预训练模型迁移学习
由极市、机器之心和中科创达联合举办的“2018计算机视觉最具潜力开发者榜单”评选活动,现已接受报名,杨强教授、俞扬教授等大牛嘉宾亲自评审,高通、中科创达、微众银行等大力支持,丰厚奖励,丰富资源,千万渠道,助力您的计算机视觉工程化能力认证,提升个人价值及算法变现。极市与您一起定义自己,发现未来~点击阅读原文即可报名~
摘要: 本文通过使用Keras及一个预训练模型的实例,教你如何通过迁移学习快速简便地解决图像分类问题。
如何快速简便地解决图像分类问题呢?本文通过使用Keras及一个预训练模型的实例,教你如何通过迁移学习来解决这个问题。

深度学习正在迅速成为人工智能应用开发的主要工具。在计算机视觉、自然语言处理和语音识别等领域都已有成功的案例。
深度学习擅长解决的一个问题是图像分类。图像分类的目标是根据一组合理的类别对指定的图片进行分类。从深度学习的角度来看,图像分类问题可以通过迁移学习的方法来解决。
本文介绍了如何通过迁移学习来解决图像分类的问题。本文中所提出的实现方式是基于Python语言的Keras。
本文结构:
1)迁移学习
2)卷积神经网络
3)预训练模型的复用
4)迁移学习过程
5)深度卷积神经网络上的分类器
6)示例
7)总结
1、迁移学习
迁移学习在计算机视觉领域中是一种很流行的方法,因为它可以建立精确的模型,耗时更短。利用迁移学习,不是从零开始学习,而是从之前解决各种问题时学到的模式开始。这样,你就可以利用以前的学习成果(例如VGG、 Inception、MobileNet),避免从零开始。我们把它看作是站在巨人的肩膀上。
在计算机视觉领域中,迁移学习通常是通过使用预训练模型来表示的。预训练模型是在大型基准数据集上训练的模型,用于解决相似的问题。由于训练这种模型的计算成本较高,因此,导入已发布的成果并使用相应的模型是比较常见的做法。
2、卷积神经网络(CNN)
在迁移学习中,常用的几个预训练模型是基于大规模卷积神经网络的(Voulodimos)。一般来说,CNN被证明擅长于解决计算机视觉方面的问题。它的高性能和易训练的特点是最近几年CNN流行的两个主要原因。
典型的CNN包括两个部分:
(1)卷积基,由卷积层和池化层的堆栈组成。卷积基的主要目的是由图像生成特征。为了直观地解释卷积层和池化层,请参阅Chollet 2017。
(2)分类器,通常是由多个全连接层组成的。分类器的主要目标是基于检测到的特征对图像进行分类。全连接层是其中的神经元与前一层中的所有激活神经元完全连接的层。
图1显示了一个基于CNN的模型体系结构。这是一个简化的版本,事实上,这种类型的模型,其实际的体系结构比我们在这里说的要复杂得多。
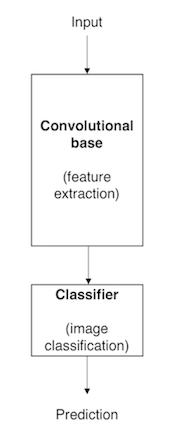
图1.基于CNN的模型体系结果
这些深度学习模型的一个重要方面是,它们可以自动学习分层的特征表示。这意味着由第一层计算的特征是通用的,并且可以在不同的问题域中重用,而由最后一层计算的特征是较特殊的,并且依赖于所选择的数据集和任务。根据Yosinski等人在2014年提出的“如果第一层的特征是通用的并且最后一层的特征是特殊的,那么网络中必定有一个从一般到特殊的转变。因此,我们的CNN的卷积基特别是它下面的层(那些更接近输入的层)适用于一般特征,而分类器部分和卷积基中一些较高的层适用于特殊的特征。
3、预训练模型的复用
当你根据自己的需要重用预训练模型时,首先要删除原始的分类器,然后添加一个适合的新分类器,最后必须根据以下的三种策略之一对模型进行微调:
(1)训练整个模型 在这种情况下, 利用预训练模型的体系结构,并根据数据集对其进行训练。如果你从零开始学习模型,那么就需要一个大数据集,和大量的计算资源。
(2)训练一些层而冻结其它的层 较低层适用的是通用特征(独立问题),而较高层适用的是特殊特征。这里,我们通过选择要调整的网络的权重来处理这两种情况。通常,如果有一个较小的数据集和大量的参数,你会冻结更多的层,以避免过度拟合。相比之下,如果数据集很大,并且参数的数量很少,那么可以通过给新任务训练更多的层来完善模型,因为过度拟合不是问题了。
(3)冻结卷积基 这种情况适用于训练/冻结平衡的极端情况。其主要思想是将卷积基保持在原始形式,然后使用其输出提供给分类器。把你正在使用的预训练模型作为固定的特征提取途径,如果缺少计算资源,并且数据集很小,或者预训练模型解决了你正要解决的问题,那么这就很有用。
图2以图表的形式说明了这三种策略。
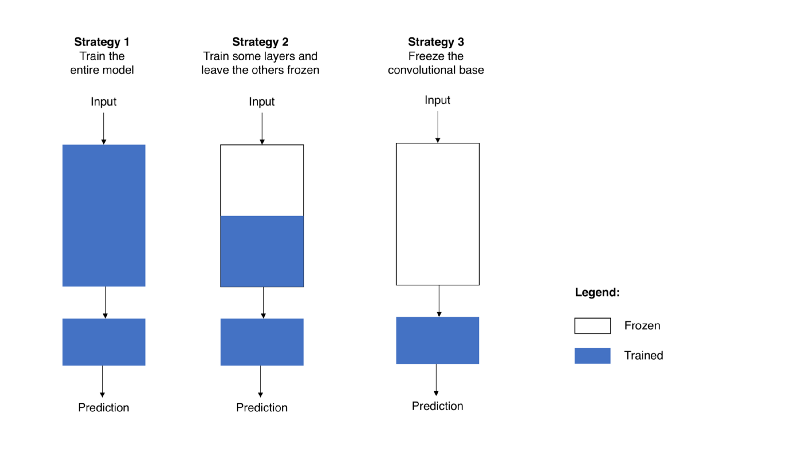
与策略3的这种直接简单的应用不同,策略1和策略2要求你小心谨慎地应对卷积部分中使用的学习率。学习率是一个超参数,它控制你调整网络权重的大小。当你正在使用基于CNN的预训练模型时,使用一个低学习率是比较明智的,因为使用高学习率会增加失去之前所积累知识的风险。假设预训练模型经过了比较好的训练,保持低学习率将确保你不会过早和过度地调整CNN权重。
