视频 | 论文最爱的变分自编码器( VAE),不了解一下?
AI 科技评论按:喜欢机器学习和人工智能,却发现埋头苦练枯燥乏味还杀时间?这里是,雷锋字幕组编译的 Arxiv Insights 专栏,从技术角度出发,带你轻松深度学习。
原标题: Variational Autoencoders
翻译 | 赵萌 陈世杰 字幕 | 凡江 整理 | 吴璇 林尤添
今天视频内容主要围绕变分自动编码器展开。
首先介绍一般的自动编码器,对于自动编码器,它是输入某种数据,例如说图片或者高维向量,只要运行起来,数据通过神经网络运算就会被尽量压缩成更小的特征值。

这个过程有两个主要部分组成。
第一部分叫做编码器:编码器只是一层层的,它们可以是完全连接的层或者是卷积层。卷积层把输入数据压缩成特征值,这就比输入的数据具有更低的维度,这个就是bottleneck(瓶颈)。然后从bottleneck开始再一次用完全连接层或者卷积层来重构输入数据。
然后是训练的第二个部分:自动编码器会简单地根据解码网络重构数据,并简单计算重构损失。然后通过输入数据跟输出数据进行逐个像素之间的对比,我们可以创建一个损失函数然后训练网络来压缩图片。显然你可以使用全连接的简单编码器,但你也可以用卷积层置换出来,比如在处理图片或者音频的时候。这样做的作用是,当训练一个卷积网络去编码,解码一堆图像,实际上在创建一种全新的压缩算法。

如果把这项技术用于MNIST手写数字识别那将会很有趣,你会看到一些隐藏的特征值节点实际上学到了什么。如果我们改变隐含层特征规模,我们只用2个特征,意味着网络中间的bottleneck只有2个变量,似乎我们能够重构它们,但它们失真严重。失真的原因是你强行把整个图片所有的信息压缩成仅有的2个变量,那当你重构的时候就会失去一些细节。如果用更高维度的隐含层就可以重构一个更加清晰,更具锐度的图片,但在bottleneck里需要更多信息。
在自动编码器里有一些小技巧可以用来实现一些奇妙的东西。想象一下,本来是普通的MNIST手写数字识别的数据集,它清晰又明了,但加入一系列噪音以后,再对噪音图像进行计算,经过编码网络和bottleneck然后尝试重构图像,但不是重构噪音的图像,而是重构原始的清晰图像。用这些噪音跟清晰的数字训练这个网络,让编码器准确地得到噪音的边缘,这就是我们所说的降噪自动编码器。
举个例子,在一个无噪音输入图像中简单截取一个矩形区域删去这个区域,把这个图像输入网络里,尝试重构这个原始的完整图像,这个技术就是所谓的神经网络修复。也就是说你可以选取一小部分图像然后删掉再要求网络重构在原来的图像里是什么东西,用这个方法你可以做一些简单的事情例如移除图像水印,而且当你在拍一部电影的时候你也可以用这个网络移除入镜的汽车。
在有了常规自动编码器的基本概念之后,接下来介绍一下变分自动编码器。变分自动编码器的作用不是重构一个输入的图像,变成固定的向量,也不是把输入数据变成某种分布。在变分自动编码器里有一点不同的就是,你的常规深度向量C被两个独立的向量代替,一个代表分布的平均值,另一个代表分布的标准偏差,你需要一个向量联通。所以你的编码网络唯一要做的就是在分布里提取样本输入解码器。然后训练变分自动编码器的损失函数。

函数实际上包括2部分,第一部分代表重构损失这几乎跟自动编码器一样,只是多了个期望值运算符,因为我们要从分布里采样。损失函数的另一部分是相对熵,需要确定的是要学习的分布跟一般正态分布的情况不要差太远,然后尝试让你隐含层的数据分布平均值接近0标准差接近1。
在进行下一步之前,看一下使用变分自动编码器能得到的可见结果。有一类新的变分自动编码器有很多有价值的结果,它们叫分离变分自动编码器。分离的含义是,当你想确定在隐含层分布中不同神经节点的差异时,会发现它们不相关,因为它们都在学习关于输入数据不同的东西。所以为了实现这一步,你唯一要改变的就是在损失函数里加一个超参数,衡量这个相对熵能在损失函数里占多大分量,所以在分离版本里自动编码器将会只用一个有价值的特别的隐藏参数,如果对压缩没价值就仍然依照着原来的模式。

