【论文】Awesome Relation Extraction Paper(关系抽取)(PART IV)
作者:高开远
学校:上海交通大学
研究方向:自然语言处理
0. 写在前面
继续:【论文】Awesome Relation Extraction Paper(关系抽取)(PART III)
1. Neural Relation Extraction with Multi-lingual Attention(Lin/ ACL2017)
这篇文章是在Lin 2016年 Selective Attention的基础上进行改进,将以前仅仅研究单一语言扩展到多语言信息抽取。多数已有的研究都致力于单语言数据,而忽略了多语言文本中丰富的信息。多语言数据对信息抽取任务有以下两个优势:
一致性: 一个关系事实在多种语言中都有一定的模式,而这些模式的关系在不同语言中大致上一致。
互补性: 不同语言的文本可以相互借鉴,另外数据多的语言能够帮助数据少的语言提升总体性能
基于以上两点,文章提出了Multi-lingual Attention-based Neural Relation Extraction(MNRE),对于给定的两个实体,他们在不同语言中的句子集合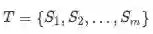
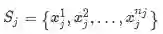
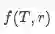
模型整体框架如下:

Sentence Encoder
句子特征抽取这一部分跟Lin 2016年 Selective Attention的工作几乎一样,之前已经有详细介绍,这里就不再啰嗦啦
Multi-lingual Attention
为了获取多语数据中的信息,设计了两种attention操作:单语言之间attention和多语言之间attention。其中Mono-lingual Attention为上图中实线部分,其实现与Lin 2016年 Selective Attention相同。下面主要介绍Cross-lingual Attention,表现为上图中虚线部分。
假设 j 和 k 分别代表了不同的两种语言,
首先计算语言j的句子集合与语言k 的标签之间的一致性程度,得到attention score e_i

接着用softmax归一化attention score得到attention distribution:
最后用attention distribution去判定语言 j 中句子的重要性程度
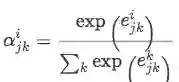
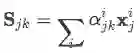
这样如果有m 种语言,那么最终结果就会得到 m*m 种对于实体对的表示:
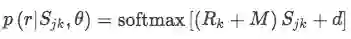
试验分析及个人总结
作者在文章后半部分做了很多对比试验,非常有说服力地验证论文的价值
文章一大创新点就是利用多语言数据之间的一致性与互补性运用到数据抽取任务,其中多语分析也被用于其他NLP任务,比如情感分析,信息抽取等;
虽然说更多的数据代表更多的信息,但是原始多语言数据的获取确是一大难点
CODE HERE
2. Deep Residual Learning for Weakly-Supervised Relation Extraction (Huang /EMNLP 2017)
本文从之前研究的一层CNN扩展到了更深的CNN网络(9层),使用的是在图像领域非常有效的ResNet。residual learning将低层和高层表示直接连接,还能解决deep networks的梯度消失问题。本文使用shortcut connection。每个block都是一个两层convolution layer+ReLU。整体模型如下所示:

至于为啥ResNet对于信息抽取任务会有效,文中给出了两点原因:
一是,假如浅层、中层和高层分别抽取到词法、句法和语义的信息的话,那么有时候忽略中间的句法信息,直接将语法和语义信息结合也可以work;
第二点是,ResNet可以有效缓解深度网络中的梯度消失问题,而这个操作可以有效减轻远程监督数据中的噪音(???不懂)
试验分析及个人小结

3. Weakly-supervised Relation Extraction by Pattern-enhanced Embedding Learning(Qu/ACM 2016)
没有用深度学习,而是两个朴素的模型互相迭代,运用了半监督学习的思想。
4. Learning with Noise: Enhance Distantly Supervised Relation Extraction with Dynamic Transition Matrix(Luo/ACL 2017)
本文的重点也是在于如何解决远程监督数据的噪音问题。前人的工作,主要是&降噪,即从噪音数据中提取出正确标记的样本。作者在这篇论文中提出既然数据中的噪音是无法避免地存在的,为何不在模型中学习噪音的分布,即给噪音数据建模,从而达到拟合真实分布的目的。于是在训练过程对每一个instance引入了对应的transition matrix,目的是:
对标签出错的概率进行描述
刻画噪音模式
由于对噪音建模没有直接的监督,提出使用一种课程学习(curriculum learning) 的训练方式,并配合使用矩阵的迹正则化(trace regularization) 来控制transition matrix在训练中的行为。具体细节会在下面介绍。
整体的模型框架如下图所示