4、迁移学习过程
从实践的角度来看, 整个迁移学习过程可以概括如下:
(1)选择预训练模型.
从大量的预训练模型,可以选择一个适合你要解决的问题的。如果你正在使用Keras,可以立即使用一系列模型,例如VGG、InceptionV3和ResNet5。点击这里你可以看到Keras上所有的模型
(2)根据大小相似性矩阵进行分类.
在图3中你用矩阵来控制选择,这个矩阵是根据数据集的大小,以及预训练模型被训练之后的数据集的相似性,来对计算机视觉问题进行分类的。根据经验,如果每个类的图像少于1000个,则认为是小数据集。就数据集的相似性而言,常识占了上风。例如,如果是识别猫和狗,那么ImageNet将是一个类似的数据集,因为它有猫和狗的图像。然而,如果是识别癌细胞,ImageNet就不行了。
(3)微调模型.
这里可以使用大小和相似性矩阵来指导你的选择,然后参考前面提到的重用预训练模型的三个策略。请见图4。
象限1.大数据集,但不同于预训练模型的数据集。这种情况将会让你使用策略1。因为有一个大数据集,你就可以从零开始训练一个模型。尽管数据集不同,但在实践中,利用模型的体系结构和权重,通过预训练模型对初始化模型仍然是很有帮助的;
象限2.大数据集与类似于预训练模型的数据集。在这里任何选项都有效,可能最有效的是策略2。由于我们有一个大数据集,过度拟合不应该是个问题,所以我们可以尽可能多地学习。然而,由于数据集是相似的,我们可以通过利用以前的知识来节省大量的训练工作。因此,仅对卷积基的分类器和顶层进行训练就足够了。
象限3.小数据集,不同于预训练模型的数据集,这里唯一适合的就是策略2。很难在训练和冻结的层数之间平衡。如果你涉及的太深入,那么模型就会过度拟合;如果你仅停留在模型的表面,那么你就不会学到任何有用的东西。也许,你需要比象限2更深入,并且需要考虑数据增强技术。
象限4.小数据集,但类似于预训练模型的数据集。你只需删除最后一个全连接层(输出层),并且执行预训练模型作为固定的特征提取器,然后使用结果特征来训练新的分类器。
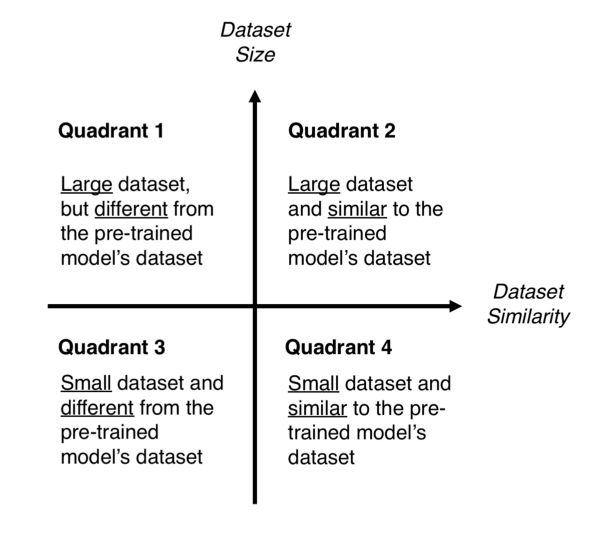
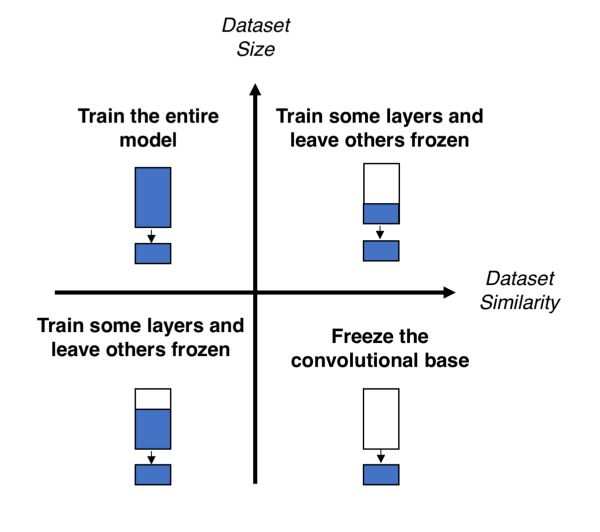
图3和图4. 尺寸相似性矩阵(上)和微调预训练模型的决策图(下)
5、深度卷积神经网络上的分类器
如前所述,由基于预训CNN的迁移学习方法得到的图像分类模型通常由以下两部分组成:
(1)卷积基,实现特征提取;
(2)分类器,通过卷积基提取的特征对输入图像进行分类;
由于在本节中我们主要关注分类器部分,所以必须首先说明可以遵循不同的方法来构建分类器:
(1)全连接层.对于图像分类问题,标准的方法是使用一组下面是softmax激活层的全连接层。softmax激活层输出每个可能的类标签上的概率分布,然后只需要根据最可能的类对图像进行分类。
(2)全局平均池化层.Lin在2013年提出了一种基于全局平均池化的方法。在这个方法中,我们没有在卷积基最上面添加全连接层,而是添加了一个全局平均池化层,并将其输出直接提供给softmax激活层。
(3)线性支持向量机.线性支持向量机(SVM)是另一种可能的方法。根据Tang在2013年所说的,可以利用卷积基在提取的特征上通过训练线性SVM分类器来提高分类精确度。SVM方法的优缺点细节可以在下文中找到。
6. 示例
6.1 准备数据
在例子中,我们将使用原始数据集的小版本,这可以更快地运行模型,适用于那些计算能力有限的任务。
为了构建小版本数据集,我们可以使用Chollet 2017所提供的代码。
# Create smaller dataset for Dogs vs. Catsimportos, shutil
original_dataset_dir = '/Users/macbook/dogs_cats_dataset/train/'
base_dir = '/Users/macbook/book/dogs_cats/data'
if not os.path.exists(base_dir):
os.mkdir(base_dir)
# Create directories
train_dir = os.path.join(base_dir,'train')
if not os.path.exists(train_dir):
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
if not os.path.exists(validation_dir):
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
if not os.path.exists(test_dir):
