谷歌大脑:像BigGAN那样生成高清大图不一定需要大量图像标签
机器之心报道
机器之心编辑部
原版的 GAN 是一种无监督学习,我们只要准备大量真实数据就行了。而如果要像 BigGAN 那样在 ImageNet 上生成高保真度的图像,我们还是需要大量类别信息。本研究介绍了如何在没有标注或有少量标注数据的情况下生成高保真图像,这大大缩小了条件GAN 与无监督 GAN 的差距。
正如 GoodFellow 所言,尽管 GAN 本身是无监督的,但高保真自然图像的生成(通常在 ImageNet 上训练)取决于能否访问大量标注数据。这并不奇怪,因为标签会在训练过程中引入丰富的辅助信息,从而有效地将极具挑战性的图像生成任务分成语义上有意义的子任务。
但是,实际上大部分数据是未标注的,而标注通常成本较高,还容易出错。虽然无监督图像生成近期取得了一些进展,但就样本质量而言,条件模型和无监督模型之间的差距还是很大的。
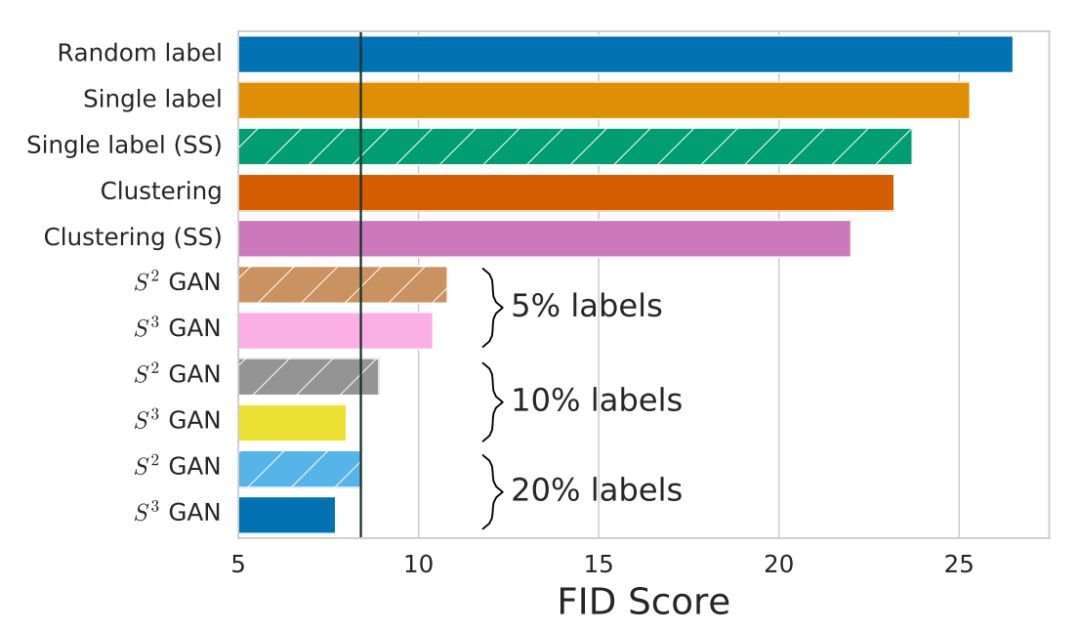
图 1:基线方法和本文提出方法的 FID 得分。垂直线表示使用了所有标注数据的基线(BigGAN)。本文提出的方法(S^3GAN)仅用 10% 的标注数据就能够媲美当前最佳水平的基线模型,用 20% 的标注数据就超过了基线。
本文使用生成对抗网络,大大缩小了条件模型和无监督模型在高保真图像生成方面的差距。本文利用了两个简单但强大的概念:
自监督学习:通过自监督来学习训练数据的语义特征提取器,然后用生成的特征表示来指导 GAN 训练过程。
半监督学习:通过标注训练图像的较小子集来推断出整个训练集的标签,然后将推断出来的标签用作 GAN 训练的条件信息。
本文贡献如下:
提出并研究了多种方法,来减少或完全删去用于自然图像生成任务的真值标注信息。
