基于深度学习的文本分类?
曾几何时, SVM一统江湖, Lecun见证的Vapnik和Larry Jackel的世纪之赌, 从95年坚持到2000年依然岿然不动。 但是再过10年, 到2010年, 深度学习横空出世。 SVM在图像,文本这些高维数据领域全面停滞。 反倒是Lecun的CNN网络一路挺进!

“基于深度学习的图像目标检测”提到, 在图像分类和目标检测领域基本全是CNN网络。 那么文本分类领域呢?
前言
传统机器学习时代的主流分类器主要是基于Naive Bayes,Maximum Entropy, K-NN,和SVM的。 其中分类中还有些经典特征模型:经典距离定义模型Vector Space Model(Rocchio), N-grams等等。其中SVM一直保持不错的效果!
一, 待选模型
本人尝试过使用word2vec词嵌入+Boosting和Text-CNN模型的对比, 发现效果不如Text-CNN。 或许和图像检测里面一样, Fast R-CNN比SPPNet优的一点就是整合起来联动的参数优化。 所以这里也默认, 利用词嵌入这样的2阶段的模型效果不会比端到端的联动参数学习的模型效果好。
1)Text-RNN
就是对文本看成编码后的信息流, 然后用RNN来编码:
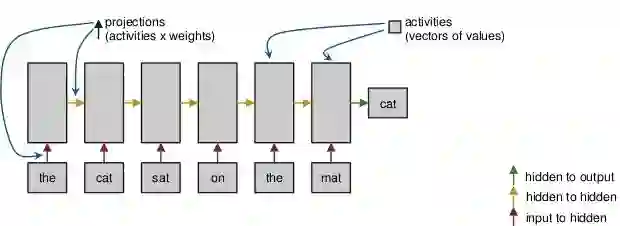
复旦大学 Recurrent Neural Network for Text Classification with Multi-Task Learning发表在了ijca2016上,目前有40次引用了。 虽然着重点在Multi-Task Learning, 但是可以参考下下。
2) Text-CNN
哈佛的PhD帅哥Yoon Kim的 “Convolutional Neural Networks for Sentence Classification” 文章引用率1700多次了。已经成为文本分类中深度学习的经典!

但是在这片2014年的文章中, CNN是基于Pretrained的Word2vec的结果去做的, 其实效果还没有完全超越SVM。
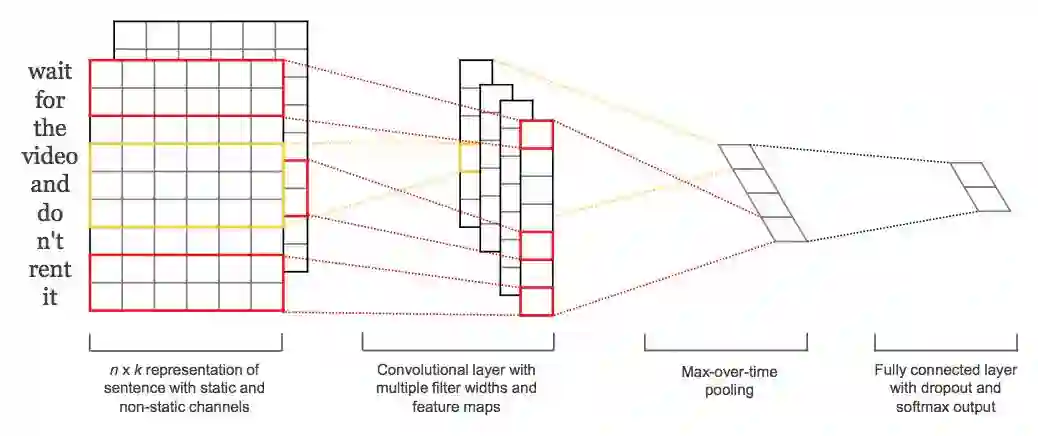
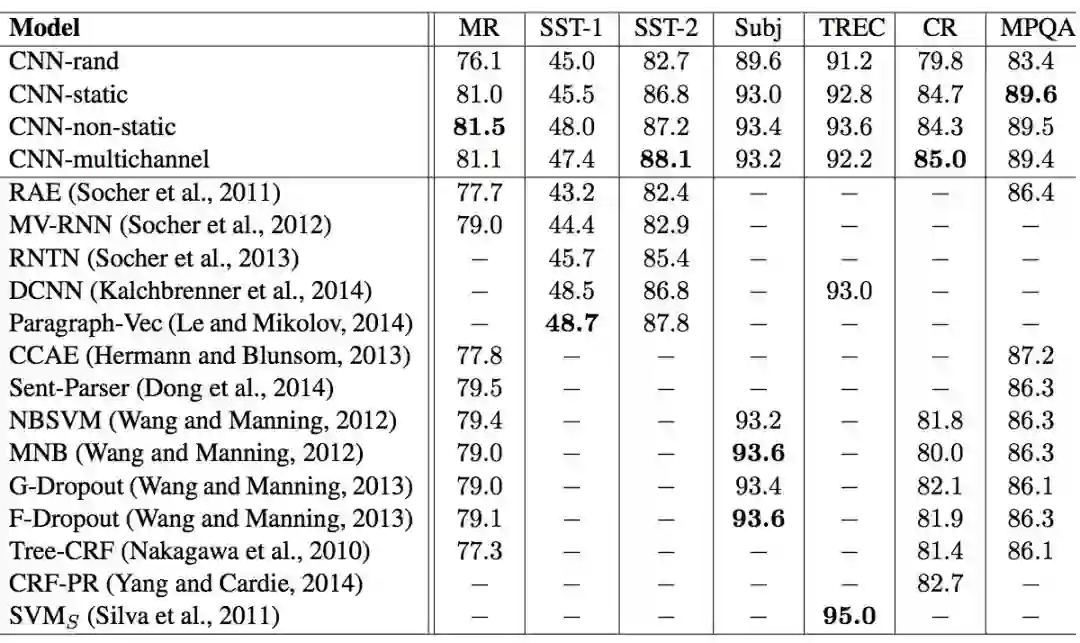
但是现在更为流行的是直接基于带参数的Embedding去做, 这样效果会更好!
