图像分区域合成,这个新方法实现了人脸的「精准整容」
选自arXiv
作者:Peihao Zhu等
机器之心编译
参与:熊猫、杜伟
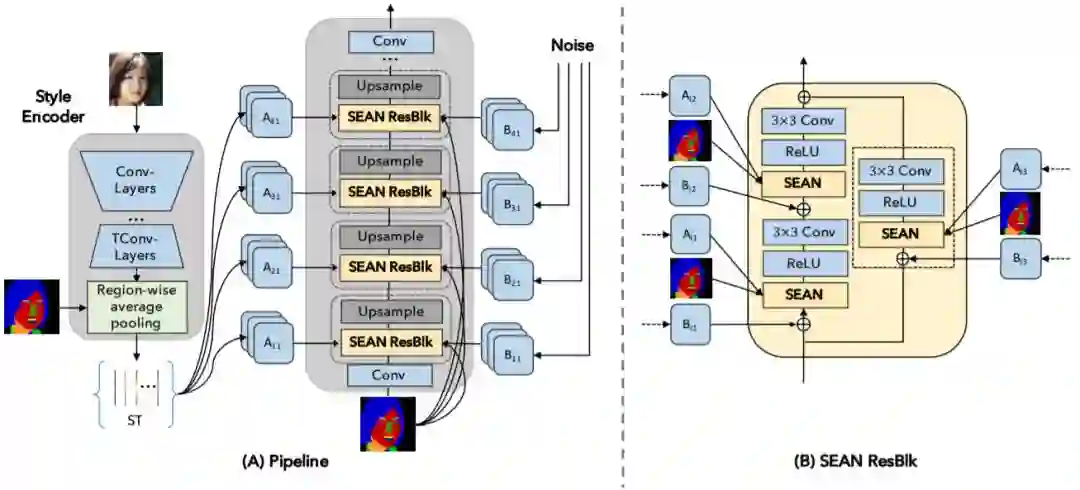
图像合成是近来非常热门的研究领域,世界各地的研究者为这一任务提出了许多不同的框架和算法,只为能合成出更具真实感的图像。阿卜杜拉国王科技大学和卡迪夫大学的研究者近日提出了一种新改进方案 SEAN,能够分区域对合成图像的内容进行控制和编辑(比如只更换眼睛或嘴),同时还能得到更灵活更具真实感的合成结果。有了这个技术,修图换眼睛时不用再担心风格不搭了。


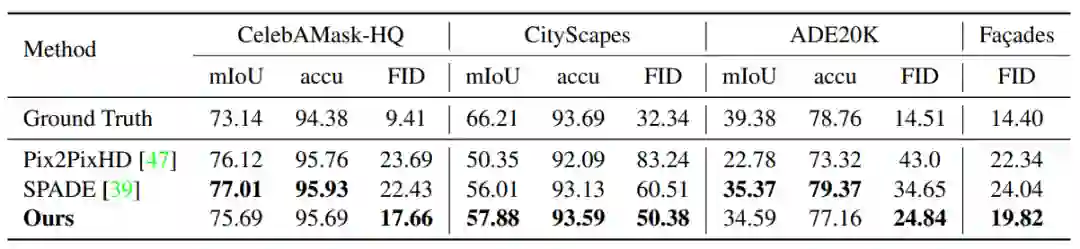
