【北京大学】CVPR 2020 | PQ-NET:序列化的三维形状生成网络


关键词:shape modeling, generative model


导读
本文是计算机视觉领域顶级会议 CVPR 2020 入选论文《PQ-NET:序列化的三维形状生成网络(PQ-NET: A Generative Part Seq2Seq Network for 3D Shapes)》的解读。
论文地址:https://arxiv.org/abs/1911.10949
代码库:https://github.com/ChrisWu1997/PQ-NET

引言
三维形状物体的生成是计算机图形学和计算机视觉领域的一个重要问题。图形学关注三维物体的建模,而计算机视觉关注如何推断,如从单张图片的输入,对应三维物体的形状。近年来,很多工作开始使用深度神经网络结合不同的三维表达方式来实现三维形状的生成,如体素(voxel),点云(point clouds),三角网格(mesh)以及隐式曲面表达(implicit function)。大部分此类工作生成的是非结构化的三维物体,但是结构化的表达对于感知和理解三维物体是很重要的,如物体不同组件的构成、关系等。
在这个工作里,我们设计了一个深度神经网络,通过顺序部件装配(sequential part assembly)的方式来表达和生成三维物体。简单来说,我们把这样的部件装配序列看成一个”句子”,这个“句子”的每一个“单词”描述了一个部件及其空间位置,类似说一句话一样来生成三维模型。在这个意义上,我们的工作部分受到语法分析的启发:一个句子既可以被看成一个由单词构成的线性结构(linear),也可以被看成由嵌套的短语构成的层级结构(hierarchical)。在三维物体结构表达的情景下,先前的工作 [1,2,3] 采用层级的部件组合(从整体到局部的树状结构),而我们采用线性的部件组合。
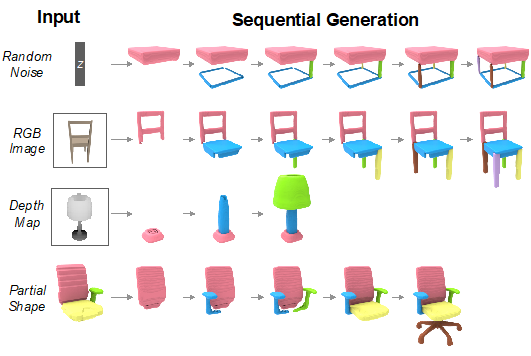
Shape generation vis Sequential part assembly
顺序部件组装的三维形状生成
方法
我们的模型,PQ-NET,是基于一个 Seq2Seq 自编码器(Seq2Seq autoencoder)来实现顺序部件组装和三维物体表征的。给定一个由多个部件构造的三维物体,我们将其表示为一个由多个向量构成的序列,每个向量对应一个部件,由一个表达这个部件的几何的特征向量和一个表达其大小和相对偏移的6维向量连接所得。表达部件的几何的特征向量是通过一个事先训练好的隐式表达自编码器(implicit function based autoencoder)[4] 所提取的。
因为每个三维物体所包含的部件个数可能是不同的,所以上述部件序列的长度是不定的。因此我们选用递归神经网络(RNN)将输入序列编码到一个固定大小的隐空间,随后解码出来重建输入序列,同时每一步输出一个标志符来判断是否停止。
输出序列每一步所包含的几何特征再进一步解码生成每个部件的几何,最后通过得到的每个部件的变换参数(大小、位移)将部件组装成完整的三维物体。由于我们采用隐式曲面表达来表征三维几何,所以最后生成的几何可以是任意分辨率的,从而能够得到高质量的结构化三维物体。
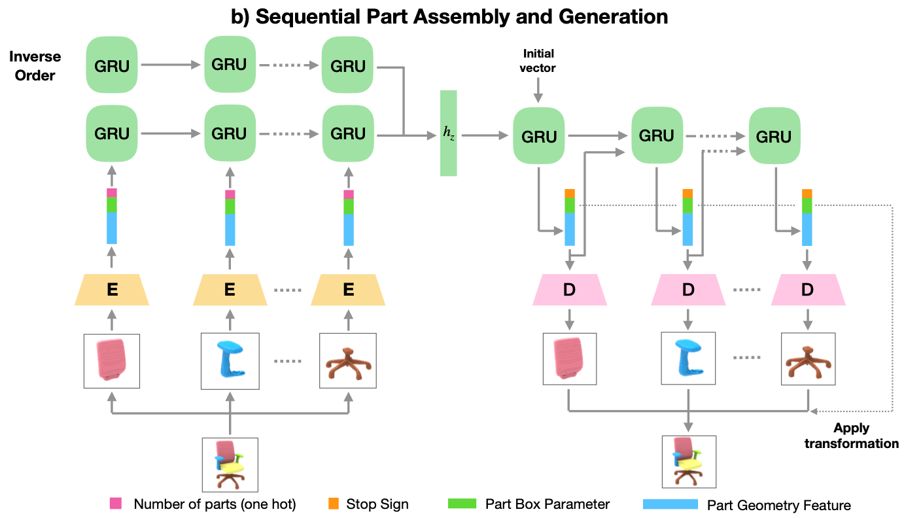
Network architecture
网络结构
结果与应用
模型学习到的隐空间,作为结构化三维形状的一种表达,使得我们能够进行随机生成、单视角重建、形状补全等多项应用。
对于三维形状的随机生成,我们在隐空间上训练一个 WGAN [5] 将采样自正态分布的噪声向量映射到模型学习到的三维形状隐空间,生成的隐向量再通过解码器解码成部件的序列,最终组合成完整的三维形状。另外,三维形状在隐空间的差值所生成的几何展现出了平滑而有意义的过渡。
对于单视角重建,我们另外单独训练一个二维卷积网络建立一个从输入图像空间到 PQ-NET 的隐空间的映射,即将输入图像映射到其所对应三维物体的隐向量。我们的实验尝试了输入图像是 RGB 图片或者是深度图的情况,并与其他方法进行了对比。