以无监督生成的方式在 ImageNet 上达到了新的 SOTA,仅用 10% 的标注数据就在 128x128 的图像上达到了当前 SOTA 结果,仅用 20% 的标注数据就实现了新的 SOTA(由 FID 衡量)。
开源了实验中使用的所有代码:http://github.com/google/compare_gan
论文 :High-Fidelity Image Generation With Fewer Labels

论文地址:https://arxiv.org/abs/1903.02271
摘要:深度生成模型正在成为当代机器学习的基石。近期针对条件生成对抗网络的研究表明,自然图像的学习复杂度、高维度分布也成为了可以解决的问题。虽然最新的模型能够生成高分辨率、高保真的多种自然图像,但它们极度依赖大量标注数据。在本文中,我们展示了如何利用在自监督、半监督学习领域取得的进步,在无监督 ImageNet 合成和条件环境下实现超越 SOTA 模型的性能。特别是,我们提出的方法仅用 10% 的标注数据就能媲美当前条件模型 BigGAN 在 ImageNet 上的 SOTA 采样质量,仅用 20% 的标注数据就超越了它。
减少标注数据的需求
简而言之,我们并不会为判别器提供经手动标注的真实图像,而是提供推断的标注。为了获得这些标签,我们将利用自监督和半监督学习的最新进展。在解释这些方法前,我们首先探讨一下标签信息在 SOTA GAN 中发挥了什么作用。以下阐述会先假定我们比较熟悉 Goodfellow 等人提出的 GAN 框架。
为了向判别器提供标签信息,我们采用了 Miyato&Koyama(2018)提出的线性映射层。在原版的 GAN 中(unconditional),判别器 D 会学习预测输入图像 x 到底是真实的还是由生成器 G 生成的。我们可以将判别器分解为一个学习的判别器表征 D˜ 和判别函数 c_r/f,其中 D˜ 馈送到一个线性分类器中,也就是说判别器可以表示为 c_r/f(D˜(x))。
