人脸合成效果媲美StyleGAN,而它是个自编码器
机器之心报道
参与:魔王
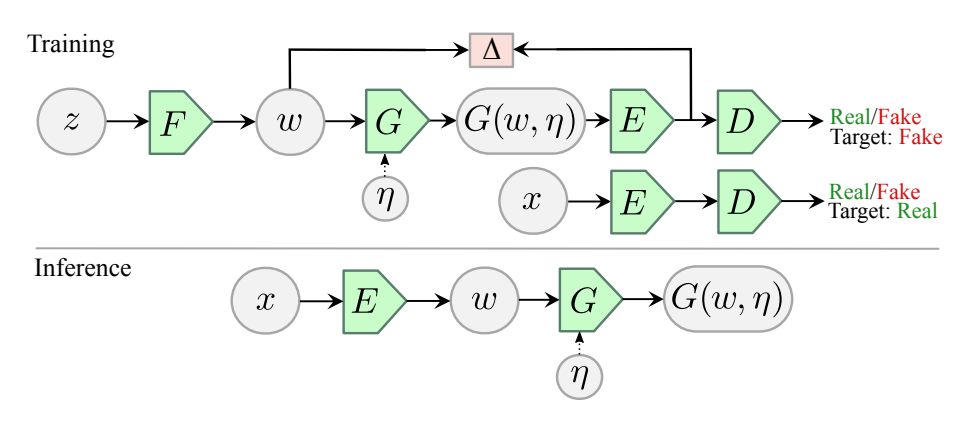
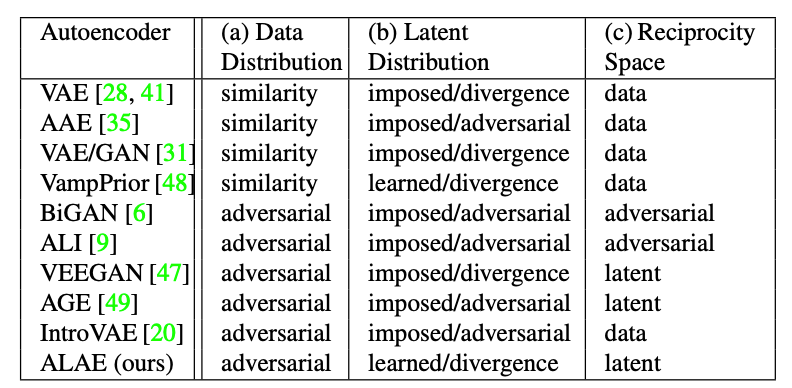
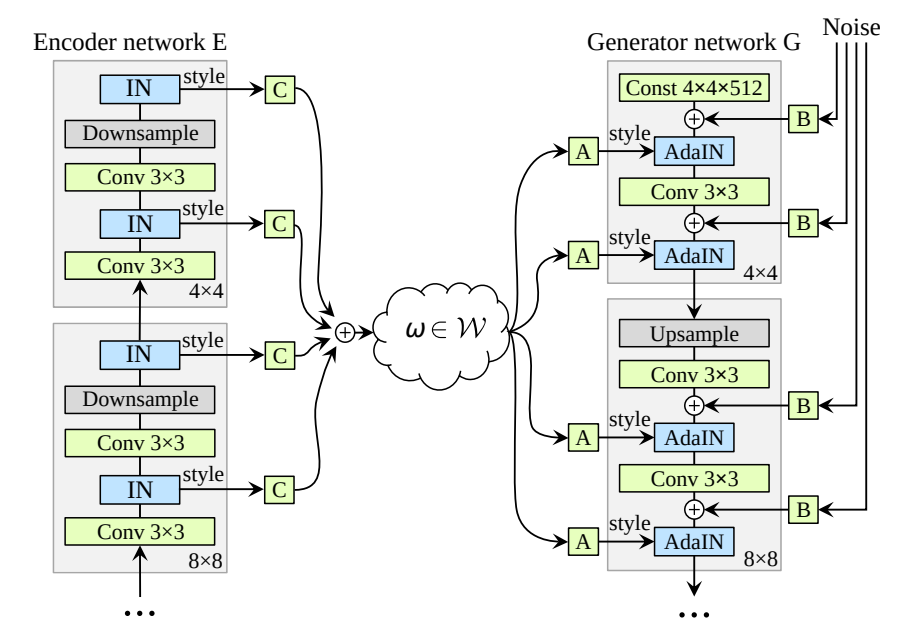
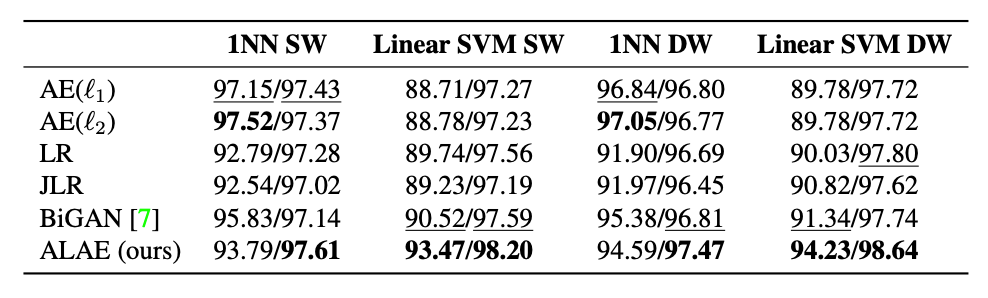
自编码器(AE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法,它们也经常被拿来比较。人们通常认为自编码器在图像生成上的应用范围比 GAN 窄,那么自编码器到底能不能具备与 GAN 同等的生成能力呢?