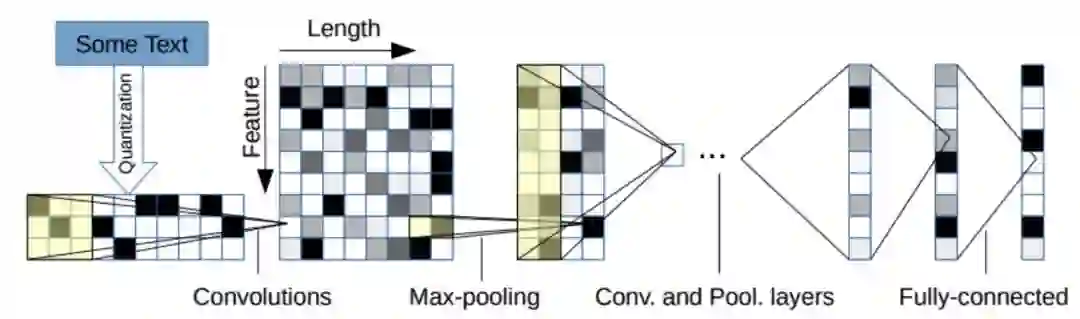
来自University of Texas at Austin的张晔,在他2016年的文章 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification, 详细介绍了一些调参数的经验,也有超过150的引用率, 自从调参数成为很好的职业(Amazon SageMaker启示录), 调参数也成为了很好的论文。

这片文章里面给出一个单层CNN进行测试典型参数的使用:
* 词嵌入维度: 300维, 主要针对预训练
* Filter大小:7的filter最优,不同数据集上最优组合不一致, 但相差不多
* Filter的个数:推荐100 ~ 600个, 最好靠近600
* 激活函数:Iden, ReLU, tanh比sigmoid,cube要好, 默认ReLU好。
* Pooling技术:推荐1-max pooling,不要用average,效果不好。
* 正则化:dropout rate不要超过0.5, l2正则化效果不明确。
最后强调下, filter大小和数量可以调一调, 其他调不调意义一般。
3)EntNet
