【BicycleGAN】NIPS 2017论文图像转换多样化,大幅提升pix2pix生成图像效果
点击上方“专知”关注获取专业AI知识!

【导读】你一定记得非常热门的加州大学伯克利分校在CVPR2017上提出的图片翻译 pix2pix,它使用GAN方法可以将白马“转化”为斑马,可以把积木“转化”为建筑,可以把线条“转化”为猫咪、鞋子、挎包,可以把白天转化为黑夜。而最近伯克利AI研究实验室与Adobe公司朱俊彦等人提出新的BicycleGAN,解决pix2pix生成图像模式单一的问题,比如BicycleGAN可以跟你给出的一张鞋的草图在保持确定的前提下,生成出各式各样不同纹理风格的图像。 朱俊彦同时也是pix2pix的第二作者。
▌视频
BicycleGAN论文解读视频(英文字幕)
▌作者
Jun-Yan Zhu 朱俊彦图像处理工具CycleGAN、pix2pix、iGAN的主要开发者,Berkeley AI研究实验室博士生,师从Alexei A. Efros教授。他的主要研究方向是计算机视觉、图形学和机器学习,其研究主要致力于让计算机可以创建真实的图像。此前,他在清华获得学士学位,曾在CMU攻读博士学位,目前的研究获得Facebook Fellowship的支持。
Richard Zhang AI研究实验室博士生,师从Alexei A. Efros教授。
https://people.eecs.berkeley.edu/RichardZhang Berkeley
Deepak Pathak 伯克利教授
http://people.eecs.berkeley.edu/~pathak/
Trevor Darrell 伯克利在读博士
https://people.eecs.berkeley.edu/~trevor/
Alexei (Alyosha) Efros伯克利教授
https://people.eecs.berkeley.edu/~efros/
Oliver Wang Adobe公司高级研究科学家
http://www.oliverwang.info/
Eli Shechtman Adobe公司CreativeIntelligence实验室首席科学https://research.adobe.com/person/eli-shechtman/
论文:Toward Multimodal Image-to-Image Translation

▌摘要
很多图像到图像的转换方法是带有歧义的,因为单个输入图像可能对应于多个可能的输出。在本文的工作中,我们的目标是在条件生成建模设置下对可能的输出分布进行建模。映射的模糊性是在潜在的低维向量中进行的,因此可以在测试时随机抽样。在生成器学习时,将给定的输入与隐编码结合起来并映射到输出,且输出和隐编码之间的联系是可逆的。
这有助于防止在训练期间从隐编码到输出之间形成多对一映射(也称为模式崩溃问题),导致产生更多不同的结果。我们通过利用不同的训练目标、不同的网络结构和不同的隐编码注入方式,来探索这种方法的几种不同的变体。我们提出的方法激励隐编码和输出模式之间的双射一致性(bijective consistency)。我们提出了一个系统的比较方法来将我们的方法及其变种进行视觉真实性和多样性评估。
▌详细内容
深度学习技术已经使条件图像生成领域取得了快速发展。例如,这些网络已经被用来修复丢失的图像区域,生成句子相关的图像,给灰度图像上色,草图生成照片等。然而,该领域的大部分技术都专注于根据输入生成单个结果。本文中,我们专注于建模结果的潜在分布,实际上,这类问题可能是多模态且模糊不清的。例如,在夜晚到白天的转换任务中(如图1所示),由于照明、天空、云的类型不同,在夜晚拍摄的图像可能对应很多种白天拍摄的图像。这种条件生成问题有两个主要目标:
视觉真实性;
多样性,同时保持生成图像忠实于原图。
这种从高维输入到高维输出分布的多模式映射,导致条件生成模型具有非常大的挑战性。在已有的方法中,这种挑战导致常见的模式崩溃问题,即生成器只生成唯一的输出。我们系统地研究了这个问题的解决方案,对每个可能的输出学习一个低维的隐编码,该隐编码不存在输入图像中。然后生成器根据所有隐编码以及输入来生成输出结果。
我们从pix2pix框架开始,该框架被认为可以提高各种图像对图像转换任务的转换质量。生成器网络在输入图像的条件下有两个损失:
用回归损失生成一个与ground truth图像相似的输出;
一个判别器损失来激励现实性(视觉逼真)。
作者指出,随意抽出一个随机的隐编码对产生不同的结果没有帮助,而在测试时使用dropout只能提供少量的帮助。因此,我们提出在输出和隐空间之间使用双射(bijection)变换。我们不仅直接执行从输入和隐编码到输出的映射任务,同时还学习从输出回到隐空间的编码器,这抑制两个不同的隐编码产生相同的输出(非单射映射)。
在训练期间,通过学习编码器来发现对应于ground truth输出图像的隐编码矢量,同时将足够的信息传递给生成器以解决不同模式输出的模糊性。例如,当从夜晚图像(图1)产生白天图像时,隐编码可以编码关于天空颜色,地面上的照明效果以及云的密度和形状的信息。在这两种情况下,以不同顺序应用编码器和生成器应该是一致的,都可以得到相同的隐编码或相同的图像。
在本文工作中,我们通过实例化无条件生成建模任务相关文献中的几个目标函数来实现这个想法:
cVAE-GAN(条件变分自编码GAN):是一种通过VAEs学习输出的隐编码分布,进而建模多模式输出分布的方法。在条件设置(类似于无条件模拟)中,我们强制将期望输出图像的隐编码分布反映射到条件生成器得到的输出上。利用KL散度对潜在分布进行正则化,使其接近标准正态分布,从而在推理过程中对随机编码进行采样。然后将这个变分目标与判别器损失一起优化。
cLR-GAN(条件潜在回归GAN):在隐编码中进行模式捕获的另一种方法是显式建模逆映射。从随机抽样的隐编码开始,条件生成器应该产生一个输出,当它作为输入给编码器时,它应该返回相同的隐编码,从而实现自我一致性。这种方法可以看作是“latent regressor”模型的条件表达形式,也与InfoGAN相关。
BicycleGAN:最后,我们结合这两种方法来联合执行隐编码和双向输出之间的连接,并实现性能的改进。我们表明,我们的方法可以在很多图像到图像的转换问题上产生多样的和视觉上吸引人的结果,比其他基准方法更多样化,包括在pix2pix框架中增加噪声的任务。除了损失函数之外,我们还研究了几种网络编码器的性能,以及将隐编码注入生成器网络的不同方式。