这篇研究提出的新型自编码器 ALAE 可以给你答案。目前,该论文已被 CVPR 2020 会议接收。
论文地址:https://arxiv.org/pdf/2004.04467.pdf
GitHub 地址:https://github.com/podgorskiy/ALAE
自编码器是否具备和 GAN 同等的生成能力?
自编码器能否学习解耦表征(disentangled representation)?
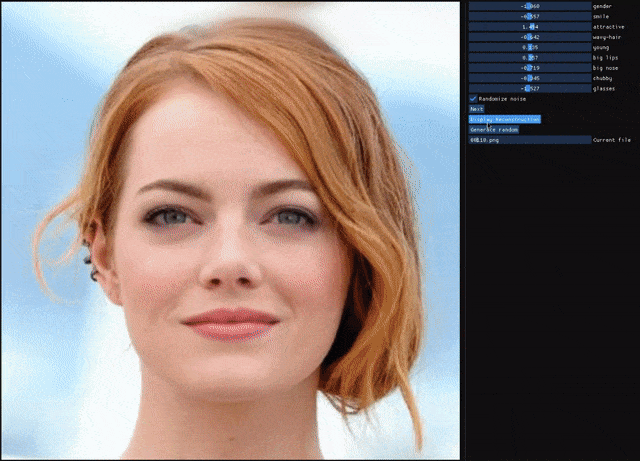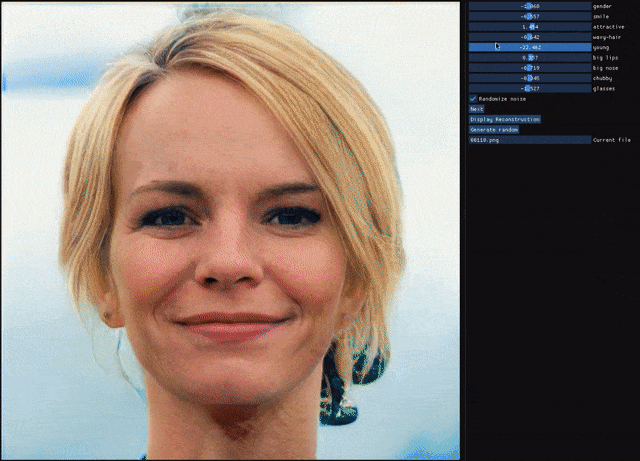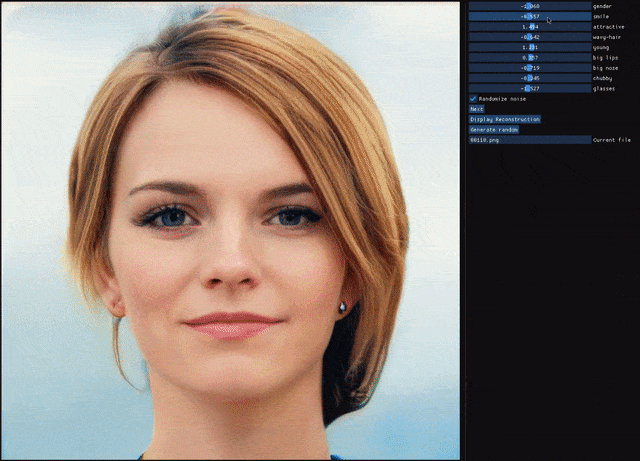