LeCun的团队在ICLR2017上提出了Recurrent Entity Network, 简称为EntNet, 但是EntNet是为了QA问题提出来的, 对应论文为Tracking the World State with Recurrent Entity Networks, 有28次引用。
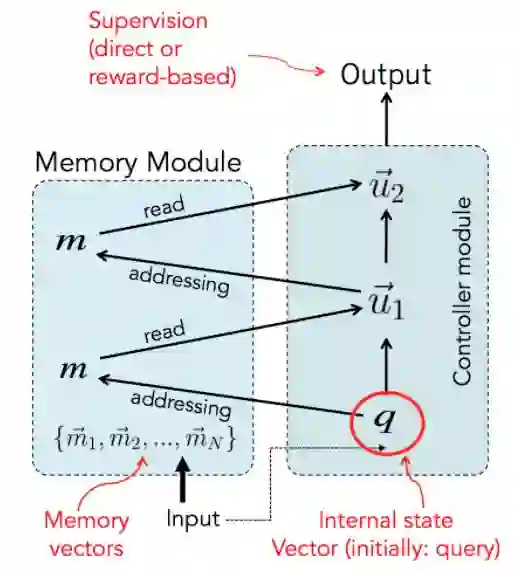
EntNet延续了Facebook基于Memory Network(MemNN)在QA问题上的模型和成功经验。 MemNN相比RNN或者LSTM来说,强调专门的外部存储来保存以前的样本。
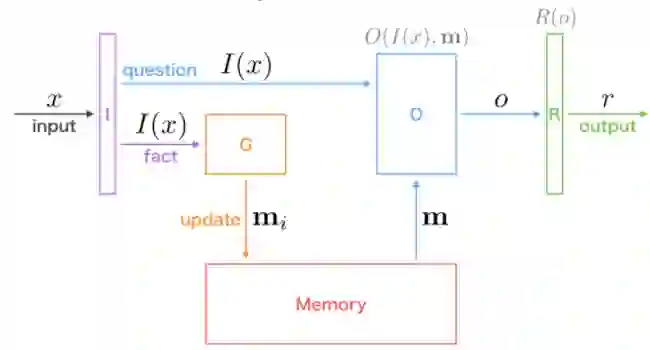
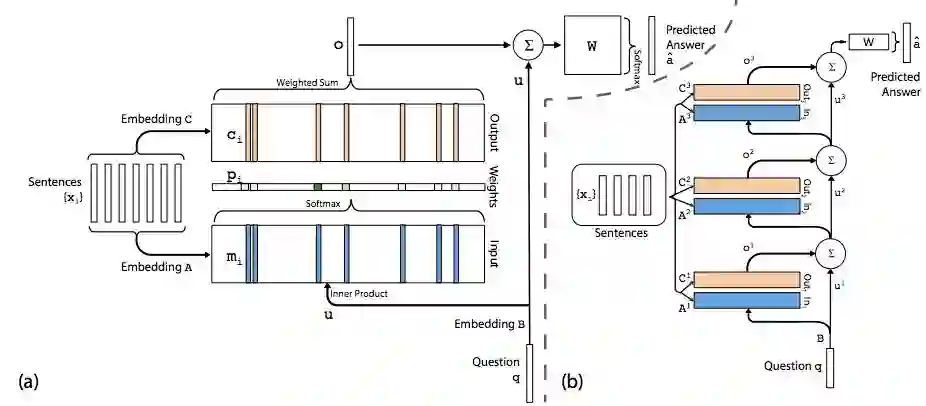
最简单的Memory实现,可以是输入数据的自己的某种特征值的表达, 譬如和问题q的点积的Softmax输出。
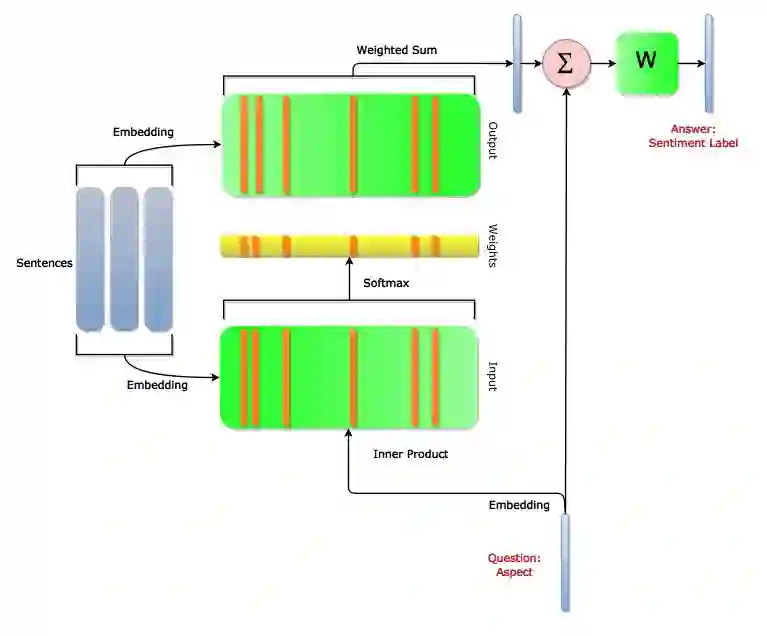
也可以变得复杂, 可以多层次迭代。
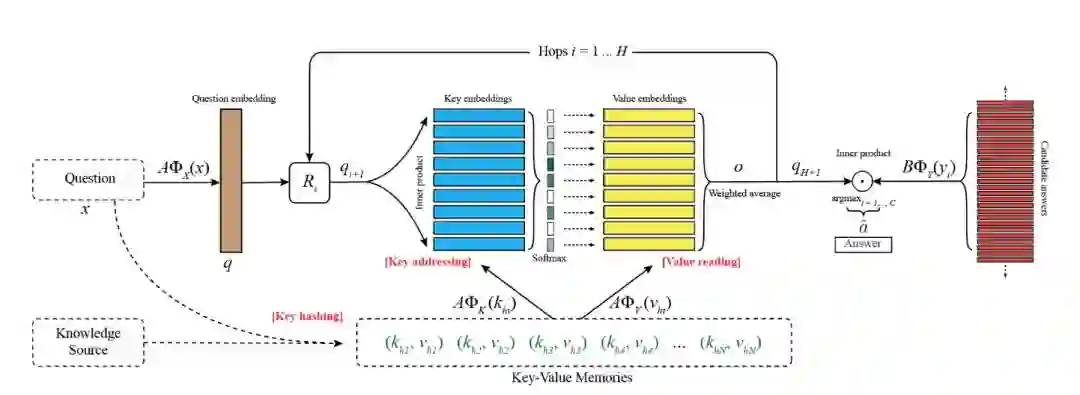
还可以更复杂, 变成KV-MemNN, 深化对问题和答案两边的记忆的存储。
也可以引入Episodic Memory Module变形成Dynamic Memory Networks(DMN)。
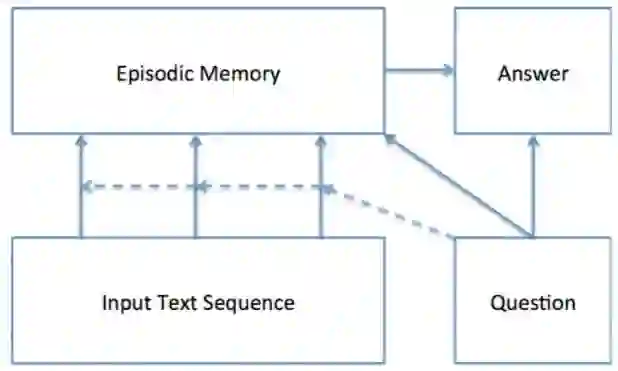