Sentence-level Modeling
句子级别的建模,主要考虑输入是一个句子。分为三部分:
(1)上图中的①+②过程就是之前介绍的PCNN_+ FC + SOFTMAX输出对应relation概率的模型。
(2)Noise Modeling: 对于一个句子,通过PCNN + FC得到 x_{n} 后使用softmax计算transition matrix:
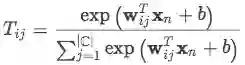
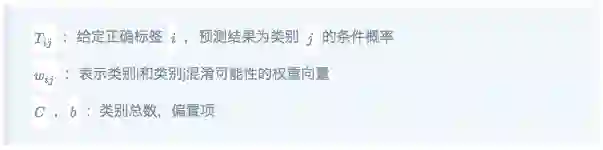
注意在训练时会对每个instance都建立transition matrix但是其中的权重向量 w_{ij}是全局共享的。
(3) Observed Distribution:通过transition matrix与预测向量p相乘,可以得到最终的分布 o :
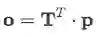
在模型训练阶段,使用观测分布 o ;但是在inference阶段,直接使用prediction distribution,因为模型已经学习到的噪音分布模式可以防止prediction受其影响
Bag Level Modeling
bag级别的建模,输入是一个bag里的多个句子。和上面sentence level唯一不同的就是如何表示出bag的向量。这里可以使用句子级别的attention操作,在之前都有过介绍,就不在细述。
Curriculum Learning based Training
在训练过程中,参考大家普遍的做法是,对于模型输出o, 直接计算o和label的loss, 也就是CrossEntrophy (CE) + l2 正则作为损失函数。这样做不能保证p能表示真实分布。原因在于在训练的初始阶段,我们对于噪音模式没有先验知识,这样T和p都不太可靠,这样会使得训练陷入局部最优。因此我们需要一种技术来保证我们的模型能够逐步适应训练噪音数据,于是引入了课程学习。
课程学习的思想:starting with the easiest aspect of a task, and leveling up the difficulty gradually
课程学习的训练方法可以引入先验知识以提高transition matrix的有效性,例如,我们认为地将训练数据分为两部分,一部分相对可靠,一部分相对不可靠
Trace Regularization
迹正则是用来衡量噪音强度的。当噪音很小时,transition matrix会是比较接近单位矩阵(因为ij之间混淆性很小,同类之间的转移概率很大,接近1,这样转移矩阵就会接近单位矩阵) trace(T)越大,表明T和单位矩阵越接近,也就是噪音越少。对于可靠的数据trace(T)比较大,不可靠的数据trace(T)比较小。
迹正则的另一个好处的降低模型的复杂度,减小过拟合。
训练
直接看最终的损失函数,由三部分组成,第一部分是观测分布的损失,第二部分是预测分布的损失,第三部分是迹正则。alpha,beta分别表示训练过程中红每个损失的重要程度。
训练过程:一开始,让alpha=1。随着训练的进行,sentence encoder 分支有了基本的预测能力。并逐渐减小beta, alpha。逐渐减小对于trace的限制,允许更小的trace来学到更多噪音。随着训练的进行,越来越关注于学习噪音模式。
另一方面,如果我们有数据质量的先验知识,就可以利用这些先验来进行课程学习。具体来说就是将数据集分成相对可靠和相对不可靠两部分,先用可靠的数据集训练几个epoch, 再加入不可靠的数据集继续训练。同时利用迹正则,对于可靠数据集,trace(T)可以适当地大一些,对于不可靠的数据集,则要让trace(T)小一些。
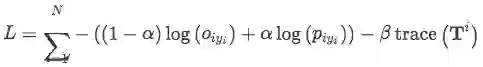
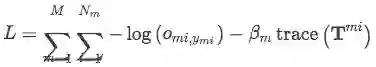
试验分析及个人小结
作者在两个数据集上对上述模型进行了实验验证:TIMERE和ENTITYRE。评价指标选取的是PR曲线

