Kaggle 恶意评论(toxic comment classification)分类 top 1 %方案

文首发于知乎专栏「数据科学之旅」,AI 研习社获其授权转载。
赛题描述
给定来自维基百科的评论,完成6个类别的多标签分类(每条样本可能属于多个类别),大概就是toxic(恶意),severetoxic(穷凶极恶),obscene(猥琐),threat(恐吓),insult(侮辱),identityhate(种族歧视)其中几个,评论数据来自于维基百科以及部分的长尾干扰数据,数据比较脏,有近百种语言,一般的网站都会做一些敏感词的过滤,所以很多样本就是类似FFFFCCCCKKKK这样的话,甚至还有竖中指的字符画。所以这又不同于一般的情感分类,如何解决OOV(out of vocab)也是本题一个关键。这篇文章夹杂了比较多的私货,欢迎大家拍砖。
方案
大概提交的分数的走势如下。短期暴涨是阶段性的融合测试。持续性的上分都是有些技巧,主要是在下面几个位置达到了分数突破。
分数走势
做这个题的时候我自始至终保持的思路是,模型不是重点。如何解决OOV,数据不同源,外文分布差异,不规范词的归一化或者词义单元抽取才是关键。
所以重大突破点主要在以下几点:
细致的数据预处理,这部分比较烦杂而且针对数据非常严重。大概就是大量重复字母的剔除 fucccccck -> 去掉很多c。爬虫带来的html痕迹去除。使用词典做词的归一化等等。
跨领域的增量式词向量。这也是我的本科毕设,如何解决把细分领域的词向量放入一个已经预训练好的向量空间中,保持其聚类性质,线性性质。对于这部分感兴趣的可以参考论文。扩展一下,如何再GloVe的840B pretrianed词向量中嵌入一个医学corpus得到的词向量。
Incrementally Learning the Hierarchical Softmax Function for Neural Language Models(AAAI 2017)pseudo-labelling
这是一种对于有分布差异的数据进行半监督学习增强的方法。具体的原理和操作方法这篇博客讲的很熟悉。简单一句话就是,当前模型的预测结果,反过来作为训练集继续训练,直至网络收敛。
pseudo-labelling
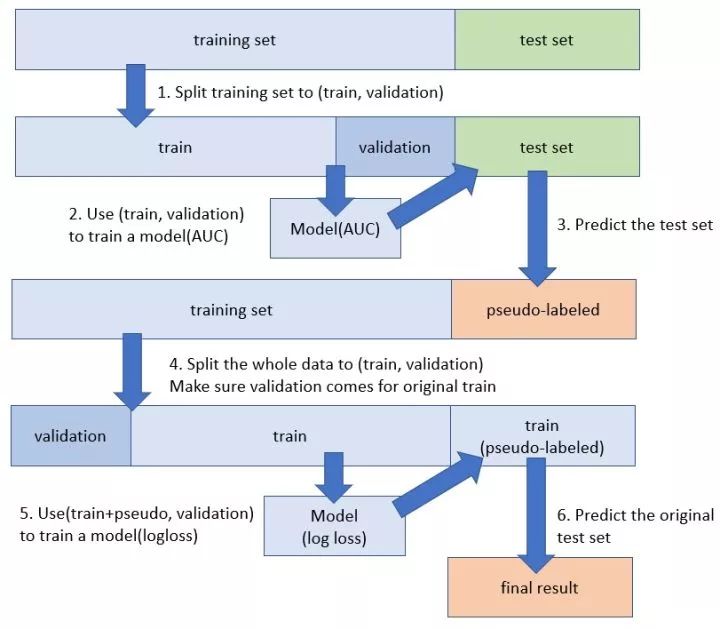
伪标签半监督学习
将正常的单词拆分成BPE单位。很对类似于fucker这样的单词,是可以拆分成更细碎的词义单元。使用 BPE(字节对编码)的方式分离单词能到到削减参数,增加泛化能力。
BPE在翻译中用的很多。大家可以看一下这篇论文。 Transfer Learning across Low-Resource, Related Languages for Neural Machine Translation翻译外文。把俄中日法蒙德等乱七八糟的语言都变成英语。
模型主要有以下几个:
GRU based: 单层,双层,average/max/k-max/attention pooling,RCNN
CNN based: TextCNN, 2DCNN, deliated CNN, VDCNN, DPCNN
capsule based: BiGRU + capsule net
tfidf/hash/count feature based: FM/LGB/LR
集成方法:一些比较弱的模型之间做了stacking,复杂模型之间做了blending
在模型上想说一下几点:
没有一种模型是万能的,方法 = 模型 + 数据。 之前在我的公众号的一篇文章里讲过, 一般性的认为,数据量小的时候,简单模型和LSTM更适合文本分类。 长文本(文档级别)数据更适合层次结构的模型。
