干货——图像分类(上)
这是译自斯坦福CS231n课程笔记image classification notes,由课程教师Andrej Karpathy授权进行翻译。本篇教程由杜客翻译完成。非常感谢那些无偿奉献的大师,在此代表所有爱好学习者向您们致敬,谢谢!
这是斯坦福大学的课程,希望对即将入门DL的您打下基础,还是给已经处在DL届的您们巩固,都希望您们对基础知识有深入的理解。
随便分享CS231n的网址,有兴趣的朋友可以进一步去了解:http://cs231n.github.io/
图像分类
目标:这一节我们将介绍图像分类问题。
图像分类,顾名思义,是一个输入图像,输出对该图像内容分类的描述的问题。它是计算机视觉的核心,实际应用广泛。图像分类的传统方法是特征描述及检测,这类传统方法可能对于一些简单的图像分类是有效的,但由于实际情况非常复杂,传统的分类方法不堪重负。现在,我们不再试图用代码来描述每一个图像类别,决定转而使用机器学习的方法处理图像分类问题。主要任务是给定一个输入图片,将其指派到一个已知的混合类别中的某一个标签。
例子:在下图中,一个图像分类模型将一个图片分配给四个类别(cat,dog,hat,mug)标签的概率。
如图所示,图片被表示成一个大的3维数字矩阵。在下面例子中,图像分类的最终目标就是转换这个数字矩阵到一个单独的标签,例如“Cat”。 图片分类的任务是对于一个给定的图片,预测其的类别标签。
——————————————————

——————————————————
困难和挑战:对于人来说,识别猫特别简单,首先我们之前就大量接触这类图像,对其对特的特征有深入的认识,所以人类识别是简单的任务,但是对于,计算机视觉算法,那就那难于上青天。
我们在下面列举了至今计算机视觉领域遇到的困难,也是现在亟待需解决的问题:
刚体&非刚体的变化:不同类型其变化都不一样;
多视角:收集同一个物体图像,获取的角度是多变的;
尺度:在现实生活中,很多物体的尺度都是千变万化;
遮挡:目标物体可能被挡住。有时候只有物体的一小部分是可见的;
光照条件:在像素层面上,光照的影响非常大;
类内差异:一类物体的个体之间有许多不同的对象,每个都有自己的外形。
——————————————————
——————————————————

数据驱动方法:如何写一个图像分类的算法呢?怎么写一个从图像中认出猫的算法?
因此,我们采取的方法和教小孩儿看图识物类似:给模型很多图像数据,让其不断去学习,学习到每个类的特征。这就是数据驱动方法
既然第一步需要将已经做好分类标注的图片作为训练集,下面就看看训练数据集长什么样?如下图:
——————————————————

一共有4个类别的训练集。在实际中,可能有成千上万类别的物体,每个类别都会有百万的图像。
——————————————————
图像分类流程。在课程视频中已经学习过,图像分类就是输入一个元素为像素值的数组,然后给它分配一个分类标签。完整流程如下:
输入:输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集。
学习:这一步的任务是使用训练集来学习每个类到底长什么样。一般该步骤叫做训练分类器或者学习一个模型。
评价:让分类器来预测它未曾见过的图像的分类标签,并以此来评价分类器的质量。我们会把分类器预测的标签和图像真正的分类标签对比。毫无疑问,分类器预测的分类标签和图像真正的分类标签如果一致,那就是好事,这样的情况越多越好。
Nearest Neighbor分类器
作为课程介绍的第一个方法,我们来实现一个Nearest Neighbor分类器。虽然这个分类器和卷积神经网络没有任何关系,实际中也极少使用,但通过实现它,可以让读者对于解决图像分类问题的方法有个基本的认识。
图像分类数据集:CIFAR-10。一个非常流行的图像分类数据集是CIFAR-10。这个数据集包含了60000张32X32的小图像。每张图像都有10种分类标签中的一种。这60000张图像被分为包含50000张图像的训练集和包含10000张图像的测试集。在下图中你可以看见10个类的10张随机图片。
——————————————————
左边:从CIFAR-10数据库来的样本图像。右边:第一列是测试图像,然后第一列的每个测试图像右边是使用Nearest Neighbor算法,根据像素差异,从训练集中选出的10张最类似的图片。

