漫谈概率 PCA 和变分自编码器

作者丨知乎DeAlVe
学校丨某211硕士生
研究方向丨模式识别与机器学习
介绍
主成分分析(PCA)和自编码器(AutoEncoders, AE)是无监督学习中的两种代表性方法。
PCA 的地位不必多说,只要是讲到降维的书,一定会把 PCA 放到最前面,它与 LDA 同为机器学习中最基础的线性降维算法,SVM/Logistic Regression、PCA/LDA 也是最常被拿来作比较的两组算法。
自编码器虽然不像 PCA 那般在教科书上随处可见,但是在早期被拿来做深度网络的逐层预训练,其地位可见一斑。尽管在 ReLU、Dropout 等神器出现之后,人们不再使用 AutoEncoders 来预训练,但它延伸出的稀疏 AutoEncoders,降噪 AutoEncoders 等仍然被广泛用于表示学习。2017 年 Kaggle 比赛 Porto Seguro’s Safe Driver Prediction 的冠军就是使用了降噪 AutoEncoders 来做表示学习,最终以绝对优势击败了手工特征工程的选手们。
PCA 和 AutoEncoders 都是非概率的方法,它们分别有一种对应的概率形式叫做概率 PCA (Probabilistic PCA) 和变分自编码器(Variational AE, VAE),本文的主要目的就是整理一下 PCA、概率 PCA、AutoEncoders、变分 AutoEncoders 这四者的关系。
先放结论,后面就围绕这个表格展开:
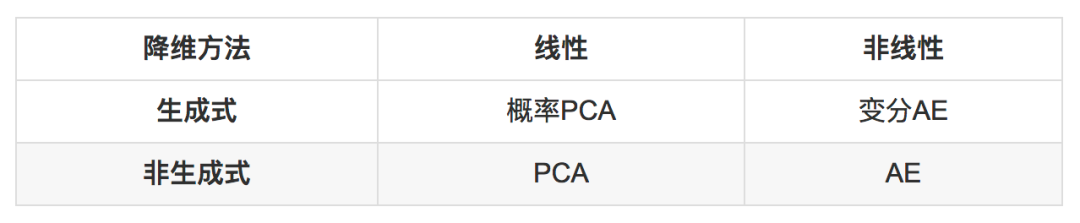
降维的线性方法和非线性方法
降维分为线性降维和非线性降维,这是最普遍的分类方法。
PCA 和 LDA 是最常见的线性降维方法,它们按照某种准则为数据集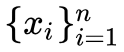
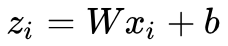
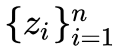
非线性降维的两类代表方法是流形降维和 AutoEncoders,这两类方法也体现出了两种不同角度的“非线性”。流形方法的非线性体现在它认为数据分布在一个低维流形上,而流形本身就是非线性的,流形降维的代表方法是两篇 2000 年的 Science 论文提出的:多维放缩(multidimensional scaling, MDS)和局部线性嵌入(locally linear embedding, LLE)。不得不说实在太巧了,两种流形方法发表在同一年的 Science 上。
AutoEncoders 的非线性和神经网络的非线性是一回事,都是利用堆叠非线性激活函数来近似任意函数。事实上,AutoEncoders 就是一种神经网络,只不过它的输入和输出相同,真正有意义的地方不在于网络的输出,而是在于网络的权重。
降维的生成式方法和非生成式方法
两类方法
降维还可以分为生成式方法(概率方法)接非生成式方法(非概率方法)。
教科书对 PCA 的推导一般是基于最小化重建误差或者最大化可分性的,或者说是通过提取数据集的结构信息来建模一个约束最优化问题来推导的。事实上,PCA 还有一种概率形式的推导,那就是概率 PCA,PRML 里面有对概率 PCA 的详细讲解,感兴趣的读者可以去阅读。需要注意的是,概率 PCA 不是 PCA 的变体,它就是 PCA 本身,概率 PCA 是从另一种角度来推导和理解 PCA,它把 PCA 纳入了生成式的框架。
设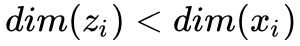
降维的非生成式方法不需要概率知识,而是直接利用数据集
降维的生成式方法认为数据集
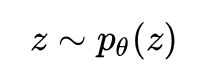
再对这个依赖关系进行建模:
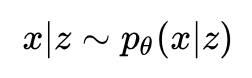
有了这两个公式,我们就可以表达出随机变量 x 的分布:
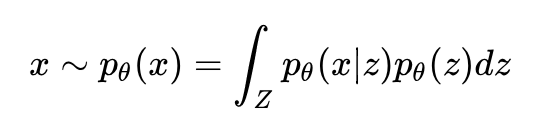
随后我们利用数据集
回想一下降维的定义:降维就是给定一个高维样本 xi ,给出对应的低维表示 zi ,这恰好就是 p(z|x) 的含义。所以我们只要应用 Bayes 定理求出这个概率即可:
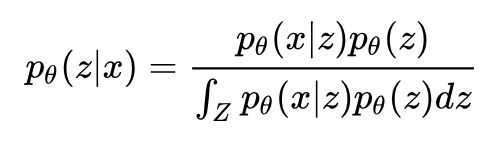
这样我们就可以得到每个样本点 xi 上的 z 的分布 p(z|x=xi) ,可以选择这个分布的峰值点作为 zi,降维就完成了。
Q:那么问题来了,生成式方法和非生成式方法哪个好呢?
