CVPR 2022 Oral|PoseConv3D开源: 基于人体姿态的动作识别新范式

极市导读
PoseC3D是一种基于 3D-CNN 的骨骼行为识别框架,同时具备良好的识别精度与效率,在包含 FineGYM, NTURGB+D, Kinetics-skeleton 等多个骨骼行为数据集上达到了SOTA。不同于传统的基于人体 3 维骨架的GCN方法,PoseC3D 仅使用 2 维人体骨架热图堆叠作为输入,就能达到更好的识别效果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

Paper:https://arxiv.org/abs/2104.13586
Code:https://github.com/kennymckormick/pyskl
引言

我们此前的工作 PoseC3D [1] 在今年的 CVPR 中以 Oral Presentation 接收,这项工作第一个使用 3D-CNN 来进行基于关键点序列的视频理解,同时取得了较好的识别性能,对后续的工作存在一些启发意义。在之前的文章(https://zhuanlan.zhihu.com/p/395588459)中,我们已对这项工作的具体方法,相对 GCN 方法的优势,以及实际性能进行了详细的描述。在过去一段时间,我关于 skeleton action recognition 又进行了一些相关的研究,这篇文章会围绕以下主题:
-
什么是 skeleton action recognition?其意义在于何处? -
现有 skeleton action recognition 解决方案的一些问题,兼谈 PoseC3D 的优缺点。 -
分享我们最新的开源实现 PYSKL [2],这个开源代码库同时支持了 PoseC3D 与 GCN 方法,及其一系列最佳实践。
Skeleton action recognition 定义及其意义
Skeleton Action Recognition
Skeleton-based action recognition 意味基于且仅基于时序关键点序列来进行视频理解。举一个具体的例子:若有一个 300 帧的视频,其中包含一个人,如使用 17 个二维关键点(CoCo 定义),那么输入的形状即为 300 x 17 x 2。一般传统上,关键点序列多指人体关键点序列(如手肘、手腕、膝盖等关键点),但显然,这类方法也可以扩展至其他场景,如用面部关键点识别表情,用手上的关键点识别手势等等。
不同于基于 RGB 的视频理解,skeleton action recognition 具有如下优点:1. 骨骼点本身作为一种与人体动作关系密切的表示形式,对于视频理解有重要意义;2. 骨骼点是一种轻量的模态,所以基于骨骼点的识别方法,往往比基于其他模态的方法轻量许多;3. 基于骨骼点的识别,结合高质量的姿态检测器,往往能在数据较少的情况下就能取得不错的识别效果,且兼具较强的泛化能力。
而同时,skeleton action recognition 也具有如下缺点:1. 并非所有的动作,都可以仅通过骨骼点序列来识别,部分动作类别需要依赖于物体、场景等上下文来进行判定;2. 在难以获取高质量关键点的情况下,骨骼动作识别的性能会受到较大影响。在实际使用过程中,还需要依据实际需求,来选择究竟基于那种模态,进行视频理解。
现有方案的一些问题,兼谈 PoseC3D 的优缺点
现有 Skeleton-based Action Recognition 的解决方案,主要有基于 GCN 或 CNN 的两大类别,本文会分别讨论其中存在的一些问题。
共有问题:Skeleton 质量
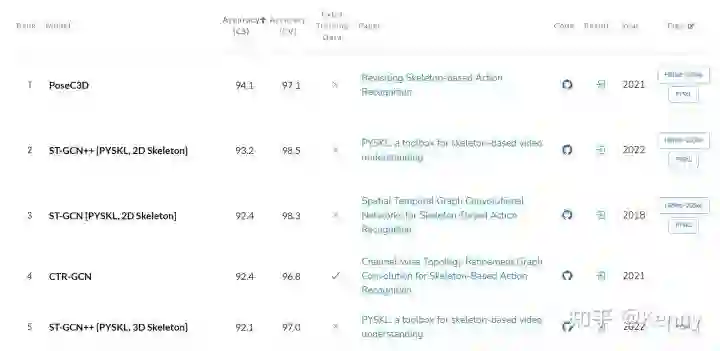
作为输入,Skeleton 本身的质量对于最终的识别效果极为重要,但这点往往受到的关注较少。PoseC3D 中对于这点进行了讨论,主要的发现包括:1. 若都局限于 pose estimator 得到的关键点, 那么使用 2D 姿态估计的结果作为输入,通常远好于使用 3D 姿态估计结果,或是 2D -> 3D lifting 的结果作为输入;2. 同为 2D 姿态作为输入的情况下,依据 pose estimator 的好坏,识别结果也有优劣之分,但差异不大。在 PYSKL 中,我们同样使用了来源于 Kinect 的 3D 骨骼点与 HRNet 输出的 2D 骨骼点训练 ST-GCN [3] 与 ST-GCN++ [2](我们开发的一个 ST-GCN 的简单变种)两种模型。以 2D Pose 作为输入,仅作为 ST-GCN 的一个简单变种,ST-GCN++ 就能在三项 benchmark (NTURGB+D XSub, NTURGB+D XView, NTURGB+D 120 XSet)上达到所有 SOTA 方法中前三的性能。值得注意的是,HRNet 2D Pose 虽在大部分的评测数据集上取得了优势,但并非全部:如在 NTURGB+D 120 Xsub 这个评测基准上,2D Pose 的效果就要差于 3D Pose。我们认为, 关于 Skeleton 种类及质量对于识别效果的影响,还有待进行大量的研究。