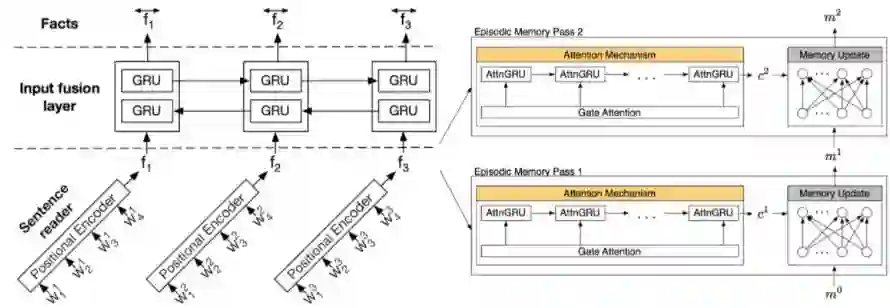
一般通过GRU的attention网络实现,并且也可以双向多通道。
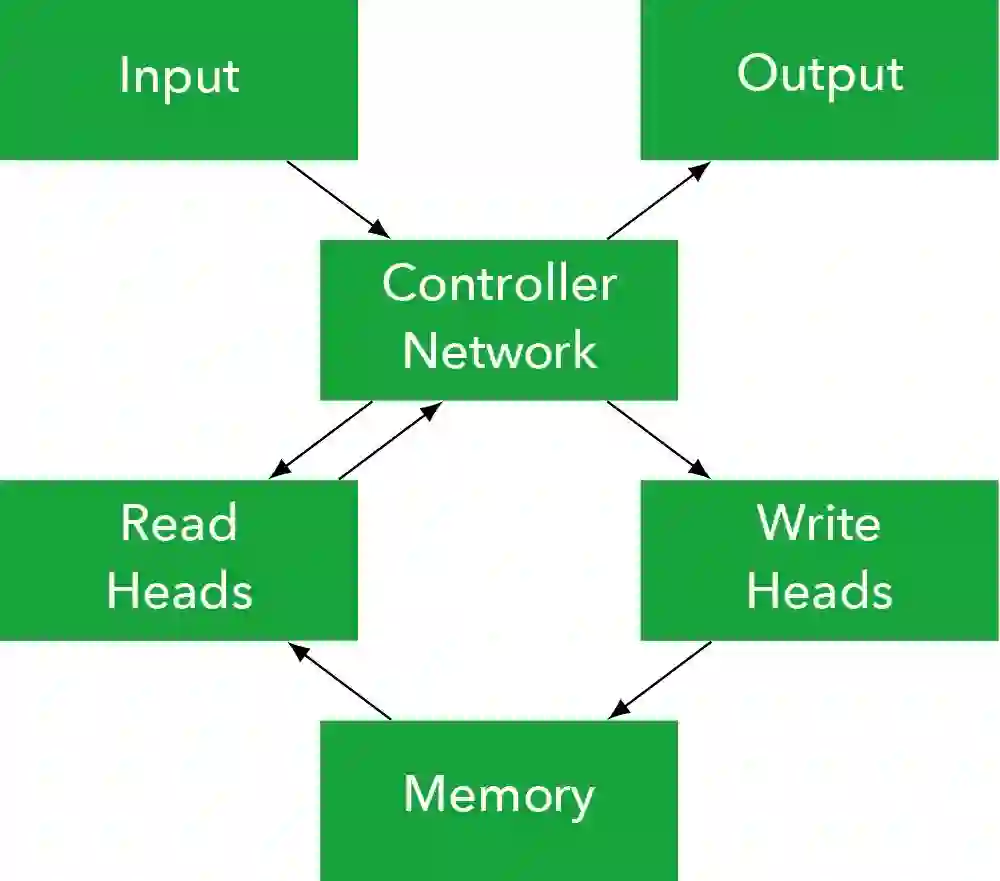
如果加上控制网络和寻址读写机制,就是Neural Turing Machines(NTM),所以NTM可以说是DMN的升级版。
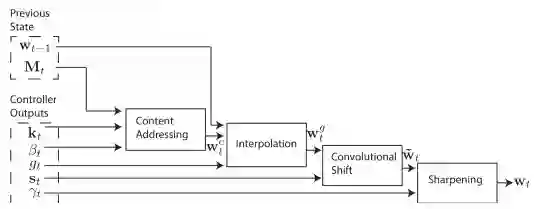
和MemNN相比, 除了记忆状态的延续, 还有控制状态的延续。
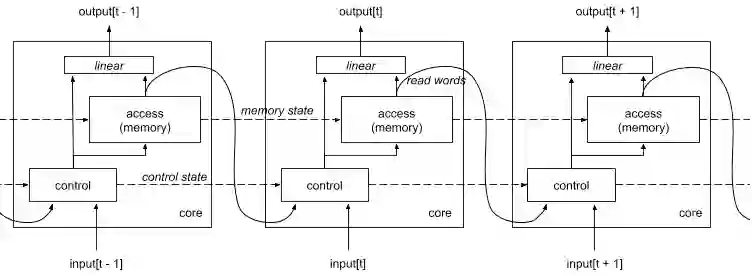
在NTM基础上细化具体的地址读写机制和记忆链接机制,就会得到Differential Neural Computer (DNC), DNC使得性能和稳定都比LSTM和MemNN好很多。
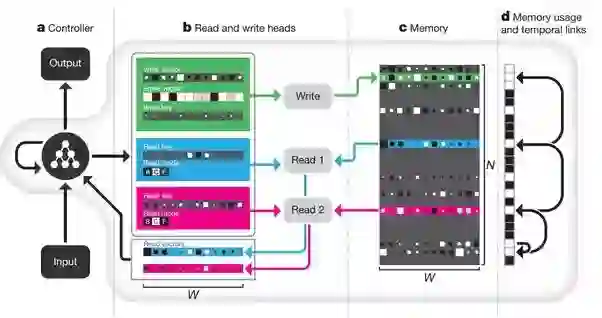
而EntNet本质就是希望达到DNC的并行模式, 能够并行更新记忆地址。
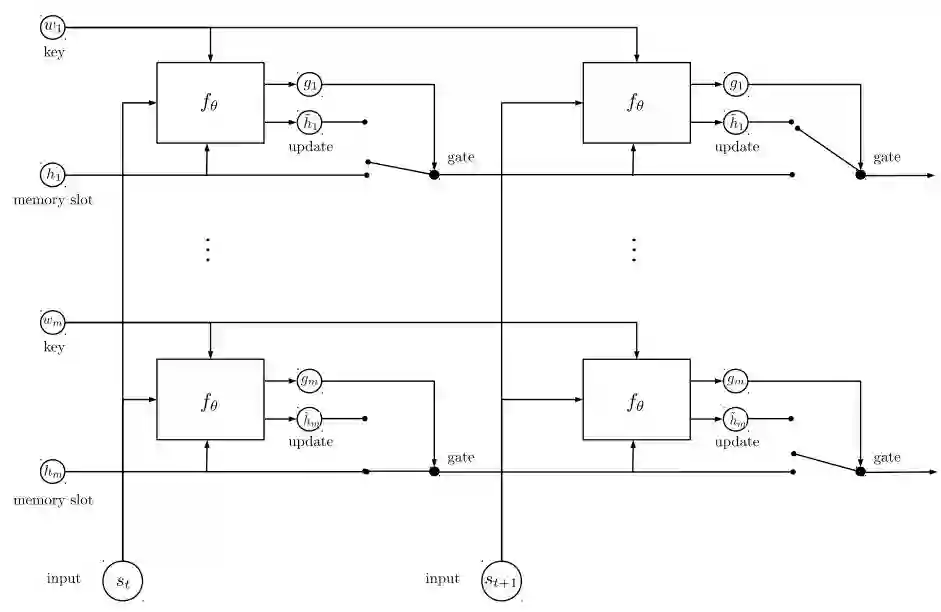
一种简单的实现就是用多个RNN并行来记录多个Memory Slot, 所以又叫Recurrent Entity。