——————————————————
假设现在我们有CIFAR-10的50000张图片(每种分类5000张)作为训练集,我们希望将余下的10000作为测试集并给他们打上标签。Nearest Neighbor算法将会拿着测试图片和训练集中每一张图片去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。上面右边的图片就展示了这样的结果。请注意上面10个分类中,只有3个是准确的。比如第8行中,马头被分类为一个红色的跑车,原因在于红色跑车的黑色背景非常强烈,所以这匹马就被错误分类为跑车了。
那么具体如何比较两张图片呢?在本例中,就是比较32x32x3的像素块。最简单的方法就是逐个像素比较,最后将差异值全部加起来。换句话说,就是将两张图片先转化为两个向量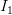
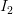
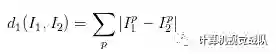
这里的求和是针对所有的像素。下面是整个比较流程的图例:
——————————————————
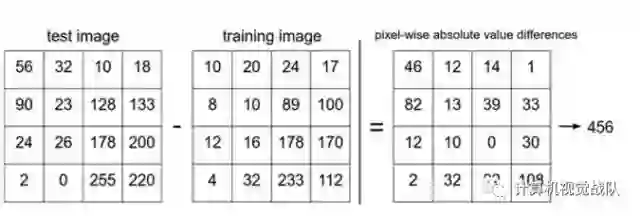
以图片中的一个颜色通道为例来进行说明。两张图片使用L1距离来进行比较。逐个像素求差值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片很是不同,那L1值将会非常大。
——————————————————
下面,让我们看看如何用代码来实现这个分类器。首先,我们将CIFAR-10的数据加载到内存中,并分成4个数组:训练数据和标签,测试数据和标签。在下面的代码中,Xtr(大小是50000x32x32x3)存有训练集中所有的图像,Ytr是对应的长度为50000的1维数组,存有图像对应的分类标签(从0到9):
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # a magic function we provide# flatten out all images to be one-dimensionalXtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072现在我们得到所有的图像数据,并且把他们拉长成为行向量了。接下来展示如何训练并评价一个分类器:
nn = NearestNeighbor() # create a Nearest Neighbor classifier classnn.train(Xtr_rows, Ytr) # train the classifier on the training images and labelsYte_predict = nn.predict(Xte_rows) # predict labels on the test images# and now print the classification accuracy, which is the average number# of examples that are correctly predicted (i.e. label matches)print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )作为评价标准,我们常常使用准确率,它描述了我们预测正确的得分。请注意以后我们实现的所有分类器都需要有这个API:train(X, y)函数。该函数使用训练集的数据和标签来进行训练。从其内部来看,类应该实现一些关于标签和标签如何被预测的模型。这里还有个predict(X)函数,它的作用是预测输入的新数据的分类标签。现在还没介绍分类器的实现,下面就是使用L1距离的Nearest Neighbor分类器的实现套路:
import numpy as npclass NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred如果你用这段代码跑CIFAR-10,你会发现准确率能达到38.6%。这比随机猜测的10%要好,但是比人类识别的水平(据研究推测是94%)和卷积神经网络能达到的95%还是差多了。点击查看基于CIFAR-10数据的Kaggle算法竞赛排行榜。
距离选择:计算向量间的距离有很多种方法,另一个常用的方法是L2距离,从几何学的角度,可以理解为它在计算两个向量间的欧式距离。L2距离的公式如下:
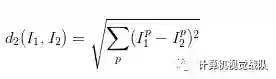
换句话说,我们依旧是在计算像素间的差值,只是先求其平方,然后把这些平方全部加起来,最后对这个和开方。在Numpy中,我们只需要替换上面代码中的1行代码就行:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))注意在这里使用了np.sqrt,但是在实际中可能不用。因为求平方根函数是一个单调函数,它对不同距离的绝对值求平方根虽然改变了数值大小,但依然保持了不同距离大小的顺序。所以用不用它,都能够对像素差异的大小进行正确比较。如果你在CIFAR-10上面跑这个模型,正确率是35.4%,比刚才低了一点。
L1和L2比较。比较这两个度量方式是挺有意思的。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。L1和L2都是在p-norm常用的特殊形式。
k-Nearest Neighbor分类器
你可能注意到了,为什么只用最相似的1张图片的标签来作为测试图像的标签呢?这不是很奇怪吗!是的,使用k-Nearest Neighbor分类器就能做得更好。它的思想很简单:与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
——————————————————

上面示例展示了Nearest Neighbor分类器和5-Nearest Neighbor分类器的区别。例子使用了2维的点来表示,分成3类(红、蓝和绿)。不同颜色区域代表的是使用L2距离的分类器的决策边界。白色的区域是分类模糊的例子(即图像与两个以上的分类标签绑定)。需要注意的是,在NN分类器中,异常的数据点(比如:在蓝色区域中的绿点)制造出一个不正确预测的孤岛。5-NN分类器将这些不规则都平滑了,使得它针对测试数据的泛化(generalization)能力更好(例子中未展示)。注意,5-NN中也存在一些灰色区域,这些区域是因为近邻标签的最高票数相同导致的(比如:2个邻居是红色,2个邻居是蓝色,还有1个是绿色)。
——————————————————
在实际中,大多使用k-NN分类器。但是k值如何确定呢?接下来就讨论这个问题。
图像分类笔记(上)完。