另一值得注意的点是,我们认为动作识别效果将随着姿态估计质量的提升而单调提升,但两者绝不是类似于简单的线性关系,这一点在 PoseC3D 中有指出。另外,我们认为,在某些情况下,即使姿态估计的质量很差,只要其中包含与目标动作相关的模式,那也足以用来进行行为识别。如 HRNet 在 GYM 数据集上的识别效果实际不佳,但依赖于其所估计的关键点,依然能在动作识别任务上取得出色的效果。
GCN 方法及其问题
作为 Skeleton Action Recognition 的主流方法,GCN 方法依然存在一系列实践相关的问题,这些问题制约了模型的性能,并一定程度上影响了不同方法间的公平比较。本文以 NTURGB+D 数据集为例,对存在的问题进行简述。
Preprocessing & Augmentation
给定一个 skeleton sequence,目前的 GCN 方法会先对其进行处理,以得到模型输入。预处理主要分为两个部分:1. 空间维度上,以第一帧作为基准,将第一帧中的 skeleton 的中心点置于原点,将第一帧中 skeleton 的脊椎与 z 轴对齐;2. 时间维度上,针对数据集中序列长短不一的问题,主要有以下解决方案:
-
ST-GCN [3]: 将所有序列以 zero padding 扩充至最大长度(所有序列中最长序列的长度)。 -
AGCN [4]: 将所有序列以 loop padding 扩充至最大长度。 -
CTR-GCN [5]: 预处理时不进行处理,在 data augmentation 时,使用 Random Crop 裁剪出子序列,并 interpolate 到一定长度。
其中,前两个方案的缺点在于,将序列以确定形式 pad 到最长的长度,产生了计算力浪费。第三种方案,虽可以产生多样的训练样本,但 interpolate 得到的 skeleton 分布与原本的数据分布不同,且 crop 出的子序列不一定能完整地表示整个动作。
在 PYSKL 中,我们对相关实践进行了改进。具体说,我们将 PoseC3D 中 Uniform Sampling 直接应用于 GCN,从原本的 skeleton sequence 中采样出子序列作为输入,这种方式在训练时可以得到更多样的训练样本(且每个样本都足以覆盖整个动作),也使 test time data augmentation 成为可能。
Hyper Parameter Setting
在 PYSKL 中,我们也根据对 PoseC3D 的训练经验对 GCN 训练的超参设置进行了改进。主要的改进包括,我们使用了 CosineAnnealing 训练策略,并使用了一个更强的正则项。改进超参设置后,GCN 模型的效果有了长足的提升。
CNN 方法及其问题
基于 CNN 进行 skeleton-based action recognition 的方法,主要分为 2D-CNN 与 3D-CNN 两大类。基于 2D-CNN 的方法,如 PoTion [6],将骨骼点序列以 color coding 的方式绘制在一张图上,并用 2D-CNN 进行处理,其最大的问题,也在于以 color coding 方式进行时序维度上的压缩造成了无法弥补的信息损失。
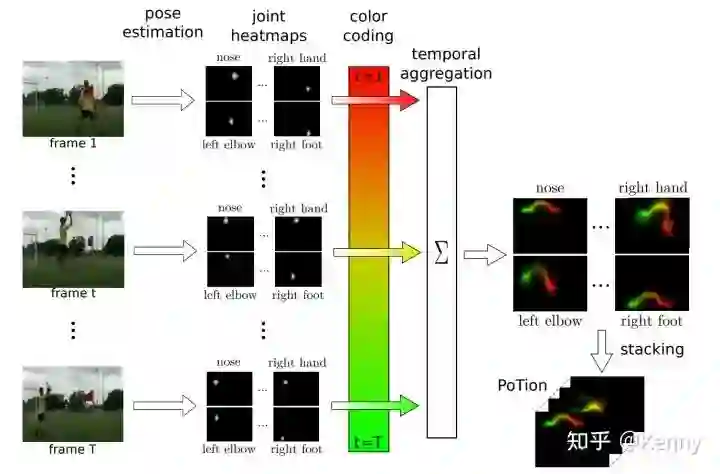
作为基于 3D-CNN 的方案,PoseC3D 将 keypoint heatmap 堆叠为 3D Voxel,并用 3D-CNN 进行处理。作为一个简单明了的方案,PoseC3D 能直接利用 3D-CNN 强大的时空建模能力,在取得良好识别效果的同时具备鲁棒性好,可扩展性好,兼容性好等诸多优点。但同时,其也有以下的不足之处:
-
未针对骨骼模态特点进行特有的模型设计,识别效果还有优化空间。 -
相对 GCN,所需计算量还是较多:使用基于 R50 的 3D 网络,其算力消耗仅能做到与 GCN 中的较 heavy 方法 MS-G3D [7] 相当,多于其他一些更轻量的 GCN 方法。 -
如输入为 3D 点的情况下,目前只能将其先投影到 2D,存在信息损失。这一缺陷可能可以为后续一些 Multi-View Projection + PoseC3D 的工作所弥补。
开源实现 PYSKL
基于 MMAction2(https://github.com/open-mmlab/mmaction2),我们最新开发了骨骼动作识别代码库 PYSKL,在已经完成的第一次 release 中,支持了三个模型 PoseC3D [1], ST-GCN [3], ST-GCN++[2] 。PYSKL 具备如下特点:
-