文章的出发点非常好,既然噪音是在数据中无法避免的,那我们训练阶段就去学习这种噪音分布特征,然后在测试阶段就可以有效避免;
提出了global transition matrix,用于得到从真实预测分布到实际观测到的包含噪音分布的映射关系;之后有进一步优化到了Dynamic transition matrix,依输入句子的不同而改变,粒度更细,效果更好;
提出了curriculum learning的训练模式,课程学习属于一种从易至难的任务学习,比随机顺序学习更好,避免学习出无意义的局部最优;
最后附上一份作者的PPT报告
5. Effectively Combining Recurrent and Convolutional Neural Networks for Relation Classification and Extraction(SemEval 2018)
非常工程的一篇打比赛文章,在SemEval 2018 Task7的四个子任务中取得了三项第一。SemEval 2018任务7子任务介绍:
Subtask1.1:实体对关系分类(给定实体对,句子,关系,不包含NA类别)
Subtask1.2 :加噪数据实体对关系分类(给定实体对,句子,关系,不包含NA类别)
Subtask2 :实体关系分类(给定实体位置,句子,关系,包含NA类别)
作为打比赛的模型,不择手段地提高分数才是王道,文章一开始就列出了各种特征对最终模型效果提升的影响。后面将会对下面提及的特征进行一一细述。

本文的模型也非常易懂,ensemble了前面例举过的CNN和LSTM,如下图所示
模型的输入是word embedding + POS + relative position embedding
对于CNN部分:一层多个卷积核convolutional layer + RELU + max-pooling layer + fully-connected layer with dropout + softmax
对于RNN部分:双向LSTM(使用dynamic,不用padding)+ fully-connected layer with dropout + softmax
将以上的ensemble网络训练20次,将得到的概率值平均后作为最终每个分类的得分
下面来仔细看看都用了哪些tricks

Domain-specific word embeddings
使用gensim为该任务训练了特定领域的词向量,尝试了100,200,300维的词向量,最终200维表现最好。
Cropping sentences
考虑到最终决定relation类别的是句子两个实体之间的部分,于是将所有橘子两个实体之间的部分切分出来当成训练样本。此外通过对数据分析发现当句子长度大于一定阈值时,类别的概率会大大降低,通过实验得出阈值设定为19的时候效果最
Cleaning sentences
原始数据集中有些自动标注的样本包含了噪音实体,例如<entity id=”L08-1220.16”> signal <entity id=”L08-1220.17”> processing </entity></entity>,signal processing和processing都标记了实体,对于这样的样本,我们考虑将其拆分成两个样例,分别考虑单独的每一个实体。从另一个层面上看,其实也算是数据增强了。
此外,对于[]和()内的token都删除,不属于专有名词的数字被替换为通配符令牌。
Using entity tags
其实就是之前介绍过的Position Indicator,用于告诉模型实体在句子中的位置。
Relative order strategy & number of classes
一种数据增广方式:句子反转。将非对称的关系句子按字反转之后,实体对的前后关系发生反转,他们之前的关系也就发生了反转,于是使用一种替换的方式直接将实体中间的字换成表达相反关系的token。例如图中表达的是“由…组成的关系”, 前者“corpus”由后者“text”组成。将句子反转之后,他们之间的位置反转,中间的token “ from a “ 表示”由…组成的关系“相反的关系。这样新生成的句子虽然是语法上不通,但是可以提升Performace。
Upsampling
对于subtask2,数据集出现样本极度不平衡现象,类别为None的样本占了大多数。于是对所有数据上采样,也就是网络输入每次保证正负样本的比例是固定的(1:1)
Combining predictions
作者做实验的时候发现,单独使用RNN或者CNN, 效果都差不多,但是两种模型ensemble的时候效果会有提升。更进一步的结果是,作者发现RNN模型对长一些的句子比CNN效果好。于是本文使用如下公式对RNN的prob加权。
其中 s_{i} 是对一个句子的长度拉伸表示(区间为[-0.5, 0.5]),句子越长,权重越高
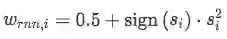
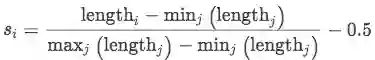
Post-processing
六类关系中有五种是非对称的,一种是对称的。由于进行了句子反转,所以翻转后的句子结果不可能为对称关系,需要将这种情况下的预测改变为得分第二高的类别。
还有一种情况是,subtask2中,每个实体只能属于一个关系,如果出现一个实体同时出现在两个关系中,需要选择更短的或者频率更高的或者随机输出。
个人小结
可以看出作者对整个任务的数据处理和特征提取做的非常深入,这也是模型得分能这么高的原因。要好好学习啊
相关文章:
【论文】Awesome Relation Classification Paper(关系分类)(PART I)
【论文】Awesome Relation Classification Paper(关系分类)(PART II)
【论文】Awesome Relation Extraction Paper(关系抽取)(PART III)
原文链接:
本文由作者原创授权AINLP首发于公众号平台,点击'阅读原文'直达原文链接,欢迎投稿,AI、NLP均可。