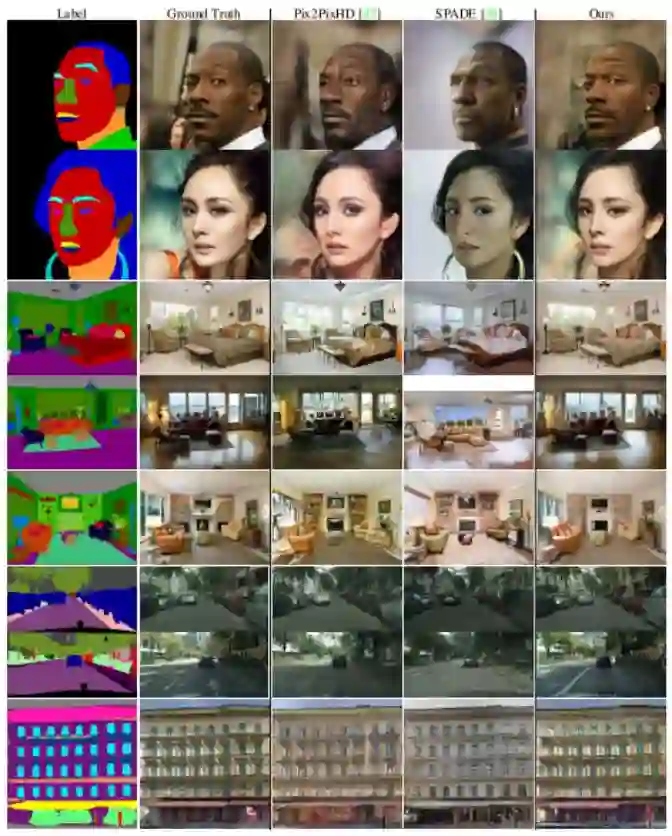
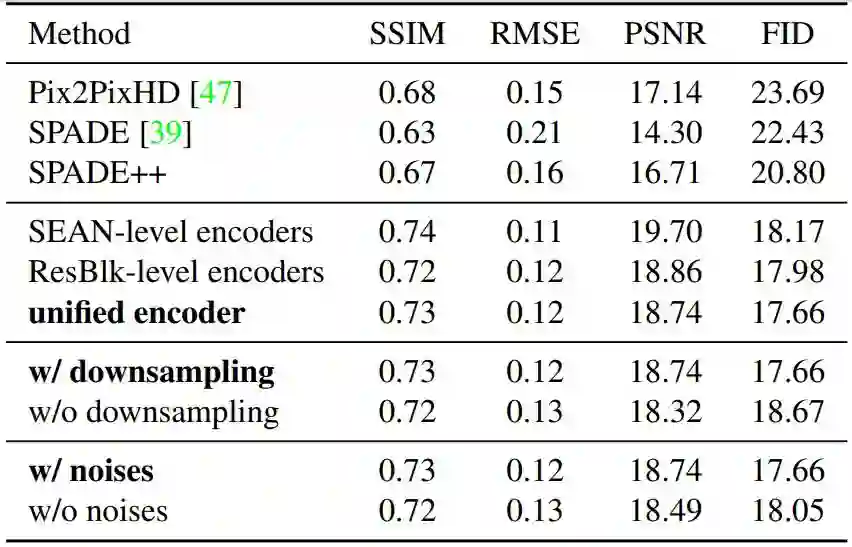
首先,SEAN 能提升条件 GAN 合成的图像的质量;
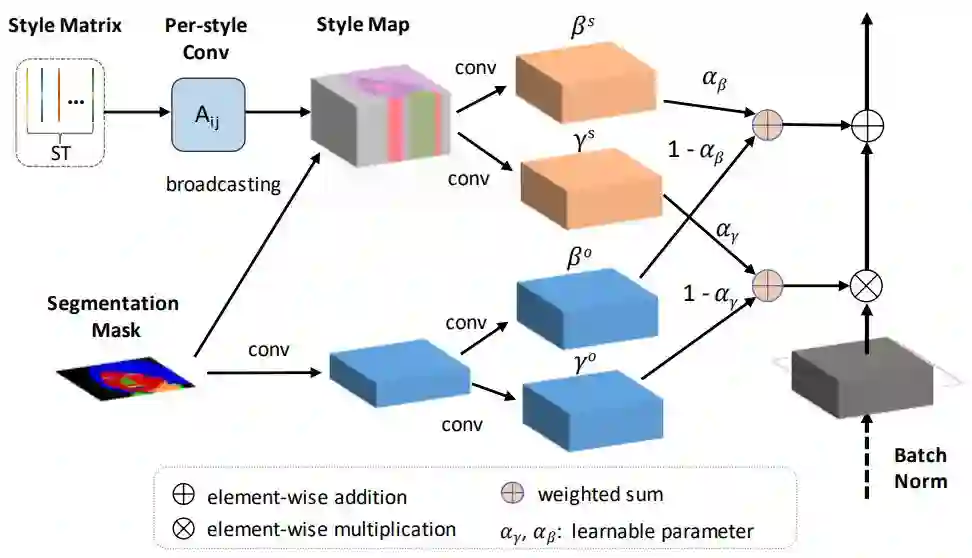
其次,SEAN 能改善每个区域的风格编码,使得重建的图像可以在 PSNR 和视觉观察指标上与输入的风格图像更相似;
最后,SEAN 允许用户为每个语义区域选择一种不同风格的输入图像。这能使图像编辑得到质量更高的结果,并提供比当前最佳方法更好的控制力。





登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文