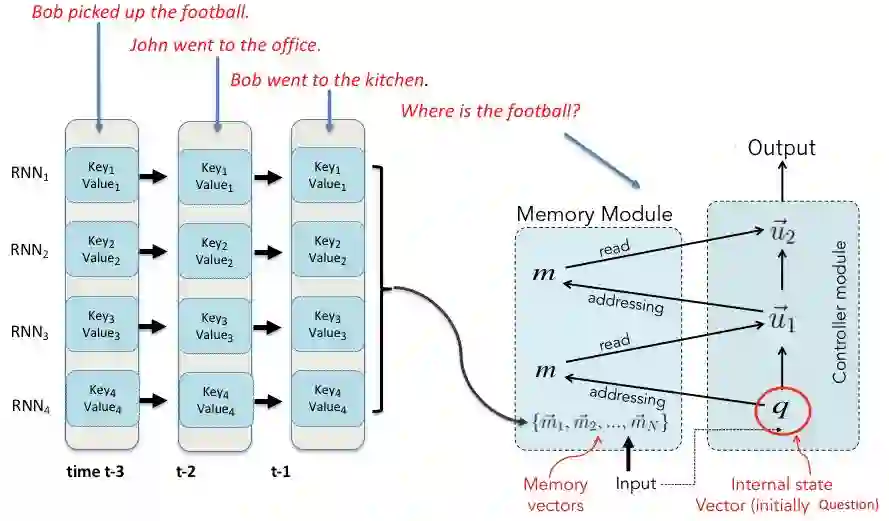
对于QA的问题, EntNet要比DNC更加稳定和准确。
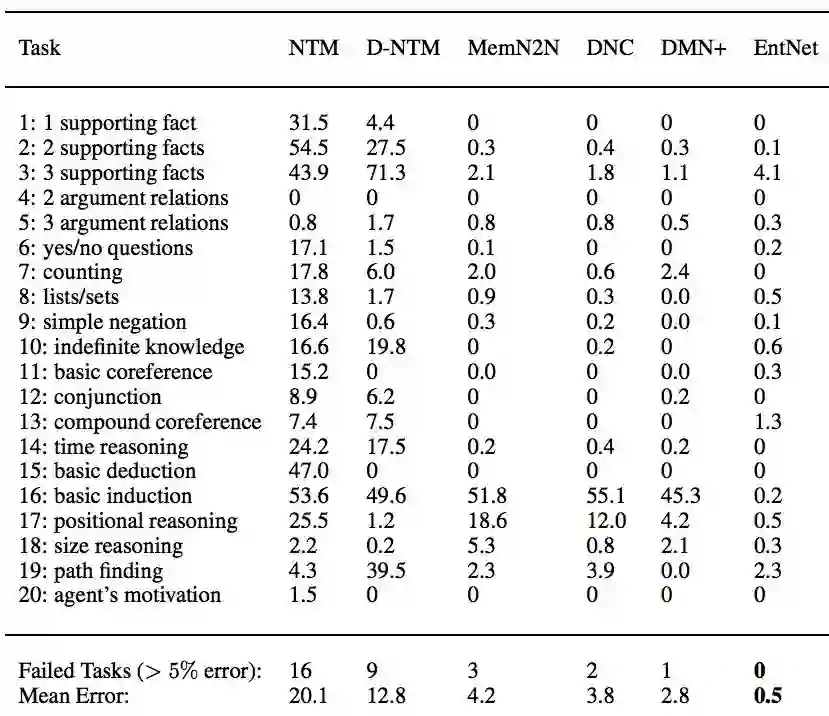
当我们把QA问题弱化到A是句子的分类标签的时候, 我们就能用到文本分类问题上, 有点点杀鸡用牛刀的感觉。
4)HAN
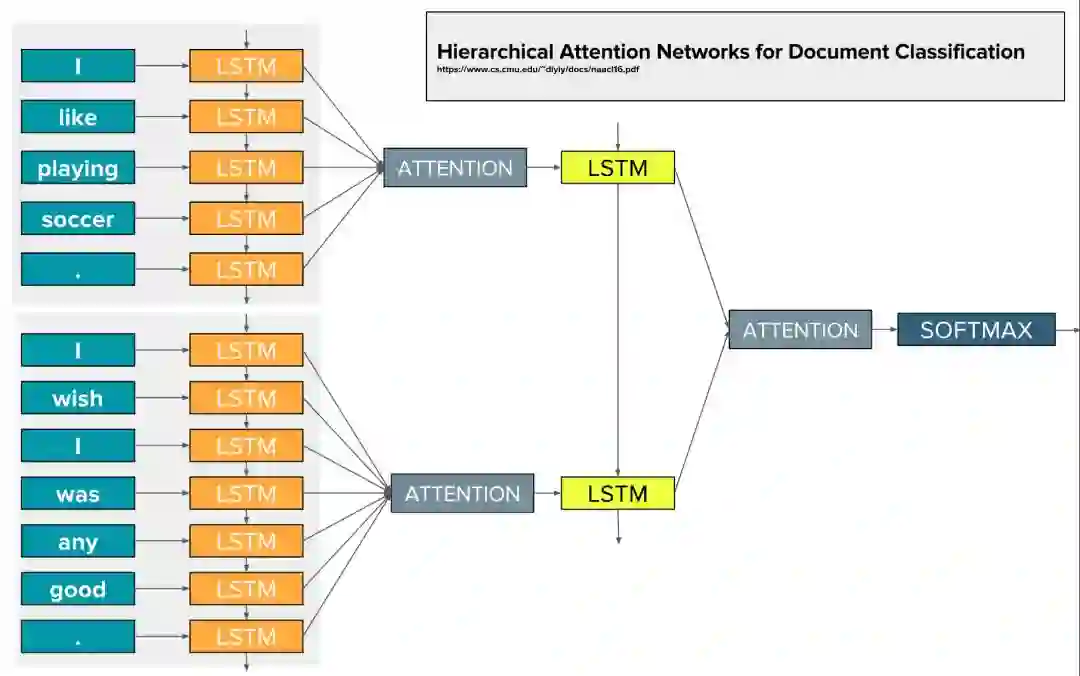
Alex Smola的团队提出了Hierarchical Attention Networks(HAN)做文本分类, 他们的论文Hierarchical Attention Networks for Document Classification发表在NAACL16上。 有接近200次的应用。
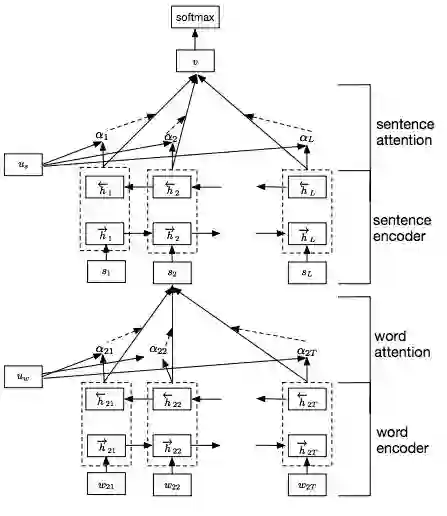
这样两层分层,就可以从字组成句子, 再进一步句子组成段落。 然后就训练分类网络Softmax。
5)RCNN
自动化所的赵军老师团队的论文Recurrent Convolutional Neural Networks(RCNN) for Text Classification, 发表在AAAI2015上, 有超过200次的引用。
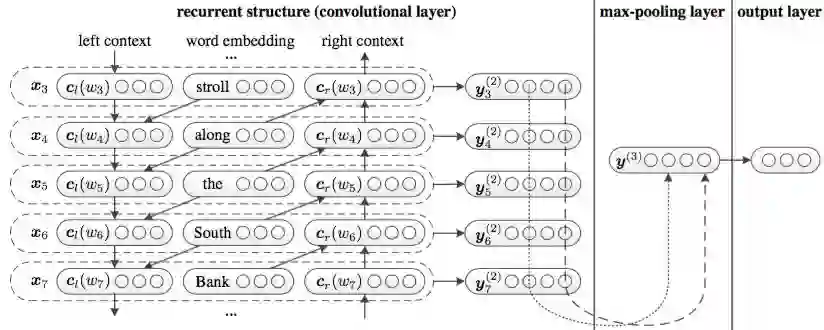
