南大清华发布《从单目图像中恢复三维人体网格》综述论文,涵盖246篇文献全面阐述单目3D人体网格恢复研究进展
从单目图像中估计人体的姿势和形状是计算机视觉领域中一个长期存在的问题。来自南京大学和清华大学的最新研究论文《从单目图像中恢复三维人体网格》,提出了从而二维数据提升至三维网格过程中基于优化和基于回归的两种范式,第一次关注单目3D人体网格恢复任务的研究,并讨论了有待解决的问题和未来的发展方向。

摘要
从单目图像中估计人体的姿势和形状是计算机视觉领域中一个长期存在的问题。自统计学人体模型发布以来,三维人体网格恢复一直受到广泛关注。为了获得有序的、符合物理规律的网格数据而开发了两种范式,以克服从二维到三维提升过程中的挑战:i)基于优化的范式,利用不同的数据项和正则化项作为优化目标;ii)基于回归的范式,采用深度学习技术以端到端的方式解决问题。同时,不断提高各种数据集的3D网格标签的质量。尽管在过去十年中,该研究取得了显著的进展,但由于肢体动作灵活、外观多样、环境复杂以及人工注释不足,这项任务仍然具有挑战性。据调查,这是第一次关注单目3D人体网格恢复任务的研究。我们从介绍人体模型开始,通过深入分析其优缺点详细阐述了恢复框架和训练目标。我们还总结了数据集、评估指标和基准测试结果。最后讨论了有待解决的问题和未来的发展方向,旨在激发研究人员的积极性,促进各位学者在这一领域的研究。定期更新的项目页面可在 https://github.com/tinatiansjz/hmr-survey 查看.
https://www.zhuanzhi.ai/paper/cd02b1ea9263bb9a37bd968e0a7ef9b8
引言
从单目图像中理解人类是计算机视觉的基本任务之一。在过去的20年里,业界一直致力于预测二维内容,如关键点[1]、[2]、[3]、轮廓[4]和RGB图像的局部分割[5]。随着这些进展,研究人员进一步寻求在3D空间中预测人类姿势[6]、[7]、[8]、[9]、[10]、[11]、[12]。虽然简单的动作可以通过2D内容或一些稀疏的3D关节相对清晰地表示出来,但复杂的人类行为需要更细致地描述人体细节。此外,因为我们使用表面皮肤与外界直接接触而不是用未观察到的关节,所以对身体的形状、接触面、手势和表情进行推理也是至关重要的。
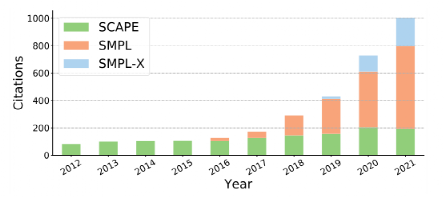
近年来,社区已经将他们的兴趣转向了人体的3D网格恢复[13]、[14]、[15]、[16]、[17]、[18]、[19]、[20]、[21],以及富有表情的脸和生动细致的手[22]、[23]、[24]、[25]、[26]。这一趋势与统计人体模型的成功密不可分。如图1所示,自2015年发布SMPL模型[27]和2019年发布SMPL-X模型[22]以来,随着它们的年度引用量逐年快速增长,它们获得了越来越多的关注。人体网格的恢复在促进后续任务(如衣服人体重建[28]、[29]、[30]、动画[31]、[32]和渲染[33])方面起着关键作用。它还涉及广泛的应用,如VR/AR内容创建、虚拟试穿、计算机辅助指导等等,如图2所示。

