资源受限场景下的深度学习图像分类:MSDNet多尺度密集网络
深度学习的典型应用是图像分类问题。用深度学习技术进行图像分类,表现出众,甚至超过了人类的水平。然而,天下没有免费的午餐。深度学习对算力资源的要求也十分苛刻。偏偏在某些资源受限的场景下,仍然需要应用深度学习进行图像分类。这是一个巨大的技术挑战。
资源受限场景
资源受限的场景有不少,其中最主要的两种:
设备本身的性能限制,比如移动设备。
海量数据。许多大公司有海量图像需要处理,亟需在维持分类精确度的前提下,优化性能。
前者常用的设定是anytime classification(随时分类)。比如,用手机拍一朵花,深度学习模型可能会先返回“花”这一粗糙的分类结果,识别出这是在拍摄花卉,调用相应的场景模式(比如,微距花卉)。如果用户拍摄后在当前界面停留较久,那么模型再进一步返回具体的花的种类(用户可能想知道刚拍了什么花)。如果直接返回具体类别,可能需要很长时间,这时用户可能早已按下快门,来不及调用相应的场景模式。
除了以上场景外,另一个anytime classification的典型应用场景是适配不同设备。移动设备多种多样,性能各异。anytime classification意味着我们只需训练一个模型,然后部署到不同的设备上。在性能较差的设备上,模型给出粗糙的分类。而在性能较好的设备上,模型给出精细的分类。这样,我们无需为各种千奇百怪的模型一一训练模型。
而后者常用的设定是budgeted batch classification(预算批分类)。和anytime classification不同,这次的时间限制不在单张图片上(比如在用户按下快门之前),而是在整批图像上。对于这一场景而言,要处理的图像的分类难度不一定一样。
比如,下图左边的马很好检测,即使是一个简单的网络都能检测出来。而右边的马,因为拍摄角度关系,不容易检测,需要算力负担更重的网络架构。

图片来源:Pixel Addict and Doyle;许可:CC BY-ND 2.0
如果整批图像都用简单模型分类,那么有些图像不能被正确分类。相反,如果整批图像都用复杂模型分类,那么在简单图像上浪费了很多资源。因此,我们需要一种弹性的模型,既可以使用较少的资源进行粗糙的分类,也可以使用更多的资源进行精细的分类。
我们看到,不管是anytime classification,还是budgeted batch classification,都要求模型具有既可以进行粗糙分类,又能进行精细分类的特性。所以,尽管表面上这两个场景非常不一样(一个的典型应用场景是移动设备上的单张图像分类,另一个的典型应用场景是大公司高性能设备上的海量图像分类),但其内在需求的一致性,意味着我们可以构建一个统一的模型来应对这两个场景的挑战(或者,至少是大体思路一致的模型架构,然后根据这两个场景的不同进行局部调整)。