Random generation
随机生成

Latent space interpolation
隐空间插值
讨论
在这篇文章中,我们提出了 PQ-NET,一个基于序列化部件组装的三维形状表达和生成网络,以线性结构而非层级结构来表达结构化的三维形状。PQ-NET 一个最大的缺点是它并没有输出各个部件之间的关系,例如对称、相邻等。这些关系更容易通过层级结构 [1,2,3] 来表达,但代价是需要足够多的标注数据。总的来说,线性结构 vs 层级结构这两种表达的优缺点是值得再深入探究的,尤其是在三维形状的生成学习这个情景下。此外,PQ-NET 作为一个序列式的生成模型,采用了数据集里所提供的默认部件顺序。然而我们通过实验发现部件的顺序会对最终生成效果产生影响,如何定义和选取一个最优的线性表达顺序也是一个有趣的问题。
参考文献
[1] Y. Wang, K. Xu, J. Li, H. Zhang, A. Shamir, L. Liu, Z. Cheng, and Y. Xiong. Symmetry hierarchy of man-made objects. Computer Graphics Forum, 30(2), 2011.
[2] J. Li, K. Xu, S. Chaudhuri, E. Yumer, H. Zhang, and L. Guibas. Grass: Generative recursive autoencoders for shape structures. ACM Trans. on Graph. (SIGGRAPH), 2017.
[3] K. Mo, P. Guerrero, L. Yi, H. Su, P. Wonka, N. Mitra, and L. J. Guibas. Structurenet: Hierarchical graph networks for 3d shape generation. ACM Trans. on Graph. (SIGGRAPH Asia), 2019.
[4] Z. Chen and H. Zhang. Learning implicit fields for generative shape modeling. IEEE CVPR, 2019.
[5] I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville. Improved training of wasserstein gans. NIPS 2017.
IEEE Conference on Computer Vision and Pattern Recognition(IEEE CVPR)是计算机视觉领域国际顶级会议(CCF A类),每年举办一次。CVPR 2020将于2020年6月16-18日在美国西雅图举行。

图文 | 吴润迪
Visual Computing and Learning (VCL)
可视计算与学习实验室
Visual Computing and Learning
可视计算与学习实验室隶属北京大学前沿计算研究中心,在陈宝权教授带领下,围绕图形学、三维视觉、可视化及机器人等领域展开科学研究,坚持跨学科前沿技术探索、视觉艺术和技术融合两条主线,长期与顶级国际团队深度合作,并积极进行产业化实践与推广。

欢迎扫码关注课题组最新动态
微信号:PKU_VCL_lab