从单目图像中恢复三维人体网格非常具有挑战性,因为将二维观测值提升到三维空间时存在固有的模糊性、柔性身体运动学结构、与环境的复杂性以及人工三维数据注释不足等问题。为了解决这些问题,在该领域研究了两种不同的范式,以恢复一致且物理上合理的结果。对于基于优化的范例[13]、[15]、[35],通过迭代的方式将身体模型显式地应用于二维观测。以各种数据项和正则化项为优化目标。对于基于回归的范例[16]、[17]、[18]、[36]、[37]利用神经网络强大的非线性映射能力,直接从原始图像像素预测模型参数。设计了不同的网络架构和回归目标,以实现更好的性能。同时,为了促进这项任务的研究,还投入了大量精力创建各种数据集。尽管近年来取得了显著进展,但在实现强健、准确和高效的人体网格恢复的最终目标面前,业界仍然面临着挑战。
本综述主要关注深度学习时代的单目3D人体网格恢复方法(也称3D人体姿势和形状估计)。将单个RGB图像和单目RGB视频(统称为“单目图像”)作为输入。除了从单目图像中恢复单人外,我们还考虑了多人恢复。对于重建目标,使用统计人体模型来估计衣服下的体型。RGBD和多视图输入有助于解决歧义,但它们不在本综述的范围内。我们只是忽略了服装的造型,这是向照片现实主义迈进的一步。我们请读者参考[38]中关于人类服装重建的内容。我们也不涉及神经渲染方面的工作[33],[39],这些工作侧重于外观的建模,而不是几何体。这项调查也是对现有调查论文的补充,主要关注2D/3D人体姿势估计[40]、[41]、[42]。
其余部分组织如下。在第2节中,我们简要介绍了人类模型的发展历史,并提供了SMPL模型[27]的详细信息,SMPL模型是人类推理中使用最广泛的模板。第3节描述了用手和脸进行身体恢复和全身恢复的方法。方法分为基于优化的范式或基于回归的范式。在第4节和第5节中,我们将整理出帮助处理视频或多人恢复的新模块。然而,如果我们仅仅用常规数据项监督人体,结果可能在物理上不合理,并且存在视觉缺陷。因此,在第6节中,我们讨论了通过涉及真实摄像机模型、接触约束和人类先验来增强物理合理性的策略。第7节总结了常用的数据集和评估标准,以及基准排行榜。最后,我们在第8节中得出结论并指出一些有价值的未来方向。
人体网格恢复
自从统计身体模型发布以来,研究人员利用它们从单目图像中估计形状和姿势。Balan等[82]率先从图像中估计SCAPE[34]的参数。目前,学术界普遍采用SMPL[27]进行三维体型恢复。这要归功于SMPL的开源特性和它周围快速发展的社区: Ground-Truth真相采集方法[13],[77],具有扩展SMPL注释的数据集[35],[83],[84],[85],[86],以及里程碑作品[16],[37],[87]。在本节中,我们将根据预先定义的人体模型[22],[27],[34]来整理人体网格恢复的文章。身体捕捉身材和姿势的变化,但不考虑衣服或头发。因此,更准确地说,这些方法可以估计出穿着衣服或紧身衣时身体的形状和姿势。在图4中,我们演示了一些有代表性的方法。我们根据它们采用的人体模型对它们进行分类。
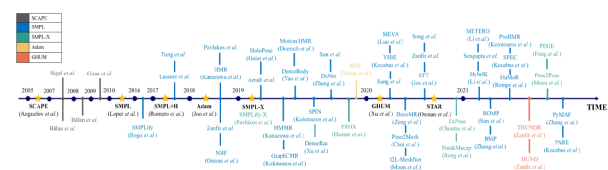
图 3最相关的参数化人体模型和3D人体网格恢复方法时间轴
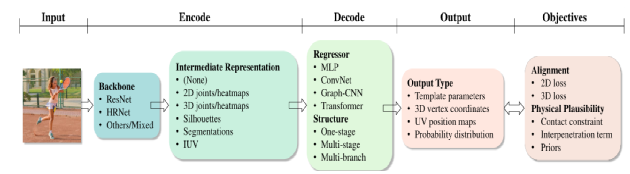
图 4基于回归的人体网格恢复方法的流程。
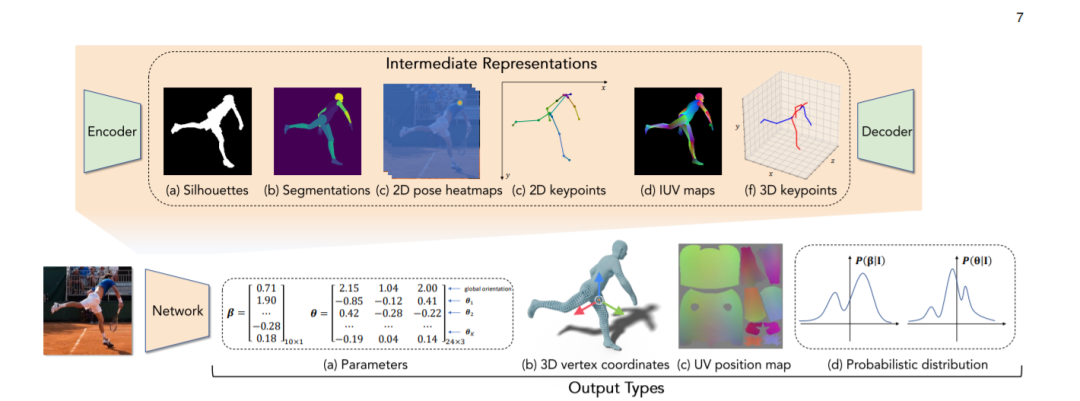
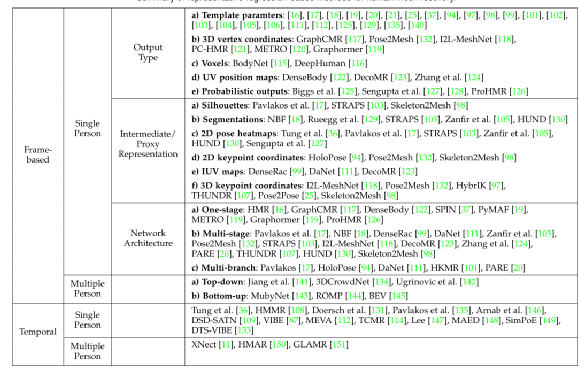
