论文题目: Confidence May Cheat: Self-Training on Graph Neural Networks under Distribution Shift
会议: The WebConf 2022
论文地址 :https://arxiv.org/abs/2201.11349
近几年来,图神经网络(GNNs)得到飞速发展,在多种图相关的任务中性能卓越。众所周知,GNN卓越的性能严重依赖于有标签数据构成的监督信息,而数据标签的获取往往代价高昂。为了解决数据标签的稀疏性问题,自训练策略被引入到图神经网络中。自训练策略是一种利用模型对无标签节点的预测生成伪标签,从而扩充原始训练集的方法。一般来说,为了尽可能过滤掉错误的伪标签,现有的图神经网络自训练方法仅会保留高置信度预测生成的伪标签。然而,预测的高置信度代表模型可能已经学习到了该节点包含的大部分信息,再通过自训练策略将该节点加入到训练集真的是有效的吗?
为了回答上述问题,我们进行了如下两个探究性实验:
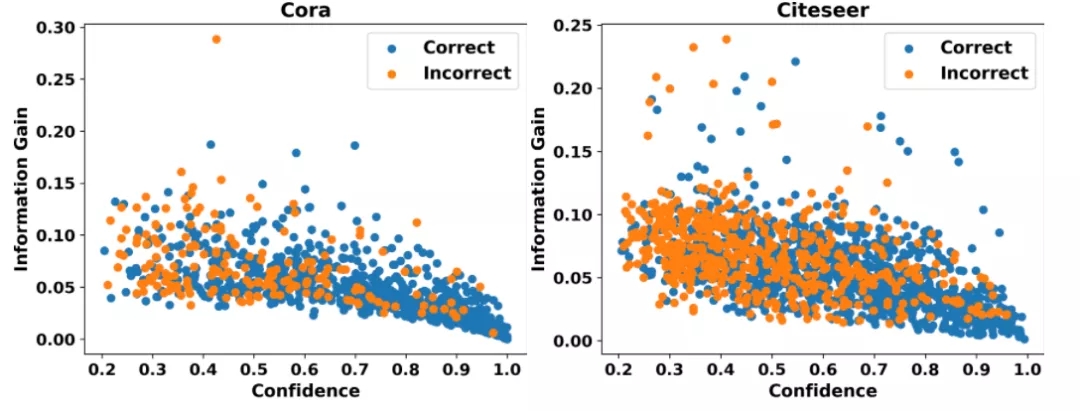
(1) 探究置信度与信息增益的关系 这里的信息增益指对模型参数的信息增益,可以衡量节点为模型引入额外信息的多少,因此该探究性实验可以清楚地展示高置信度节点是否能够为模型引入额外信息。
我们可视化了标准GCN模型对Cora和Citeseer两个数据集中无标签节点的置信度与节点对模型参数的信息增益的关系,如图1所示,其中横坐标代表置信度,纵坐标代表信息增益,蓝色与橙色的点分别代表预测正确与预测错误的节点。我们可以清楚地看到,置信度与信息增益呈现明显的负相关关系。也就是说,置信度越高的节点信息增益越低。考虑到现有的图神经网络自训练方法仅会保留高置信度预测生成的伪标签,我们认为这些方法难以为模型引入额外的有效监督信息。为了进一步解释上述现象存在的原因,我们又进行了如下实验。
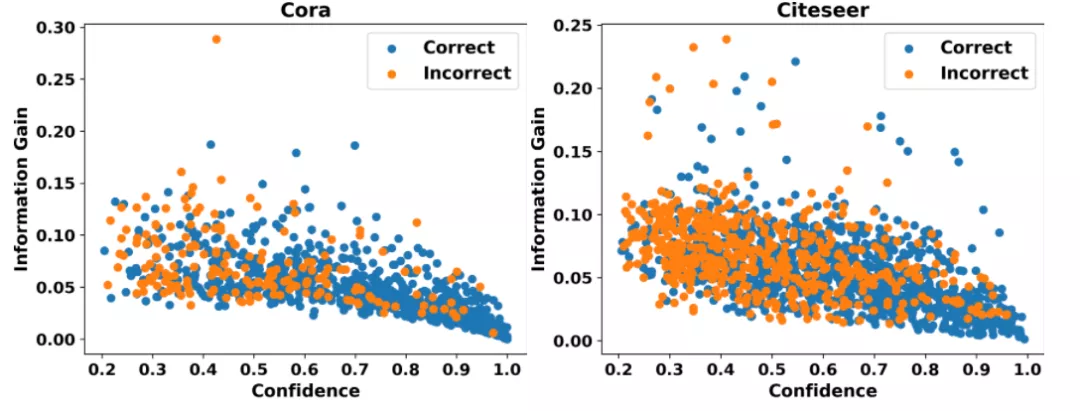
图1 置信度与信息增益的关系
(2) 探究节点嵌入表示的分布情况 本质上来讲,图神经网络自训练策略通过为模型引入额外的监督信息,使模型实际的决策边界更靠近最优决策边界,从而获得更好的性能,因此我们希望该额外的监督信息分布于靠近决策边界的位置,从而能够最大程度地影响到决策边界的改变。基于上述分析,我们可视化了节点嵌入表示(embedding)的分布,对置信度与决策边界的关系做进一步探究。