模型完整,实现优秀:PYSKL 同时支持了 3D-CNN 和 GCN 两大类方法。对于 PoseC3D,我们 release 的模型覆盖了多个数据集与主干网络,并对大部分数据集全面覆盖了 Joint, Limb 两个模态。对于基于 GCN 的方法,我们参照 AA-GCN [8] 的实践,release 的权重文件全面覆盖了 Joint, Bone, Joint Motion, Bone Motion 四个模态。用户可以基于 release 的 config 和 weight 轻松复现相关数据集。同时,基于我们提出的良好实践训练的 PoseC3D 和 ST-GCN++,在多个 benchmark 上都取得了排名前列的性能。 -
代码简练:专注于骨骼动作识别,PYSKL 对代码进行了精简,只保留主要功能,去掉了冗余的 code。其主目录下只保留少于 5000 行代码,少于 MMAction2 的三分之一。 -
易于上手:用户可直接使用 PYSKL 中提供的 pickle 文件进行训练与测试。同时,我们提供了工具来对 2D / 3D 骨骼数据进行可视化。
链接:https://github.com/kennymckormick/pyskl
Reference
[1] Revisiting skeleton-based action recognition:https://arxiv.org/abs/2104.13586
[2] https://github.com/kennymckormick/pyskl:https://github.com/kennymckormick/pyskl
[3] Spatial temporal graph convolutional networks for skeleton-based action recognition:https://scholar.google.com/citations%3Fview_op%3Dview_citation%26hl%3Den%26user%3DtAgSyxIAAAAJ%26citation_for_view%3DtAgSyxIAAAAJ%3Ad1gkVwhDpl0C
[4] Two-stream adaptive graph convolutional networks for skeleton-based action recognition:https://openaccess.thecvf.com/content_CVPR_2019/html/Shi_Two-Stream_Adaptive_Graph_Convolutional_Networks_for_Skeleton-Based_Action_Recognition_CVPR_2019_paper.html
[5] Channel-wise topology refinement graph convolution for skeleton-based action recognition:https://openaccess.thecvf.com/content/ICCV2021/html/Chen_Channel-Wise_Topology_Refinement_Graph_Convolution_for_Skeleton-Based_Action_Recognition_ICCV_2021_paper.html
[6] Potion: Pose motion representation for action recognition:https://openaccess.thecvf.com/content_cvpr_2018/html/Choutas_PoTion_Pose_MoTion_CVPR_2018_paper.html
[7] Disentangling and unifying graph convolutions for skeleton-based action recognition:https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_Disentangling_and_Unifying_Graph_Convolutions_for_Skeleton-Based_Action_Recognition_CVPR_2020_paper.html
[8] Skeleton-based action recognition with multi-stream adaptive graph convolutional networks:https://ieeexplore.ieee.org/abstract/document/9219176/
公众号后台回复“画图模板”获取90+深度学习画图模板~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




