加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
前言
目前,三维重建技术已在游戏、电影、测绘、定位、导航、自动驾驶、VR/AR、工业制造以及消费品领域等方面得到了广泛的应用。方法同样也层出不穷,我们将这些方法依据原理分为两类:
基于传统多视图几何的三维重建算法
基于深度学习的三维重建算法
总地来说,尽管目前传统的三维重建算法依旧占据研究的主要部分,但是越来越多的研究者开始关注于用CNN探索三维重建,或者说,两者之间的交叉与融合。
有人问,在三维重建中引入深度学习方法有什么意义?我将意义概括为三部分:
一项名为 Code SLAM1 的工作,这项研究获得了CVPR 2018年的best paper提名奖,研究利用神经网络框架,并结合图像几何信息实现了单目相机的稠密SLAM。主要贡献在于使用了深度学习方法从单张图像中用神经网络提取出若干个基函数来表示场景的深度,这些基函数表示可以极大简化传统几何方法中的优化问题。显然,深度学习方法的引入可以给传统方法的性能提升提供新的思路,而以前,这部分工作大多由机器学习方法来做。
业界对算法的鲁棒性要求比较高,因此多传感器、乃至多种算法的融合以提升算法鲁棒性是个必然趋势,而深度学习在一些场景中具有天然优势,比如不可见部分的建模,传统算法就很难凭借“经验”来估计物体的深度。
动物跟人类直接基于大脑而非严格的几何计算来进行物体的三维重建,那么直接基于深度学习的方法在原理上也是可行的。特别需要注意的是,在一些研究中,有些方法直接基于单张图像(非单目,单目指利用单个摄像头)进行三维重建。理论上讲,单张图像已经丢失了物体的三维信息,因此在原理上即不能恢复深度信息,但是人类又能凭借经验大致估计物体的距离,因而也具有一定的“合理性”。
两者形成了各自的理论和体系,但未来三维重建领域研究一定是传统优化方法与深度学习的结合。目前,这方面研究仍处于起步阶段,还有许多问题亟待解决。下面的综述主要侧重于深度学习方法,但也仅列出重要文献,更详细的综述将会在公众后续的文章中介绍。
基于传统多视图几何的三维重建算法
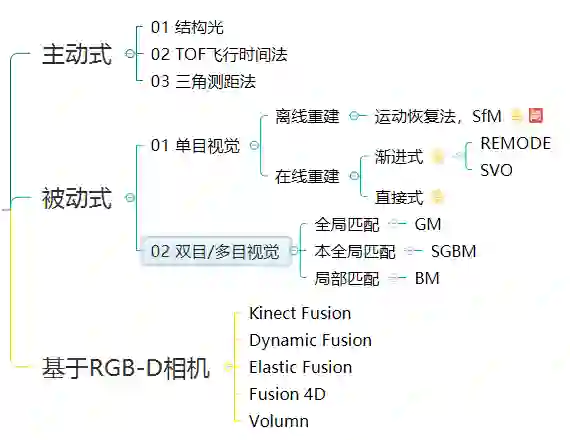
传统的三维重建算法按传感器是否主动向物体照射光源可以分为主动式和被动式 两种方法。这些年,也有不少研究直接基于消费级的 RGB-D 相机进行三维重建,如基于微软的 Kinect V1 产品,同样取得了不错的效果。基于传统多视图几何的三维重建算法概括如下:
指通过传
感器主动地向物体照射信号,然后依靠解析返回的信号来获得物体的三维信息,常见的有:
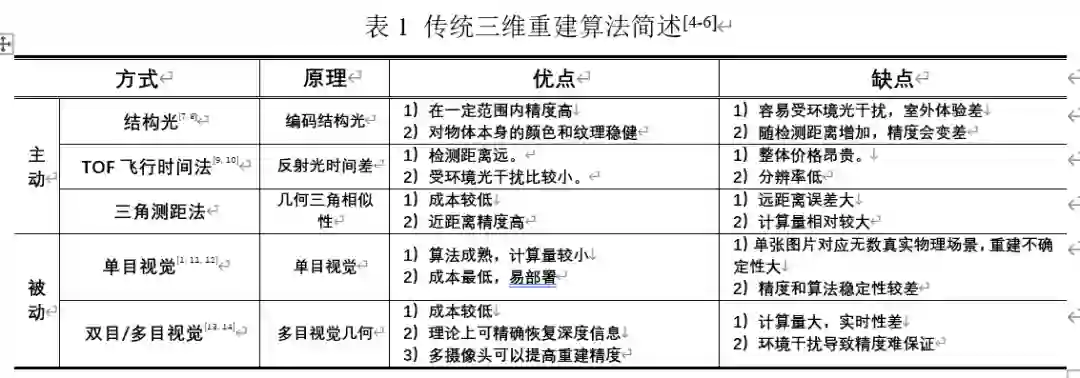
结构光法依靠投影仪将编码的结构光投射到被拍摄物体上,然后由摄像头进行拍摄。由于被拍摄物体上的不同部分相对于相机的距离精度和方向不同,结构光编码的图案的大小和形状也会发生改变。这种变化可以被摄像头捕获,然后通过运算单元将其换算成深度信息,进而获取物体的三维轮廓信息。这种方法缺点是容易受环境光干扰,因此室外体验差。另外,随检测距离增加,其精度也会变差。目前,一些研究通过增大功率、改变编码方式等形式解决这些问题,取得了一定的效果。