A:当然是非生成式方法好了,一两行就能设定完,君不见生成式方法你设定了一大段?
应该会有很多人这样想吧?事实也的确如此,上面这个回答在一定意义上是正确的。如果你只是为了对现有的数据
那么,在什么情况下,或者说什么需求下,生成式方法是更好的选择更好呢?答案就蕴含在“生成式”这个名称中:在需要生成新样本的情况下,生成式方法是更好的选择。
生成式方法的应用场景
相似图片生成就是一种最常见的应用场景,现在我们考虑生成 MNIST 风格的手写体数字。假设 xi 代表一张图片,
最容易想到的方法就是:对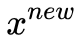
是不是看起来很简单,然而 x 的维度太高(等于 MNIST 的分辨率, 28×28=784 ),每一维中包含的信息又十分有限,直接对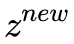
。
这样做当然也是可以的,但是依然存在严重的问题。上面的方法相当于把新样本生成拆分成了降维、KDE 和采样这三个步骤。降维这一步骤可以使用 PCA 或者 AutoEncoders 等方法,这一步不会有什么问题。
存在严重问题的步骤是 KDE 和采样。回想一下 KDE 其实是一种懒惰学习方法,每来一个样本 x ,它就会计算一下这个样本和数据集中每一个样本 xi 的核距离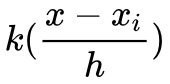
这就意味着我们需要把 z 所属的空间划分成网格,估计每个网格点上的密度,才能近似得到 p(z) ,计算复杂度是 O(n*grid_scale),而 grid_scale 关于 z 的维数是指数级的,这个计算复杂度是十分恐怖的。即使得到了近似的 p(z) ,从这样一个没有解析形式的分布中采样也是很困难的,依然只能求助于网格点近似。因此,KDE 和采样这两步无论是计算效率还是计算精度都十分堪忧。
这时候就要求助于生成式方法了。注意到生成式方法中建模了 pθ(z) 和 pθ(x|z),一旦求出了参数 θ,我们就得到了变量 z 的解析形式的分布。只要从 pθ(z) 中采样出一个,再取
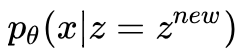
,新样本生成就完成了。
在需要生成新样本时,非生成式方法需要对 z 的概率分布进行代价巨大的数值逼近,然后才能从分布中采样;生成式方法本身就对 z 的概率分布进行了建模,因此可以直接从分布中进行采样。所以,在需要生成新样本时,生成式方法是更好的选择,甚至是必然的选择。
概率PCA和变分AutoEncoders
下面简单整理一下这四种降维方法。注意一些术语,编码=降维,解码=重建,原数据=观测变量,降维后的数据=隐变量。
PCA
原数据:
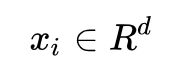
编码后的数据:
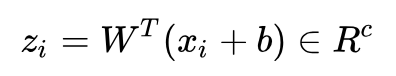
解码后的数据:
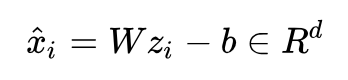
重建误差:
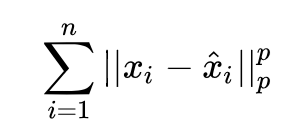
最小化重建误差,就可以得到 W 和 b 的最优解和解析解,PCA 的求解就完成了。
补充说明:
PCA 中的 p=2 ,即最小化二范数意义下的重建误差,如果 p=1 的话我们就得到了鲁棒 PCA (Robust PCA)。而最小化误差的二范数等价于对高斯噪声的 MLE,最小化误差的一范数等价于对拉普拉斯噪声的 MLE。
因此,PCA 其实是在假设存在高斯噪声的条件下对数据集进行重建,这个高斯误差就是我们将要在下面概率 PCA 一节中提到的 ϵ。你看,即使不是概率 PCA,其中也隐含着概率的思想。
编码和解码用到的 W 和 b 是一样的,即编码过程和解码过程是对称的,这一点与下面要讲的 AutoEncoders 是不同的。