图1:我们提出的多模式图到图转换方法效果:给定一幅输入图片(某场景的夜景图),我们目标是建模一个潜在输出的分布(场景对应的白昼图片),生成逼真的和多样的结果。
▌方法:
本文提出的混合模型:BicycleGAN
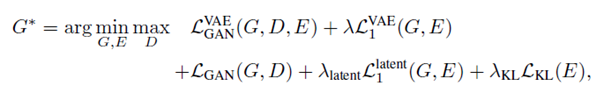
式中G为生成器,D为判别器,E为编码器。这里的主要贡献是利用两个cycles进行性能的提升(B->z->B^和z->B^->z^)。这两个cycles主要通过后面两项实现:
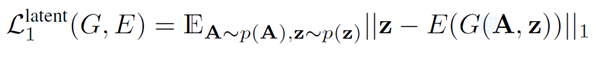
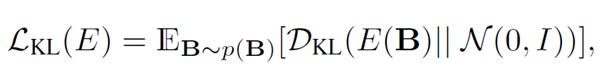
这里A是输入图片,B是得到的生成图片,z是隐编码。
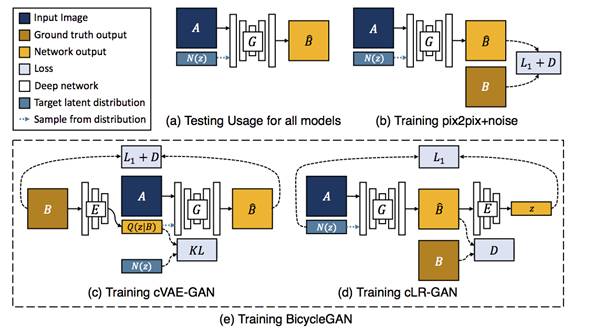
图2:概览:(a)所用方法的测试时的流程。为了生成一个样例输出,首先从一个已知分布中随机采样隐编码z(例如,标准正态分布)。生成器将输入图像(蓝色)和隐编码样本z映射到生成的输出样本(黄色)。(b)pix2pix+noise基准方法,包含一个与A对应的额外的输入B。(c)cVAE-GAN (and cAE-GAN)首先从ground truth目标图像B开始并将它编码到隐空间中。然后生成器试图将输入图像A连同样本z逆映射到原始图像B。(d)cLR-GAN从一个已知的分布中随机采样隐编码,利用这个编码将A映射到输出B,然后试图从输出中重建隐编码。(e)我们的混合BicycleGAN方法综合考虑了两个方面的约束。
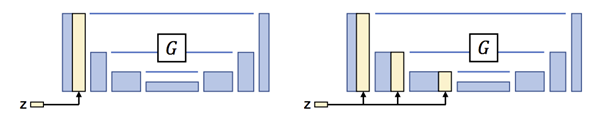
图3:将z注入到生成器的可选方案。隐编码z通过空间复制和连接被注入到生成器网络中。我们有两个选择:左边是注入到输入层,右边是注入到编码器的每一个中间层。