LSTM比CNN更适合情感分类。具体的原因是LSTM能capture一些顺序性的信息,而CNN的卷积核+pooling的结构,对于语序的损失很大。很显然,我今天出去玩很不开心和我今天不出玩很开心明显有不同的感情色彩,这种句子是字典方法和CNN based model的杀手。
几个比较有意思的地方
这次我们的模型中使用了最新的capsule net的结构,还有借鉴了图像语义的分割模型中的空洞卷积,取得了不错的效果。这也是从差异性的角度考量做的一些工作,其实我是最不喜欢干这样的事情,个人喜欢追求单模型的极致,追求对数据的充分理解。喜欢简单干净有效的东西,复杂的东西无异于把路做绝,在数据上充分拟合,不能说不好,只能说欣赏不来。
失败的尝试:
情感词典的使用。一些文本层次的人工特征等。后来发现这种人工特征不够强,简单的对tfidf做一个类间信息修正就可以把LGB 拉到0.9810+。在这种情感分类问题中tfidf一个明显的问题就是,fuck这种单词出现实在是太多以及太频繁了,很容易被idf削弱,成为stop words一样的存在,这时候就需要加上类间信息修正(这种词的卡方检验排脑袋一想就很高,但是stop words就不一样了)。
数据量不足以支撑模型复杂度的时候,不要轻易增加模型的参数规模,包括Embedding层也最好不要trainable。
标签信息的使用,这6个标签是有隐含的关系的,比如server_toxic 的一定属于toxic, 这部分做了lable chain最后也没有啥效果。之前知乎文本分类的比赛上,也有层次的标签约束信息,而恰好我们去年研究过如何使用层次的标签的信息做文本分类,可参考论文。Large-Scale Hierarchical Text Classification with Recursively Regularized Deep Graph-CNN (WWW 2018)
一开始想着解决抽取词义单元的时候,没有想到BPE,于是就就把corpus拆成了n-grams训练词向量硬怼,这样硬怼的单模型perfomance虽然比较低,但是作为模型的多输入是可以提升模型的性能的,我估计在某些hard-sample上做了修正。后来在data-thread看到第一的人说他用了一个sentpiece的外部数据,我点开看了下,发现了新天地,和我的想法不谋而合,于是愉快的换成了BPE,并且BPE有预训练的embedding,可谓是十分强大。
一点感受:
大家在比赛之中多尝试思考存在于数据和模型上的一些本质的东西,瞎怼和调参是没啥用的,浪费电。多看看论文,也不可全信论文。做比赛9个月来,最大的收获就是习惯性用批判性的眼光看论文,很多论文都是在讲故事,方法是数据上的过拟合。真正state-of-art的东西,是可以直接当特征提取器的,比如resnet, 一篇论文养活了多少家创业公司。
比赛到最后,还是拼融合,也是最无聊和实际中最没有价值的一部分,我们单模型挺高的,不过N人行必有TOP K,基本的融合方法也要谙熟于心。
附上我队友砍手豪大佬对本次比赛所有解答方案的一些总结:
https://zhuanlan.zhihu.com/p/34899693?group_id=961190993937268736
最后打个广告,欢迎关注i数据智能微信公众号,给数据科学爱好者 带来机器学习,深度学习,数据挖掘与Kaggle等数据科学竞赛的分享与交流。

计算机视觉基础(从算法到实战应用)班
限时拼团,最后一周
已有100+人参加了此拼团
最高每人优惠200元!

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
Kaggle 大神 Eureka 的高手进阶之路
▼▼▼