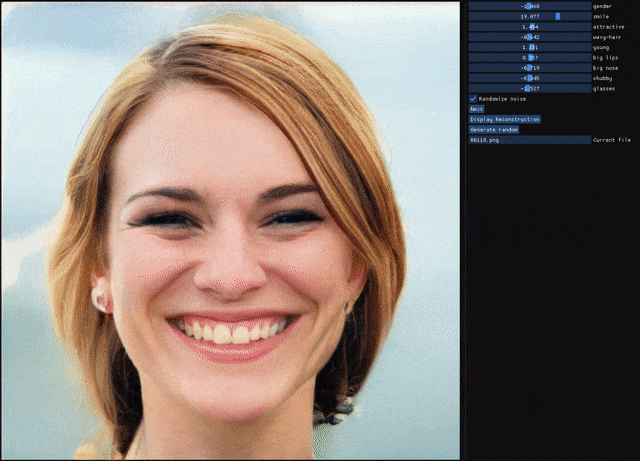




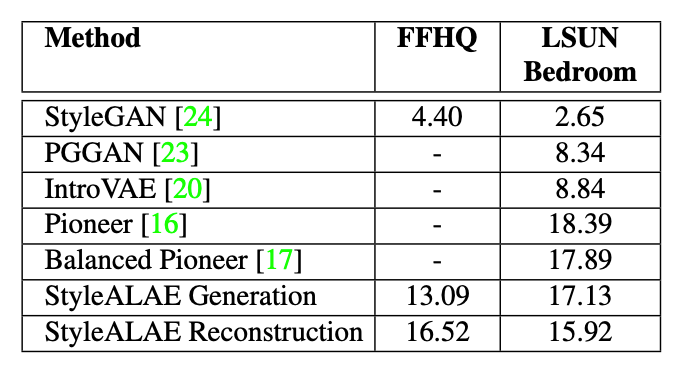
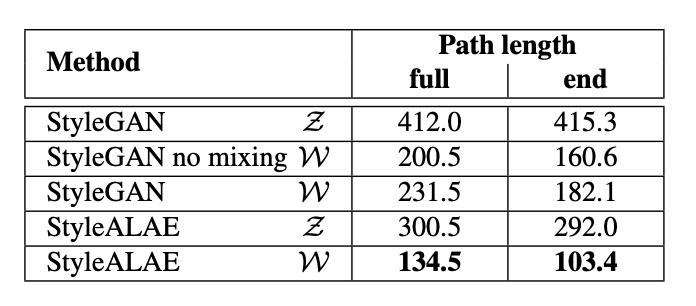




登录查看更多
相关内容

专知会员服务
36+阅读 · 2020年3月13日
专知会员服务
27+阅读 · 2019年8月10日
Arxiv
10+阅读 · 2018年3月20日


相关VIP内容
专知会员服务
36+阅读 · 2020年3月13日
专知会员服务
27+阅读 · 2019年8月10日
相关资讯
相关论文
Arxiv
10+阅读 · 2018年3月20日