求解上述最优化问题可以得到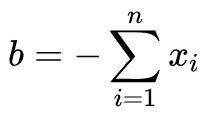
既然我们已经知道求出来的截距就是样本均值,所以干脆一开始就对样本进行中心化,这样在使用 PCA 的时候就可以忽略截距项 b 而直接使用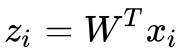
AutoEncoders
原数据:
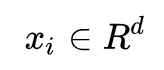
编码后的数据:
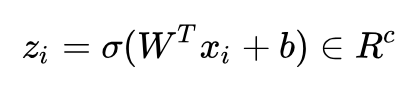
解码后的数据:
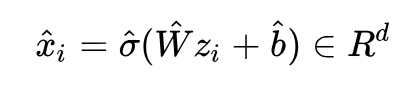
重建误差:
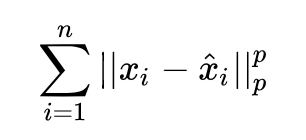
最小化重建误差,利用反向传播算法可以得到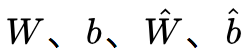
补充说明: 这里可以使用任意范数,每一个范数都代表我们对数据的一种不同的假设。为了和 PCA 对应,我们也取 p=2。
σ(·) 是非线性激活函数。AutoEncoder 一般都会堆叠多层,方便起见我们只写了一层。
W 和完全不是一个东西,这是因为经过非线性变换之后我们已经无法将样本再用原来的基 W 进行表示了,必须要重新训练解码的基
。甚至,AutoEncoders 的编码器和解码器堆叠的层数都可以不同,例如可以用 4 层来编码,用 3 层来解码。
概率PCA
隐变量边缘分布:
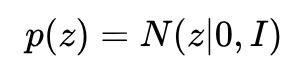
观测变量条件分布:
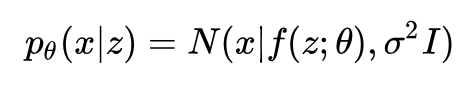
确定函数:
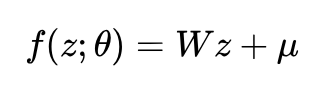
x 的生成过程:

因为 p(z) 和 pθ(x|z) 都是高斯分布,且 pθ(x|z) 的均值 f(z;θ) = Wz+μ 是 z 的线性函数,所以这是一个线性高斯模型。线性高斯模型有一个非常重要的性质: pθ(x) 和 pθ(z|x) 也都是高斯分布。千万不要小瞧这个性质,这个性质保证了我们能够使用极大似然估计或者EM算法来求解PCA。
如果没有这个性质的话,我们就只能借助变分法(变分 AE 采用的)或者对抗训练(GAN 采用的)来近似 pθ(x) 和 pθ(z|x)$ 了。有了这个优秀的性质之后,我们至少有三种方法可以求解概率 PCA:
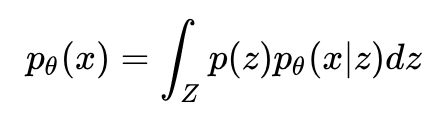
是一个形式已知,仅参数未知的高斯分布,因此可以用极大似然估计来求解 θ。
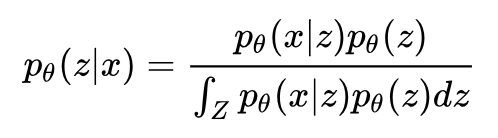
也是一个形式已知,仅参数未知的高斯分布,因此可以用 EM 算法来求解 θ,顺便还能得到隐变量 zi 。
如果你足够无聊,甚至也可以引入一个变分分布 qΦ(z|x) 来求解概率 PCA,不过似乎没什么意义,也算是一种方法吧。
一旦求出了 θ,我们就得到了所有的四个概率:
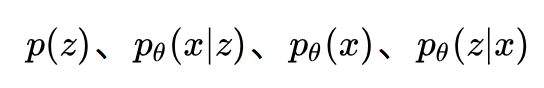
有了这四个概率,我们就可以做这些事情了:
1. 降维:给定样本 xi ,就得到了分布 pθ(z|x=xi) ,取这个分布的峰值点 zi 就是降维后的数据;
2. 重建:给定降维后的样本 zi ,就得到了分布 pθ(x|z=zi),取这个分布的峰值点 xi 就是重建后的数据;
3. 生成:从分布 p(z) 中采样一个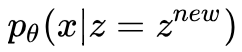
4. 密度估计:给定样本 xi ,就得到了这一点的概率密度 pθ(x=xi) 。
PCA 只能做到 1 和 2,对 3 和 4无力,这一点我们已经分析过了。
Q:为什么隐变量要取单位高斯分布(标准正态分布)?