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir,'cats')
if not os.path.exists(train_cats_dir):
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
if not os.path.exists(train_dogs_dir):
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
if not os.path.exists(validation_cats_dir):
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
if not os.path.exists(validation_dogs_dir):
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
if not os.path.exists(test_cats_dir):
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
if not os.path.exists(test_dogs_dir):
os.mkdir(test_dogs_dir)
# Copy first 1000 cat images to train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(100)]
forfname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 cat images to validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(200, 250)]
forfname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 cat images to test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(250,300)]
forfname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy first 1000 dog images to train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(100)]
forfname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 dog images to validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(200,250)]
forfname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 dog images to test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(250,300)]
forfname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
# Sanity checks
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))6.2从卷积基中提取特征
卷积基将用于提取特征,这些特征将为我们想要训练的分类器提供输入,以便能够识别图像中是否有狗或猫。
再次把Chollet 2017提供的代码修改了一下,请看代码2。
# Extract featuresimportos, shutil
fromkeras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rescale=1./255)batch_size = 32defextract_features(directory, sample_count):features = np.zeros(shape=(sample_count, 7, 7, 512)) # Must be equal to the output of the convolutional baselabels = np.zeros(shape=(sample_count))
# Preprocess datagenerator = datagen.flow_from_directory(directory,target_size=(img_width,img_height),batch_size = batch_size,class_mode='binary')
# Pass data through convolutional basei = 0forinputs_batch, labels_batch in generator:features_batch = conv_base.predict(inputs_batch)features[i * batch_size: (i + 1) * batch_size] = features_batch
labels[i * batch_size: (i + 1) * batch_size] = labels_batch
i += 1ifi * batch_size>= sample_count:breakreturn features, labels
train_features, train_labels = extract_features(train_dir, train_size) # Agree with our small dataset sizevalidation_features, validation_labels = extract_features(validation_dir, validation_size)test_features, test_labels = extract_features(test_dir, test_size)代码2.从卷积基中提取特征。
6.3分类器
6.3.1全连接层
我们提出的第一个解决方案是基于全连接层的。在分类器中添加一组全连接层,把从卷积基中提取的特征作为它们的输入。
为了保持简单和高效,我们将使用Chollet2018上的解决方案,并稍作修改,特别地使用Adam优化器来代替RMSProp。
代码3显示了相关的代码,而图5和图6表示了学习曲线。
# Define modelfromkeras import models
fromkeras import layers
fromkeras import optimizers
epochs = 100
model = models.Sequential()
model.add(layers.Flatten(input_shape=(7,7,512)))
model.add(layers.Dense(256, activation='relu', input_dim=(7*7*512)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
# Compile model
model.compile(optimizer=optimizers.Adam(),
loss='binary_crossentropy',
metrics=['acc'])
# Train model
history = model.fit(train_features, train_labels,
epochs=epochs,
batch_size=batch_size,
validation_data=(validation_features, validation_labels))代码3.全连接层解决方案
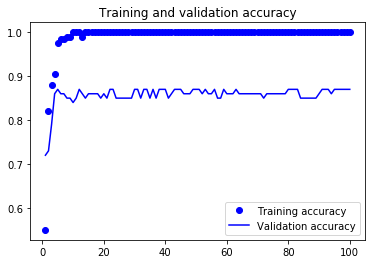
图5.全连接层方案的准确性
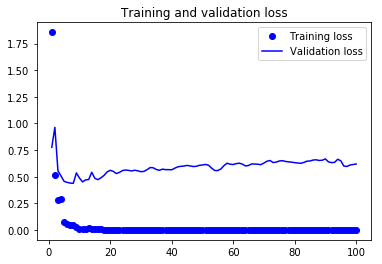
图6.全连接层方案的损失
结果简述:
(1)验证精确度约为0.85,对于给定数据集的大小,这个结果是非常不错的。
(2)这个模型过度拟合,在训练曲线和验证曲线之间有很大的差距。
(3)由于我们已经使用了dropout,所以应该增大数据集来改善结果。
6.3.2全局平均池化层
这种情况与之前的不同之处在于,我们将添加一个全局平均池化层,并将其输出提供到一个sigmoid激活层,而不是添加一组全连接层。
请注意,我们所说的是sigmoid激活层,而不是SoftMax激活层。我们正在改为sigmoid激活,因为在Keras中,为了执行二进制分类,应该使用sigmoid激活和binary_crossentropy作为损失。
代码4是构建分类器的代码。图7和图8表示所得结果的学习曲线。
# Define modelfromkeras import models
fromkeras import layers
fromkeras import optimizers