模型的直觉
应对上面提到的问题,最简单直接的方案就是使用多个不同的网络,每个网络的能力不同(相应的算力需求也不一样)。具体而言,使用一组网络,每个网络的能力依次递增。然后依次使用这一组网络进行分类。在anytime classification场景下,返回最近的分类结果。而在budgeted batch classification场景下,当网络的结果置信度足够高时,就返回结果,然后跳过后续的网络,直接分类下一张图像。
这个方案非常直截了当,易于理解,易于实现。问题在于,多个模型所做的工作有很多是重复的(比如都需要通过卷积层提取特征之类),而使用多个模型,无法实现复用,每个模型都要从头开始。对资源受限环境而言,这样的浪费是不可接受的。
为了实现复用,可以把多个网络整合成一个模型,共用许多组件,得到一个基于级联分类层的深度网络。
但是,CNN(卷积神经网络)的架构原本不是为这种级联设计的,因此这样简单的堆叠分类层,会导致两个问题:
CNN的不同层在不同尺度上提取图像的特征。一般而言,靠前的层提取精细的特征(局部),而靠后的层提取粗糙的特征(整体)。而分类高度依赖整体的粗糙特征。前面的分类层因为缺乏粗糙尺度上的特征,效果非常差。
加入的分类层可能对特征提取层造成干扰。换句话说,靠前的分类层可能影响最终分类层的效果。
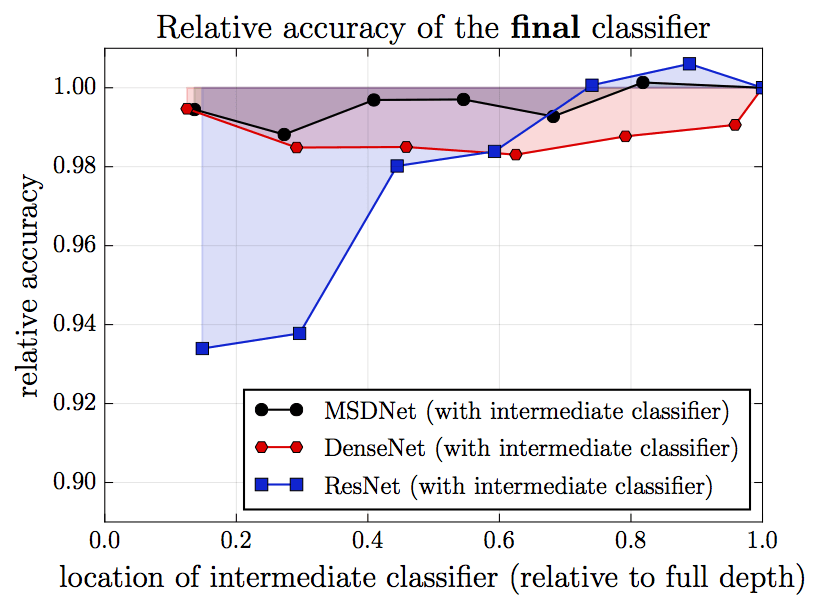
下图为不同网络架构在CIFAR-100上的分类结果比较。其中,纵轴为相对精确度(最终分类层的精确度为1),横轴为中间分类层的相对位置(最终分类层的位置为1)。黑色表示MSDNet(新提出的架构),红色表示DenseNet,蓝色表示ResNet(作为比较对象)。我们看到,越靠后的分类层,分类的精确度越高。但是,在DenseNet和ResNet中,靠前的几个分类层表现特别差,和靠后的分类层的差距特别大。这一点在ResNet上尤为明显。这正是因为靠前的几个分类层缺乏粗糙尺度上的特征。
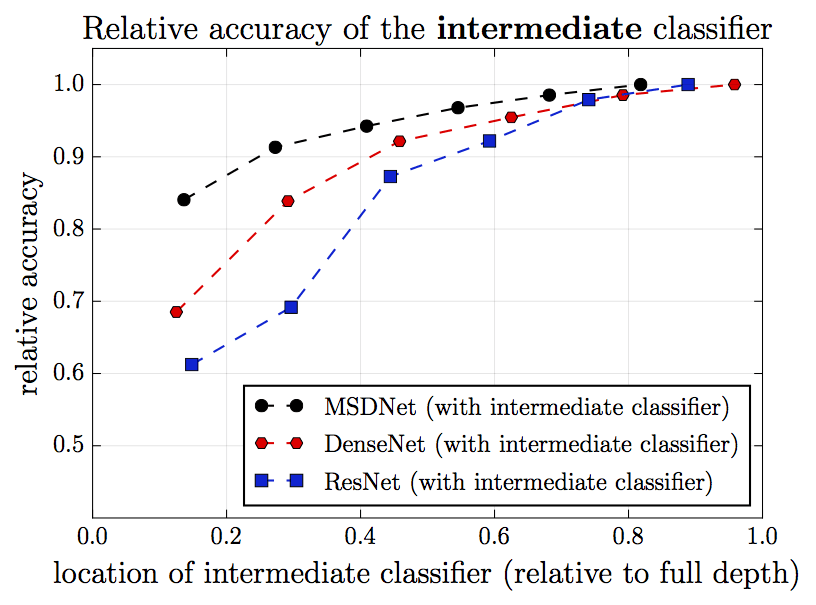
再看一张图。这张图中,每次在网络中插入一个中间分类层,横轴表示插入的单个中间分类层的位置,纵轴为相应的最终分类层的表现。我们看到,在ResNet中,插入的中间层的位置越靠前,最终分类层的表现就越差。这是因为插入的分类层干扰了特征提取层的运作。之所以插入的位置越靠前,最终分类层的表现就越差,这大概是因为,插入的分类层越靠前,相应的特征提取层就越是为较近的中间分类层的表现这一“短期目标”进行优化,相应地忽略了较远的最终分类层这一“长期目标”的需求。
那么,该如何处理这两个问题呢?