在映射判别器中,它可以学习到判别器每一个类别的嵌入向量表征 D˜(x)。因此给定一张图像与标签(x, y),决定样本是真实值还是伪造值的元素有两个:(a) 表征 D˜(x) 本身是与真实数据一致的,(b) 同时表征 D˜(x) 也和类别 y 的真实数据相一致。正式而言,判别器采样自 D(x, y) = c_r/f(D˜(x)) + P(D˜(x), y),其中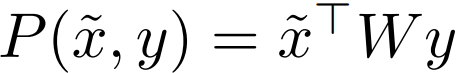
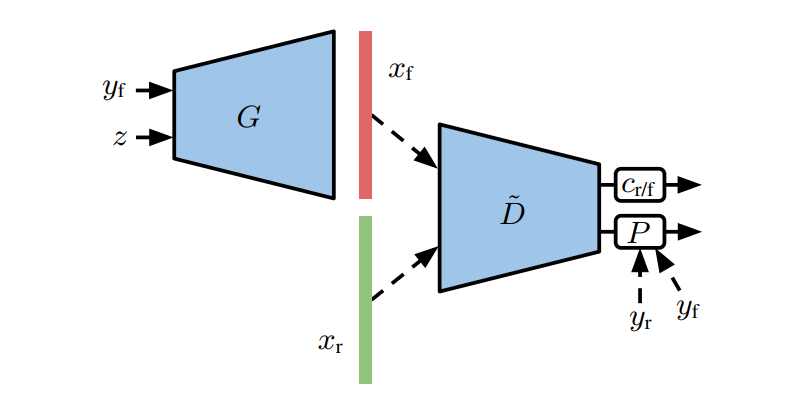
图 3:带有映射判别器的 Conditional GAN。
我们首先使用 SOTA 自监督方法学习真实数据的表征,在此表征上执行聚类,并使用不同的集群作为类别的替代。
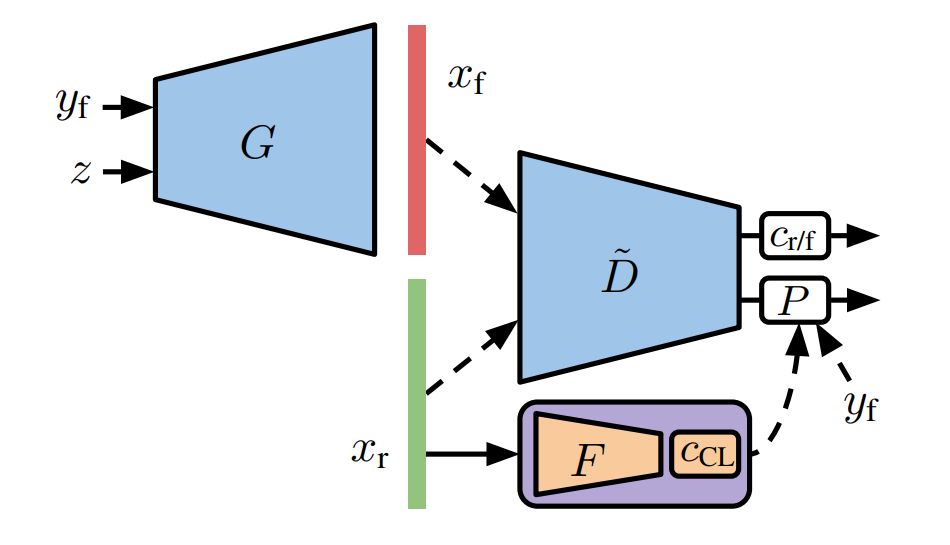
图 4:CLUSTERING:通过无监督聚类处理求解自监督任务获得的表征。
结果和讨论
本文的主要目标是以无监督的方式或用较少的标注数据来达到(或超过)全监督 BigGAN 的性能。接下来,本文将据此分析本文方法的优势和缺点。
研究者对基线模型 BigGAN 重新实现,获得了 8.4 的 FID 分数和 75.0 的 IS 分数,复现了 Brock 等人(2019)的结果。研究者在训练的动态过程中发现了一些不同之处,将在 5.4 中讨论。
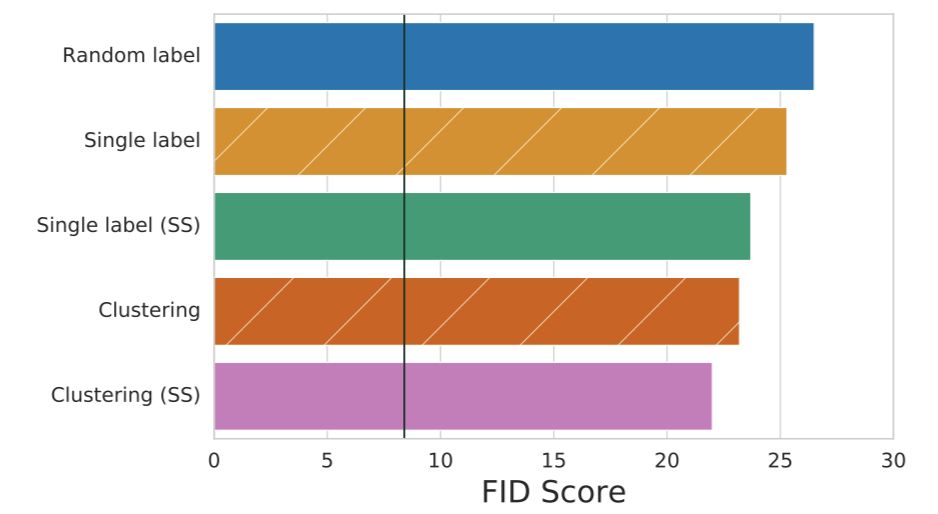