TOF 飞行时间法依靠通过向目标连续发送光脉冲,然后依据传感器接收到返回光的时间或相位差来计算距离目标的距离。但显然这种方式足够的精度需要极为精确的时间测量模块,因此成本相对较高。好处是这种方法测量距离比较远,受环境光干扰比较小。目前这方面研究旨在降低计时器良品率及成本,相应的算法性能也在提升。
三角测距法,即依据三角测距原理,不同于前两者需要较为精密的传感器,三角测距法整体成本较低,并且在近距离的时候精度较高,因而广泛应用于民用和商用产品中,如扫地机器人中。但三角测距的测量误差与距离有关,随着测量距离越来越大,测量误差也越来越大,这是由三角测量的原理导致的,不可避免。
直接依靠周围环境光源来获取RGB图像,通过依据多视图几何原理对图像进行解析,从而获取物体的三维信息。常见的依据原理可以分为:
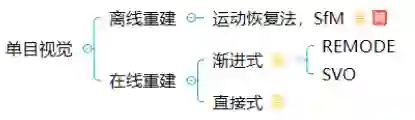
单目视觉只使用单一摄像头作为采集设备,具有低成本、易部署等优点。其依靠一段时间内获得的连续图像的视差来重建三维环境。但其存在固有的问题:单张图像可能对应无数真实物理世界场景(病态),因此使用单目视觉方法从图像中估计深度进而实现三维重建的难度较大。依据原理,可以分类为:
目前这种算法广泛应用于手机等移动设备中,常见的算法有SfM,REMODE和SVO等。
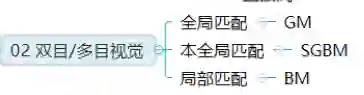
双目视觉主要利用左右相机得到的两幅校正图像找到左右图片的匹配点,然后根据几何原理恢复出环境的三维信息。但该方法难点在于左右相机图片的匹配,匹配地不精确都会影响最后算法成像的效果。多目视觉采用三个或三个以上摄像机来提高匹配的精度,缺点也很明显,需要消耗更多的时间,实时性也更差。
这两种方法理论上都可较精确恢复深度信息,但实际上受拍摄条件的影响,其精度往往无法得到保证。常见的有SGM和SGBM算法等,其中自动驾驶数据集KITTI中,排名前五十的算法几乎有一半都是对SGM的改进。
相机可以基于主动式、被动式不同原理,优点在于基于这些设备的算法更具备实用性。
近年来,也有不少研究直接基于消费级的RGB-D相机进行三维重建,如在微软的Kinect V1、V2产品上,取得了不错的效果。最早,由帝国理工大学的Newcombe等人于2011年提出的Kinect Fusion开启了RGB相机实时三维重建的序幕。此后有 Dynamic Fusion和Bundle Fusion等算法。
这些方法它们各自有着各自的优点和缺点,同样有各自所适用的应用范围。以上为想要入门基于深度学习进行三维重建领域的同学简要介绍了这些方法,如需要深入了解,请仔细阅读相关文献,SfM和多视图几何等经典算法作为入门三维重建领域的基础永远都不会过时。
基于深度学习的三维重建算法
我们将基于深度学习的三维重建算法简要地分为三部分,更详细的文献综述将会在后续的公众号的系列文章中做介绍:
1 在传统三维重建算法中引入深度学习方法进行改进
因为CNN在图像的特征匹配上有着巨大优势,所以这方面的研究有很多,比如:
其基于深度递归卷积神经网络(RCNN)直接从一系列原始RGB图像(视频)中推断出姿态,而不采用传统视觉里程计中的任何模块,改进了三维重建中的视觉里程计这一环。
其将 SfM 算法中的一环集束调整(Bundle Adjustment, BA)优化算法作为神经网络的一层,以便训练出更好的基函数生成网络,从而简化重建中的后端优化过程。