作者在 Deepmind 实验室环境用的变分自动编码器,让你看到三维世界里一个 agent 发挥了作用,它们压缩输入图像,在两个隐藏空间里能看到 agent,它们会重构这个空间,但你也可以开始改变隐藏变量然后看看对重构有什么影响。结果就是,如果你用分离变分自动编码器改变隐藏变量,实际上相当于一些非常有解释性的东西。能看到改变第一个隐藏变量,实际上改变了楼面的颜色,但仅此而已,然后另一个隐藏变量对应于转向左边还是转向右边甚至能改变旋转量,跟对象的特征 agent 形成了对比。如果不分离的情况下改变了任何隐藏特征值,图片里所有东西都开始燃烧这样并不知道隐藏向量正在编码什么。
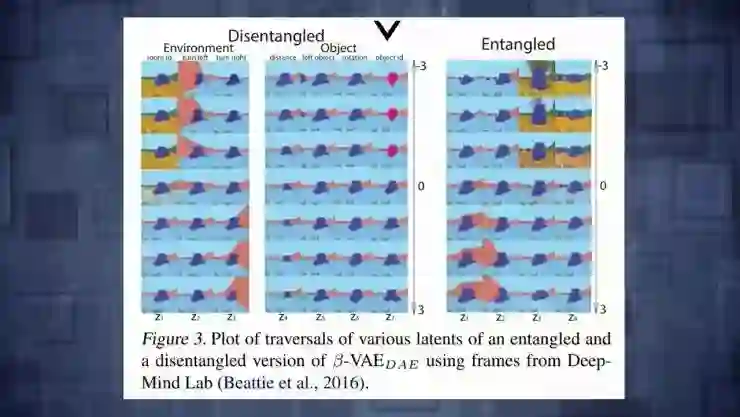
这里是另一个例子如果你改变前面提到的隐藏空间的第一个变量脸部就会旋转。如果你对普通变量做同样的事或者对脸编码,也会旋转但会看到很多其他性质也会改变。

所以分离变分自动编码器的必杀技就是,有一种网络可以从高维空间提取有用的常规特征并且利用起来,对于某些学习性任务想做的就是这些学到的特征,将对训练数据的框架形成概念。
一个人们常用的领域,例如说强化学习,因为强化学习的整个问题就是你有非常稀疏的奖励,它耗费很多时间去训练,所以通过使用这个变分自动编码器作为某种特征提取工具,希望能够真正地在隐藏层上运行agent达到压缩特征值的目的,而不是在整个输入空间所以在实践中这样做是非常平衡的。

如果你把隐藏空间分得太细你的网络就会过拟合因为你给它太多的自由,它可以学习如何重构你输入的训练数据,但它无法概念化一些在新情况下看不到的数据,另一方面,如果你分的太粗你实际上失去了许多在输入数据中准确定义的细节,它们会在很多应用中损害性能。因为最后我们希望训练一个agentagent 能够通过压缩大量信息理解世界,然后在隐藏空间学习有用的行为。
参考文献
Disentangled VAE's (DeepMind 2016)
https://arxiv.org/abs/1606.05579
Applying disentangled VAE's to RL: DARLA (DeepMind 2017)
https://arxiv.org/abs/1707.0847
Original VAE paper (2013)
https://arxiv.org/abs/1312.6114
更多文章,关注 AI 科技评论。添加雷锋字幕组微信号(leiphonefansub)为好友,备注「我要加入」,To be an Volunteer !

对了,我们招人了,了解一下?

这里有个限时拼团---机器学习之数学基础课程
3 大模块,30 个课时,高校数学系教授带班,100%学员好评。
与 100+同学一起夯实数学基础,走稳机器学习入门第一步!
限时拼团中,点击阅读原文或扫码了解详情~

┏(^0^)┛欢迎分享,明天见!