通过Recurrent的思想, 定义了left context和right context模型。
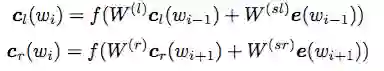
然后基于拼接操作得到输入, 然后利用tanh激活得到隐藏层的y。
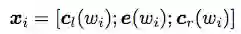
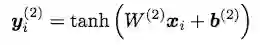
其实仔细观察很想双向RNN的功能。
6)Dynamic Memory Networks
斯坦福Manning组的博士Richard Socher,毕业后成立了 MetaMind公司, 做了CEO的Richard Socher带领团队里的Ankit Kumar 在ICML2016上发表了基于DMN来做QA的论文Ask Me Anything: Dynamic Memory Networks for Natural Language Processing, 这么牛掰的名字拥有300的引用量。
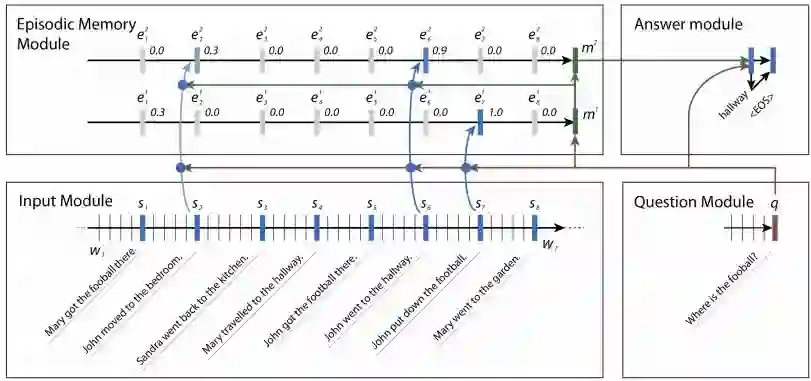
后来, 他们又提出了DMN+模型, Dynamic Memory Networks for Visual and Textual Question Answering。 引入双向GRU作为句子间的融合。