A:这是两个问题。
subQ1:为什么要取高斯分布?
subA1:为了求解方便,如果不取高斯分布,那么 pθ(x) 有很大的可能没有解析解,这会给求解带来很大的麻烦。还有一个原因,回想生成新样本的过程,要首先从 p(z) 中采样一个,高斯分布采样简单。
subQ2:为什么是零均值单位方差的?
subA2:完全可以取任意均值和方差,但是我们要将 p(z) 和 pθ(x|z) 相乘,均值和方差部分可以挪到 f(z;θ) 中,所以 p(z) 的均值和方差取多少都无所谓,方便起见就取单位均值方差了。
Q:pθ(x|z) 为什么选择了高斯分布呢?
A:因为简单,和上一个问题的一样。还有一个直觉的解释是 pθ(x|z) 认为 x 是由 f(z:θ) 和噪声 ϵ 加和而成的,如果 ϵ 是高斯分布的话,恰好和 PCA 的二范数重建误差相对应,这也算是一个佐证吧。
Q:pθ(x|z) 的方差为什么选择了各向同性的而不是更一般的 ∑ 呢?
A:方差可以选择一般的 ∑ ,但是个参数一定会给求解带来困难,所导出的方法虽然也是线性降维,但它已经不是 PCA 了,而是另外的方法(我也不知道是什么方法)。方差也可以选择成一个的各向异性的对角阵 λ,这样只有 d 个参数,事实上这就是因子分析,另一种线性降维方法。只有当方差选择成各向同性的对角阵
时,导出来的方法才叫主成分分析,这个地方 PRML 里有介绍。
变分AutoEncoders
隐变量边缘分布:
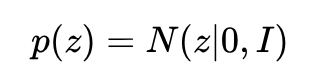
观测变量条件分布:
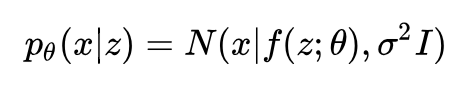
确定函数:
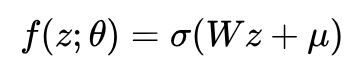
x 的生成过程:

因为 f(z;θ) 是 z 的非线性函数,所以这不再是一个线性高斯模型。观测变量的边缘分布:
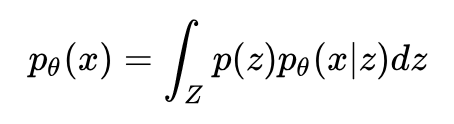
没有解析形式。这就意味着我们无法直接使用极大似然估计来求解参数 θ。更加绝望的是,隐变量的后验分布:
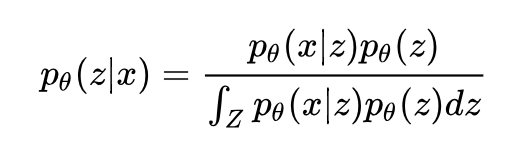
也没有解析形式(这是当然,因为分母没有解析形式了)。这就意味着我们也无法通过 EM 算法来估计参数和求解隐变量。
那么,建出来的模型该怎么求解呢?这就需要上变分推断(Variational Inference),又称变分贝叶斯(Variational Bayes)了。本文不打算细讲变分推断,仅仅讲一下大致的流程。
变分推断会引入一个变分分布 qΦ(z|x) 来近似没有解析形式的后验概率 pθ(z|x) 。在变分 AE 的原文中,作者使用了 SGD 来同时优化参数 θ 和 Φ。一旦求出了这两个参数就可以得到这些概率:
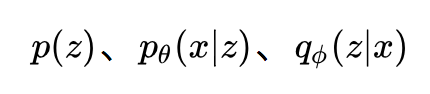
注意因为 pθ(x) 和 pθ(z|x) 没有解析形式,所以即使求出了 θ 我们也无法获得这两个概率。但是,正如上面说的, qΦ(z|x) 就是 pθ(z|x) 的近似,所以需要用pθ(z|x) 的地方都可以用 qΦ(z|x) 代替。
有了这三个概率,我们就可以做这些事情了:
1. 降维:给定样本 xi ,就得到了分布 qΦ(z|x=xi) ,取这个分布的峰值点 zi 就是降维后的数据;