• Code SLAM,如之前所提,其通过神经网络提取出若干个基函数来表示场景的深度,这些基函数可以简化传统几何方法的优化问题。
2. 深度学习重建算法和传统三维重建算法进行融合,优势互补
CNN-SLAM13将CNN预测的致密深度图和单目SLAM的结果进行融合,在单目SLAM接近失败的图像位置如低纹理区域,其融合方案给予更多权重于深度方案,提高了重建的效果。
3. 模仿动物视觉,直接利用深度学习算法进行三维重建
2D图片,每个像素记录从视点到物体的距离,以灰度图表示,越近越黑;
因而,依据处理的数据形式不同我们将研究简要分为三部分:1)基于体素;2)基于点云;3)基于网格。而基于深度图的三维重建算法暂时还没有,因为它更多的是用来在2D图像中可视化具体的三维信息而非处理数据。
(1)基于体素
体素,作为最简单的形式,通过将2D卷积扩展到3D进行最简单的三维重建:
该方法是用深度学习做三维重建的开山之作,基于体素形式,其直接用单张图像使用神经网络直接恢复深度图方法,将网络分为全局粗估计和局部精估计,并用一个尺度不变的损失函数进行回归。
Christopher等人基于体素形式提出的3D-R2N2模型使用Encoder-3DLSTM-Decoder的网络结构建立2D图形到3D体素模型的映射,完成了基于体素的单视图/多视图三维重建(多视图的输入会被当做一个序列输入到LSTM中,并输出多个结果)。
但这种基于体素的方法存在一个问题,提升精度即需要提升分辨率,而分辨率的增加将大幅增加计算耗时(3D卷积,立次方的计算量)。
(2)基于点云
相较而言,点云是一种更为简单,统一的结构,更容易学习,并且点云在几何变换和变形时更容易操作,因为其连接性不需要更新。但需要注意的是,点云中的点缺少连接性,因而会缺乏物体表面信息,而直观的感受就是重建后的表面不平整。
该方法是用点云做三维重建的开山之作,最大贡献在于解决了训练点云网络时候的损失问题,因为相同的几何形状可能在相同的近似程度上可以用不同的点云表示,如何用恰当的损失函数来进行衡量一直是基于深度学习用点云进行三维重建方法的难题。
该方法通过对场景的点云进行处理,融合三维深度和二维纹理信息,提高了点云的重建精度。
(3)基于网格
相较而言,网格的表示方法具有轻量、形状细节丰富的特点,重要是相邻点之间有连接关系。因而研究者基于网格来做三维重建。我们知道,网格是由顶点,边,面来描述3D物体的,这正好对应于图卷积神经网络的M=(V,E,F)所对应。
用三角网格来做单张RGB图像的三维重建,相应的算法流程如下:
Step1:对于任意的输入图像都初始化一个椭球体作为初始三维形状。
Step3:对三维网格不断进行变形,最终输出物体的形状。
模型通过四种损失函数来约束形状,取得了很好的效果。贡献在于用端到端的神经网络实现了从单张彩色图直接生成用网格表示的物体三维信息。
总结
1. 在传统三维重建算法中引入深度学习方法进行改进;
2. 深度学习重建算法和传统三维重建算法进行融合,优势互补;
3. 模仿动物视觉,直接利用深度学习算法进行三维重建,
包括
基于体素、
基于点云
和
基于网格。
极市平台视觉算法季度赛,提供真实应用场景数据和免费算力,特殊时期,一起在家打比赛吧!
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()