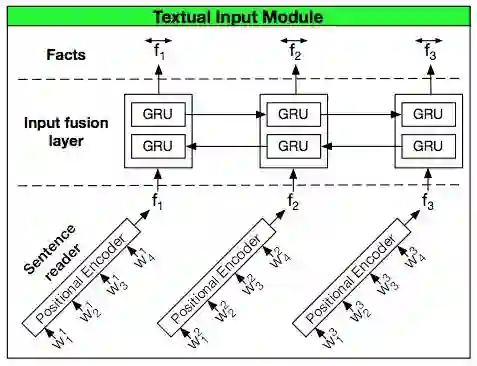
再增加了双通道
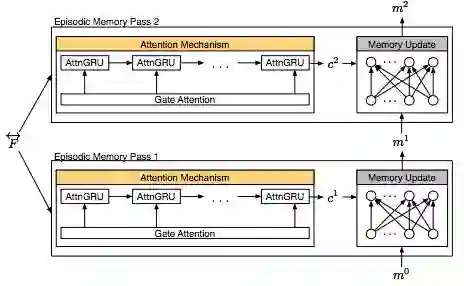
还进一步, 把第二层Attention采用GRU来实现。
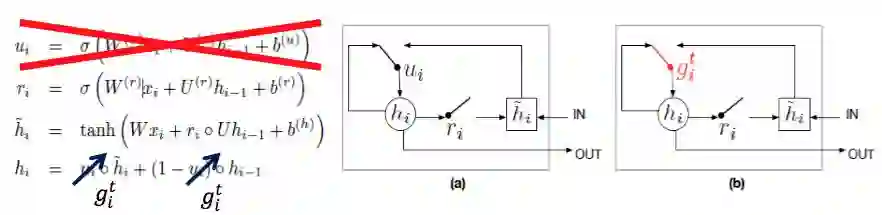
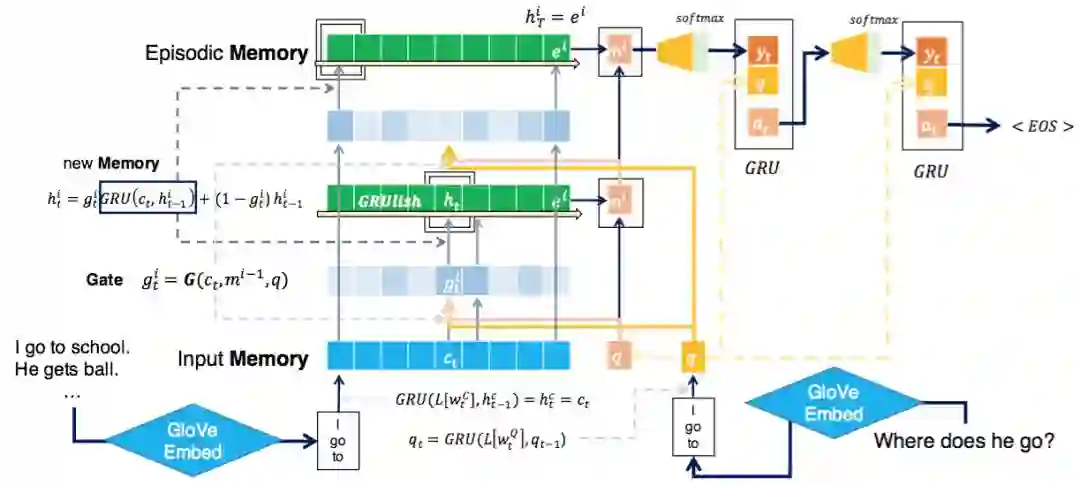
改进后的DMN+比DMN效果更佳!但是相对也更为复杂了。
前面我们谈到EntNet可以看成DMN+的改进版。 但是在具体实现上, 我们看到DMN的结构要比EntNet结构复杂。 而这种复杂性也会带来计算上的时间开销。
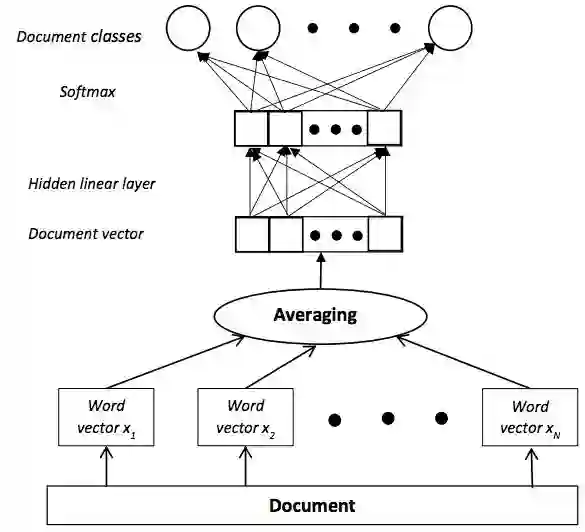
7)FastText
Tomas Mikolov所在团队在EACL2017上提出了FastText, Bag of Tricks for Efficient Text Classification, 开启了高效基于embedding的分类模型, 已有200多引用。

CNN跑一天, 他只要几秒钟。 还是非常诱惑的!
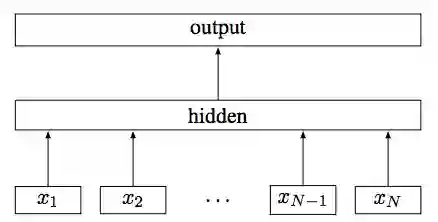
一般采用2-gram 或者 3-gram, 这样把句子转化n-gram的特征.