epochs = 100model = models.Sequential()model.add(layers.GlobalAveragePooling2D(input_shape=(7,7,512)))model.add(layers.Dense(1, activation='sigmoid'))model.summary()# Compile modelmodel.compile(optimizer=optimizers.Adam(),loss='binary_crossentropy',metrics=['acc'])# Train modelhistory = model.fit(train_features, train_labels,epochs=epochs,batch_size=batch_size, validation_data=(validation_features, validation_labels))代码4.全局平均池化解决方案
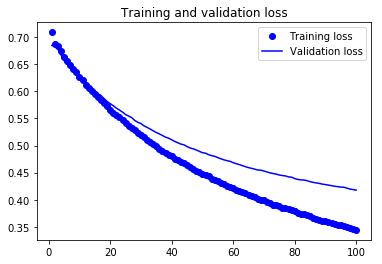
图7.全局平均池化层方案的准确性
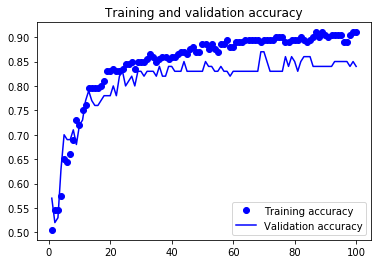
图8.全局平均池化方案的损失
结果简述:
(1)验证精确度与全连接层方案的类似;
(2)模型不像以前那样过度拟合;
(3)当模型停止训练时,损失函数的结果仍在减小,大概可以通过增加周期数来完善模型;
6.3.3 线性支持向量机
在这种情况下,我们将利用卷积基提取的特征来训练一个线性支持向量机(SVM)的分类器。
为了训练这种分类器,可以使用传统的机器学习方式。因此,我们将使用k-fold cross-validation来估算分类器的误差。由于将使用k-fold cross-validation,我们可以将训练集和验证集连接起来以扩大训练数据(像前面一样保持测试集不变)。
代码5显示了如何联系数据。
# Concatenate training and validation setssvm_features = np.concatenate((train_features, validation_features))svm_labels = np.concatenate((train_labels, validation_labels))代码 5. 数据连接
最后,我们必须要知道SVM分类器有一个超参数,它是误差项的惩罚参数C。为了优化这个超参数,我们将使用穷举的方法进行网格搜索。
代码6表示用于构建该分类器的代码,而图9表示了学习曲线。
# Build modelimportsklearn
fromsklearn.cross_validation import train_test_split
fromsklearn.grid_search import GridSearchCV
fromsklearn.svm import LinearSVC
X_train, y_train = svm_features.reshape(300,7*7*512), svm_labels
param = [{
"C": [0.01, 0.1, 1, 10, 100]
}]svm = LinearSVC(penalty='l2', loss='squared_hinge') # As in Tang (2013)clf = GridSearchCV(svm, param, cv=10)clf.fit(X_train, y_train)代码6. 线性 SVM解决方案.
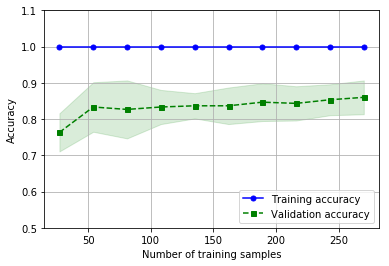
图9.线性支持向量机方案的精确度
结果简述:
(1)模型的精确度在0.86左右,类似于前一个方案;
(2)过度拟合即将出现。此外,训练精确度始终是1,这是不正常的,可以解释为过度拟合的现象;
(3)模型的精确度应随着训练样本数量的增加而提高。然而,这似乎并没有出现,这可能是由于过度拟合的原因。有趣的是,当数据集增加的时候,模型将会如何反应。
7. 总结
本文提出了迁移学习、卷积神经网络和预训练模型的概念;
定义了基本的微调策略来重新调整预训练模型;
描述了一种基于数据集的大小和相似度来决定应该使用哪种微调策略的结构化方法;
介绍了三种不同的分类器,可用于通过卷积基提取的特征上面;
为文中阐述的三个分类器中的任意一个都提供了关于图像分类的端到端的例子;
来源:我是程序员
作者:Pedro Marcelino
译者:奥特曼,审校:袁虎
原文地址:
https://towardsdatascience.com/transfer-learning-from-pre-trained-models-f2393f124751
*推荐阅读*
从人脸检测到语义分割,OpenCV预训练模型库
NIPS 2018 |谷歌大脑提出 DropBlock 卷积正则化方法,显著改进 CNN 精度
ECCV2018|ShuffleNetV2:轻量级CNN网络中的桂冠
杨强教授、俞扬教授等大牛嘉宾评审团,万元大奖,丰富资源,助力您的计算机视觉工程化能力认证,点击阅读原文即可报名“2018计算机视觉最具潜力开发者榜单”~