2. 重建:给定降维后的样本 zi ,就得到了分布 pθ(x|z=zi),取这个分布的峰值点 xi 就是重建后的数据;
3. 生成:从分布 p(z) 中采样一个
与概率 PCA 不同的是,这里无法解析地得到 pθ(xi) ,进行密度估计需要进行另外的设计,通过采样得到,计算代价还是比较大的,具体步骤变分 AE 的原文中有介绍。
AutoEncoders 只能做到 1 和 2,对 3 无力。
对比
1. 从 PCA 和 AutoEncoders 这两节可以看出,PCA 实际上就是线性 Autoencoders。两者无论是编码解码形式还是重建误差形式都完全一致,只有是否线性的区别。线性与否给优化求解带来了不同性质:PCA 可以直接得到最优的解析解,而 AutoEncoders 只能通过反向传播得到局部最优的数值解。
2. 从概率 PCA 和变分 AutoEncoders 这两节可以看出,概率 PCA 和变分 AutoEncoders 的唯一区别就是 f(z;θ) 是否是 z 的线性函数,但是这个区别给优化求解带来了巨大的影响。在概率 PCA 中,f(z;θ) 是线性的,所以我们得到了一个线性高斯模型,线性高斯模型的优秀性质是牵扯到的 4 个概率都是高斯分布,所以我们可以直接给出边缘分布和编码分布的解析形式,极大似然估计和 EM 算法都可以使用,一切处理都非常方便。
在变分AutoEncoders中,f(z;θ) 是非线性的,所以边缘分布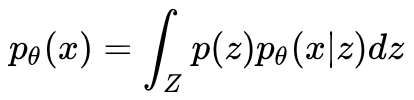
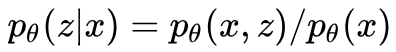
3. 从 PCA 和概率 PCA 两小节可以看出,PCA 和概率 PCA 中 x 都是 z 的线性函数,只不过概率 PCA 显式地把高斯噪声 ϵ 写在了表达式中;PCA 没有显式写出噪声,而是把高斯噪声隐含在了二范数重建误差中。
4. 从 AutoEncoders 和变分 AutoEncoders 这两节可以看出,AE 和 VAE 的最重要的区别在于 VAE 迫使隐变量 z 满足高斯分布 p(z)=N(z|0,I) ,而 AE 对 z 的分布没有做任何假设。
这个区别使得在生成新样本时,AE 需要先数值拟合 p(z) ,才能生成符合数据集分布的隐变量,而 VAE 直接从 N(z|0,I) 中采样一个 z ,它天然就符合数据集分布。事实上,这是因为在使用变分推断进行优化时,VAE 迫使 z 的分布向 N(z|0,I) 靠近,不过本文中没有讲优化细节,VAE 的原文中有详细的解释。
5. PCA 求解简单,但是都是线性降维,提取信息的能力有限;非线性的 AE 提取信息的能力强,但是求解复杂。要根据不同的场景选择不同的降维算法。
6. 要生成新样本时,不能选择 PCA 或 AE,而是要选择概率 PCA 或 VAE。
总结
本文将降维按照是否线性、是否生成式划分,将 PCA、概率 PCA、AutoEncoders 和变分 AutoEncoders 纳入了这个划分框架中,并分析了四种算法的内在联系。

点击以下标题查看其他相关文章:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看最新论文推荐