很明显的是更小单位的划分,对于未知词汇和缩率词会有帮助,所以相比较的也是对于字符的CNN。 后面计算的时候,会采用Softmax的近似计算, 譬如分成Softmax或者NCE,NS等等。
用在分类问题的时候, 再加上Softmax分类器, 基本上就是一个线性的BoW分类器:
就会得到如下的训练目标公式。
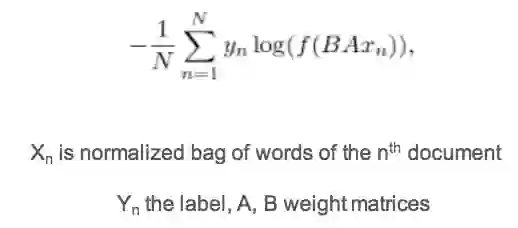
8)Seq2Seq
对于Seq2Seq模型,在“深度神经网络机器翻译”里面有详细的解读。
基于Seq2Seq可以实现QA系统, 所以类似的用来分类也是用了牛刀的感觉。
阿里巴巴在ACL2017上有篇问题中AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine, 谈论chatbot的,可以参考下下。
二, 模型选择
1)CNN vs RNN的考量
IBM的文章Comparative Study of CNN and RNN for Natural Language Processing有个简单比较CNN和RNN。
基本上的结论就是RNN不见得有CNN效果好, 但是Bi-RNN效果还是要好有点。
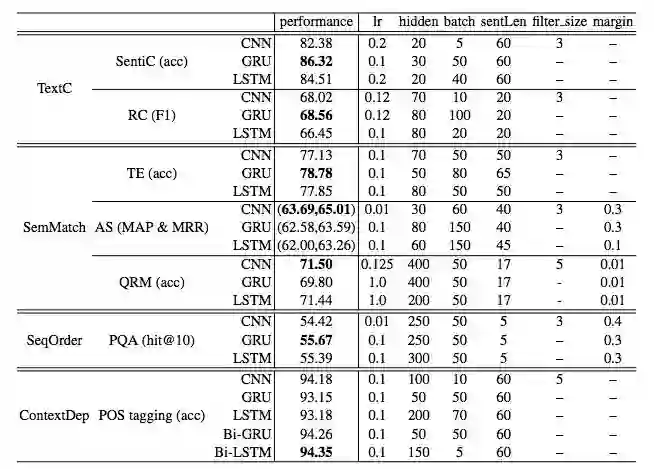
另外在https://github.com/brightmart/text_classification 里面提到一般来说RNN在分类上,训练时间要长于CNN。
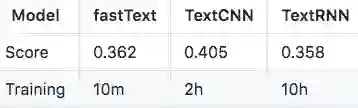
所以,综合考虑效果和时间的话,所以建议还是采用Text-CNN
2)时间 vs 效果的考虑
依然根据github上的实践, 牛刀模型EntNet和HAN的效果还是可以的, 而且时间也和Text-CNN接近。
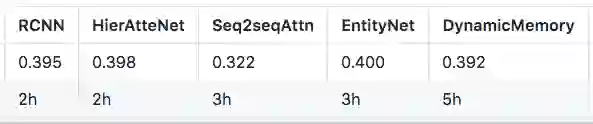
从模型应用到文本分类上来说:
1. EntNet和DMN是看成一个类似模型分组
2. Bi-RNN和Seq2Seq可以看成一个类似模型分组
3. RCNN上下文的效果应该和Bi-RNN类似
4. HAN应该和各种Attention模型一个类似模型分组
这样代表来说, Text-CNN, Text-Bi-RNN, EntNet和HAN可以分别为卷积,上下文, 存储记忆和注意力机制的代表了。
所以简单来说, 追求极速, 先用fasttext分类试试, 然后想提升效果了,就要考虑Text-CNN, Text-Bi-RNN, EntNet和HAN了。
其他考量
强化学习RL用在QA或者优化深度网络上也有工作可以关注。
譬如Choi的 Coarse-to-Fine Question Answering for Long Documents工作发表在ACL2017上。 其中RL对于探索长文档上起了一定作用。
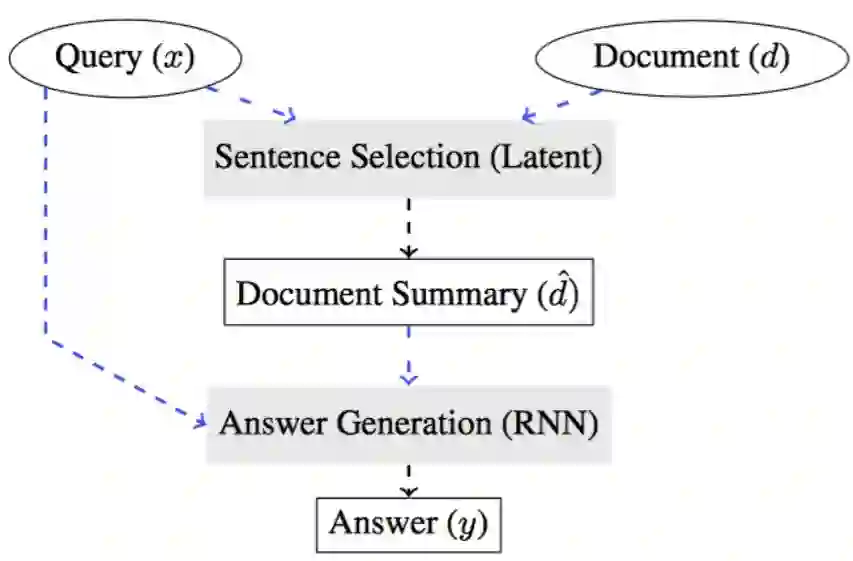
但是要看到和Attention机制相比, 效果有所提升, 但是时间开销也很大。
小结
文本分类在深度学习的时代逃过了特征提取类似距离的定义的过程, 但是依然逃不了模型的选择, 参数的优化,编码和预处理的考量(one-hot, n-gram等等) ,以及时间的平衡。 希望这里列举的模型和解释,稍微有所帮助。
参考:
https://plus.google.com/+YannLeCunPhD/posts/CR18UPiemYB
https://github.com/brightmart/text_classification
https://github.com/fendouai/Awesome-Text-Classification
https://github.com/brightmart/text_classification
课程信息
史博士将于3月24日-4月14日在上海开展深度学习培训,详情可识别以下二维码进入,点击“阅读原文”即可直接报名