我们利用t-SNE[1]算法可视化了标准GCN模型对Cora和Citeseer两个数据集的嵌入表示(GCN的softmax层的输入),如图2所示,其中颜色越深的点代表该节点对模型参数的信息增益越低。我们发现,大多数的低信息增益(高置信度)的节点都分布于远离决策边界的位置。这一方面解释了为什么这些节点拥有更低的信息增益,另一方面也暗示了现有图训练方法关注的节点大部分远离决策边界。因此,这些节点难以帮助模型获得一个更加有效的决策边界。从这个角度来说,现有的图神经网络自训练方法被置信度“欺骗”到了。
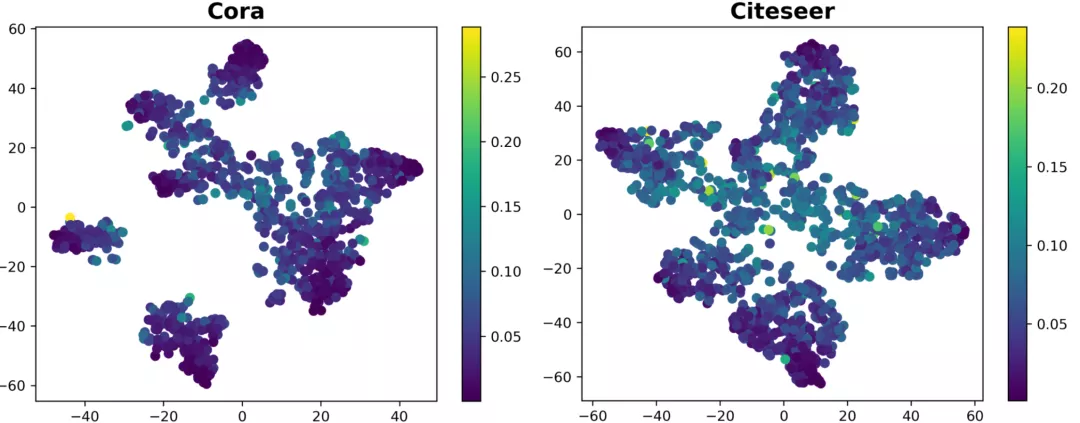
图2 节点嵌入表示的分布
我们进一步分析图神经网络自训练方法被置信度“欺骗”的严重后果。我们用随机生成的500个符合二维高斯分布的蓝色点表示一类有标签节点的嵌入表示,用其余4000个符合圆环分布的灰色点表示其他类有标签节点的嵌入表示,如图3(a)所示。此外,遵循半监督任务的设定,数据集中还存在大量的无标签节点,但是为了示意图的清晰,我们未在其中进行表示。根据现有图神经网络自训练方法的核心思想,GNN模型对位于“蓝色”类中心(远离决策边界)的无标签节点拥有更高的置信度,因此这些节点将会被赋予伪标签并加入到训练集中,而位于决策边界附近的节点将会被置信度过滤掉并不予考虑。这将导致训练集的分布将随着自训练的进行逐渐偏向于类别中心节点所代表的分布,与原始训练集的分布明显不同,如图3(b)所示,出现分布迁移现象。图神经网络自训练方法引入的分布迁移可能会使模型拥有糟糕的泛化能力,严重威胁到模型的性能。
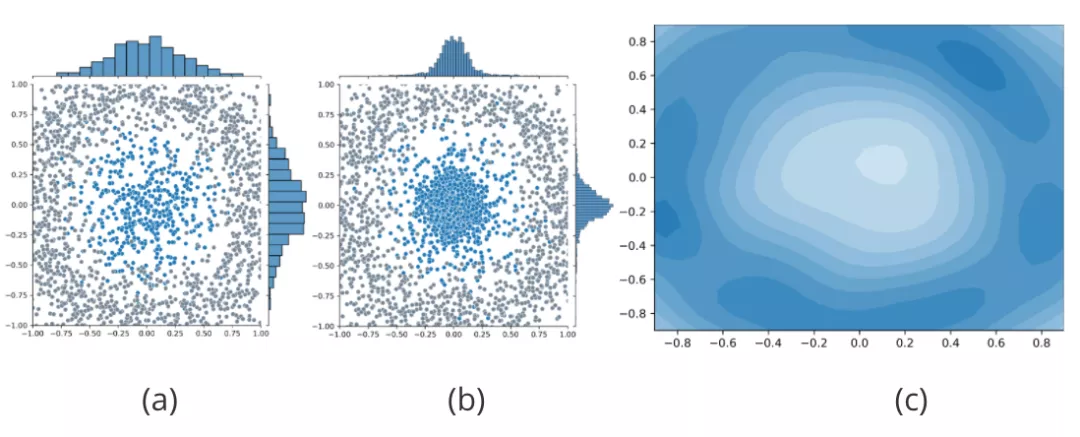
图3 对分布迁移的解释
为了解决上述问题,我们提出了基于分布恢复的图神经网络自训练方法DR-GST。我们首先分析了理想与分布迁移情况下图神经网络自训练方法的损失函数,理论结果表明只要为每个无标签节点赋予适当的权重便可以消除分布迁移问题。基于对实验结果的分析,我们提出利用正则化后的信息增益作为上述权重。此外,为了消除自训练策略可能引入的错误信息,我们将损失修正策略引入到图神经网络自训练方法中。最后的理论分析与实验验证均证明了我们方法的有效性。