严格的刻画,更精确地解释了梯度下降如何收敛到神经坍缩的几何结构。
作为一种一般化的强有力分析手法,层间剥离模型为诸多深度学习理论问题提出了一种模块化、剥离化的全新研究范式。进一步的研究方向包括如何利用多层层间剥离模型给出对神经网络更精确的描述?在这种情况下是否存在更强的对称性结果?如何将神经网络的训练与泛化纳入到层间剥离模型的考虑范畴内?这一模型如何为其他当下流行的深度学习理论诸如信息瓶颈,隐式正则化,局部弹性提供全新的视角?相信在不久的未来,我们能够看到层间剥离模型带来更多令人振奋的结果。
[1] Cong Fang, Hangfeng He, Qi Long, and Weijie J. Su. "Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training." Proceedings of the National Academy of Sciences 118, no. 43 (2021).
[2] Vardan Papyan, X. Y. Han, and David L. Donoho. "Prevalence of neural collapse during the terminal phase of deep learning training." Proceedings of the National Academy of Sciences 117, no. 40 (2020): 24652-24663.
[3] Wenlong Ji, Yiping Lu, Yiliang Zhang, Zhun Deng, and Weijie J. Su. "An Unconstrained Layer-Peeled Perspective on Neural Collapse." arXiv preprint arXiv:2110.02796 (2021).
第一期:快速搭建基于Python和NVIDIA TAO Toolkit的深度学习训练环境
英伟达 AI 框架 TAO(Train, Adapt, and optimization)提供了一种更快、更简单的方法来加速培训,并快速创建高度精确、高性能、领域特定的人工智能模型。
11月15日19:30-21:00,英伟达专家带来线上分享,
将介绍:
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com