图 7:本研究提出的无监督方法获得的中值 FID 分数。垂直线表示 BIGGAN 实现的 FID 中值,该实现为所有训练图像使用标签。尽管无监督方法和全监督方法之间的差距仍然很大,但与单标签和随机标签相比,使用预训练自监督表征(聚类)提高了样本质量,从而在 IMAGENET 上实现了新的 SOTA 结果。
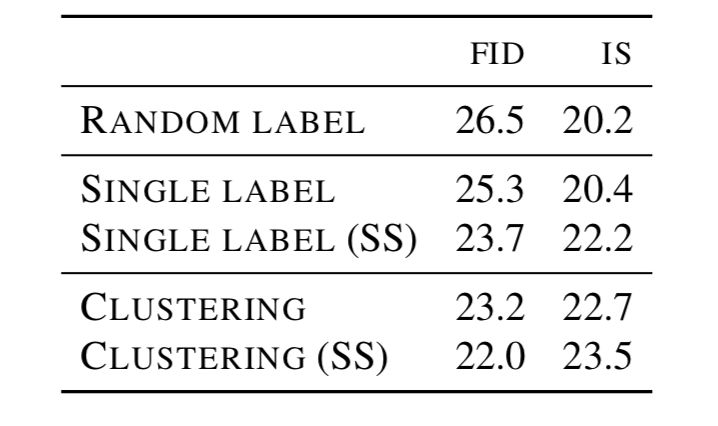
表 2:无监督方法获得的中值 FID 和 IS 分数(平均值和标准差见附录中的表 14)。
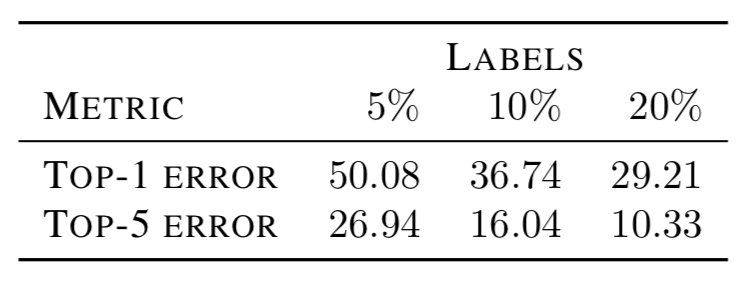
表 3:使用自监督和半监督损失(见 3.1)在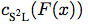
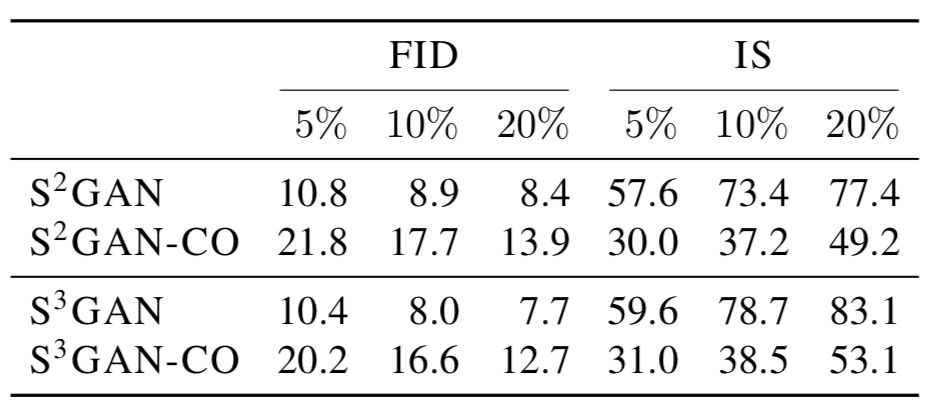
表 4:预训练 vs 联合训练方法以及自监督方法在 GAN 训练期间的效果。尽管联合训练方法优于全监督方法,但预训练方法更胜一筹。在任何情况下,自监督在 GAN 训练过程中都很有用。
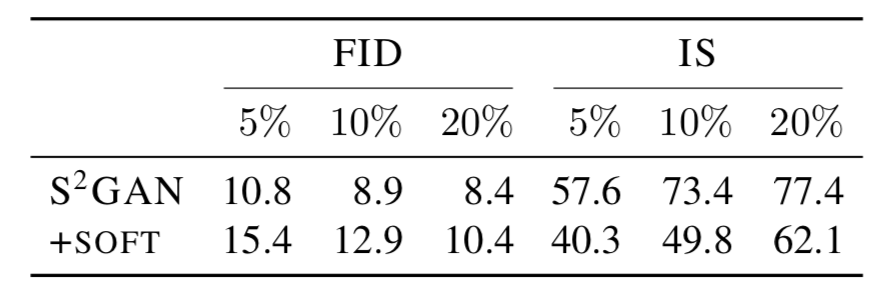
表 5:使用硬(预测)标签训练得到的模型要比软(预测)标签训练模型更好(均值和标准差参见附录中的表 13)。
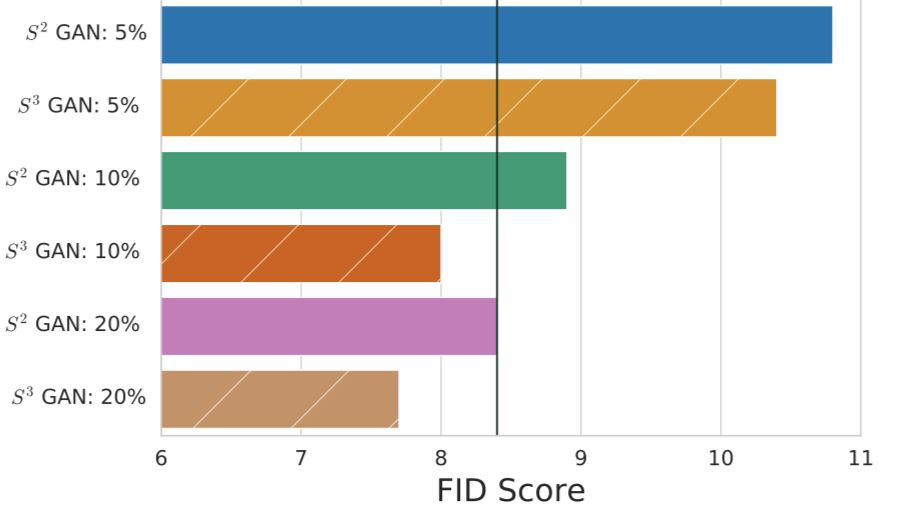
图 8:垂直线表示使用所有标注数据实现的 BIGGAN 的 FID 中值。本研究提出的 S^3 GAN 方法使用 10% 的 ground-truth 标注数据的表现就能与 SOTA BIGGAN 模型相媲美,使用 20% 的标注数据后性能就能超越 SOTA 模型。
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