回归网络中各种输出类型和中间表示的说明。我们研究了四种输出类型:(a)参数输出;(b)网格顶点的三维坐标;(c)UV 位置图;(d)在姿态和/或形状参数上的概率分布。在多阶段框架中采用的中间表示包括(a)轮廓;(b)分割;(c) 2D位姿热图;(d)二维关键点坐标;(e) IUV地图;(d)三维关键点坐标,可作为简化输入或指导。
总结
在这篇论文告中,我们对过去十年中的3D人体网格恢复方法进行了全面概述。分类基于设计范式、重构粒度和应用场景。我们还特别考虑了物理合理性,包括相机模型、接触约束和人类先验。在实验部分,我们介绍了相关的数据集、评估指标,并提供了性能比较,希望促进这一领域的进步。
参考文献:
[1] Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, “Openpose: Realtime multi-person 2d pose estimation using part affinity fields,” TPAMI, 2019.
[2] H.-S. Fang, S. Xie, Y.-W. Tai, and C. Lu, “Rmpe: Regional multiperson pose estimation,” in ICCV, 2017.
[3] S. Kreiss, L. Bertoni, and A. Alahi, “Openpifpaf: Composite fields for semantic keypoint detection and spatio-temporal association,” arXiv preprint arXiv:2103.02440, 2021.
[4] Q. Chen, T. Ge, Y. Xu, Z. Zhang, X. Yang, and K. Gai, “Semantic human matting,” in ACM MM, 2018, pp. 618–626.
[5] J. Zhao, J. Li, Y. Cheng, T. Sim, S. Yan, and J. Feng, “Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing,” in ACM MM, 2018.
[6] K. Grauman, G. Shakhnarovich, and T. Darrell, “Inferring 3D structure with a statistical image-based shape model,” in ICCV, 2003.
[7] A. Agarwal and B. Triggs, “Recovering 3d human pose from monocular images,” TPAMI, 2005.
[8] J. Martinez, R. Hossain, J. Romero, and J. J. Little, “A simple yet effective baseline for 3D human pose estimation,” in ICCV, 2017
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“3DHM” 就可以获取《南大清华发布《从单目图像中恢复三维人体网格》综述论文,涵盖246篇文献全面阐述单目3D人体网格恢复研究进展述》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~