图4:结果输出样例,展示了我们的混合BicycleGAN的输出结果。左边一列展示了输入图像。第二列展示了ground truth 输出。最后四列展示了随机生成的样例。我们在下列情况下展示该方法的输出结果:夜景->白天,边缘->鞋子,边缘->手包,地图->卫星图。模型和更多示例可从下面链接中获得:https://junyanz.github.io/BicycleGAN.

图5:方法的定性对比。我们将输出结果与不同方法在lables->facades数据集上的实验效果对比。BicycleGAN方法提供的结果是逼真且多样的。
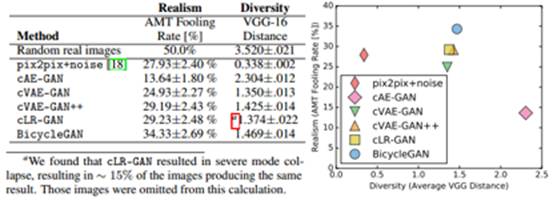
图6:真实性与多样性。我们使用VGG-16空间中的平均特征距离来测量多样性,使用在五层之间的余弦距离进行求和,真实性通过在Google maps-> satellites 任务中使用real vs. faske Amazon Mechanical Turk进行测试。Pix2pix+noise基准方法的产生结果多样性差。只用cAE-GAN方法在采样期间生成大量人工的结果。混合BicycleGAN方法融合了cVAE-GAN 和Clr-GAN,产生了更加逼真的效果并保持了多样性。
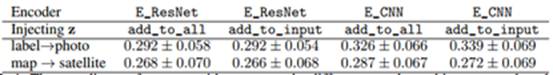
表1:不同方法和编码器结构对于注入z的编码性能。这里展示的是重建损失的值。

图7:不同隐编码z的长度在label->facades上的结果。
▌结论
总之,针对在条件生成环境下的模式崩溃问题,我们已经评估了一些解决方法。我们发现,通过结合多个目标来鼓励隐空间和输出空间之间的双射映射,我们获得了更加逼真和多样化的结果。
我们看到很多在未来工作中有趣的方向,包括强制在隐空间上的分布形式,这些分布能对语义上有意义的属性进行编码,以允许用户控制参数进行图像到图像的转换
▌效果对比
pix2pix 只能生成一个图片
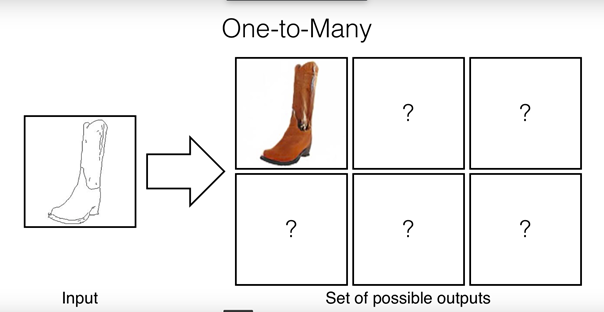
BicycleGAN在保持准确性的同时可以生成多个风格的图片

BicycleGAN
论文地址:https://arxiv.org/pdf/1711.11586.pdf
代码地址:https://github.com/junyanz/BicycleGAN/
项目主页:https://junyanz.github.io/BicycleGAN/
pix2pix
主页:https://phillipi.github.io/pix2pix/
特别提示-Toward Multimodal Image-to-Image Translation论文下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“BicycleGAN” 就可以获取论文pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域24个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!