我们先考虑第二个问题,分类层的干扰问题。如前所述,特征提取层为较近的中间分类层优化,而忽视了较远的最终分类层的需求。那么,如果我们把特征提取层也和靠后的分类层连接起来呢?通过特征提取层和之后的分类层的直接连接,不就可以避免过于为靠前的分类层优化,忽视靠后的分类层了吗?事实上,Gao Huang等在CVPR 2017上发表的DenseNet就提供了这样的特性。
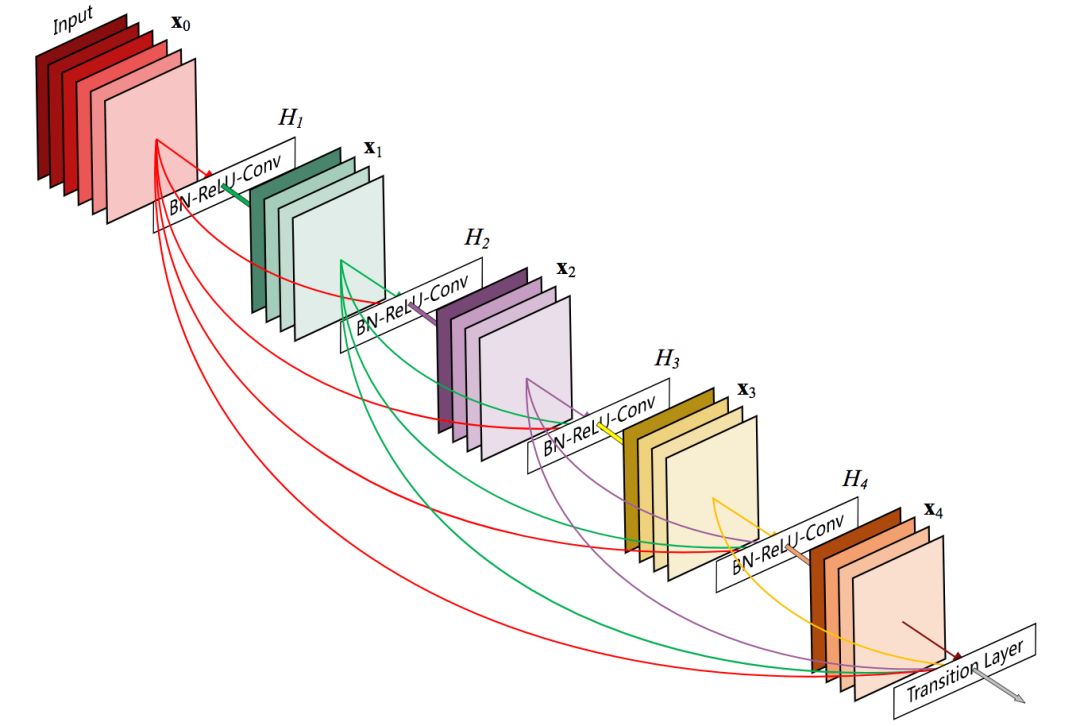
5层的DenseNet组件
之前的图片也表明,DenseNet下,前面插入分类层,对最终分类层的影响不大。
至于第一个缺乏粗糙尺度特征的问题,可以通过维护一个多尺度的特征映射来解决。
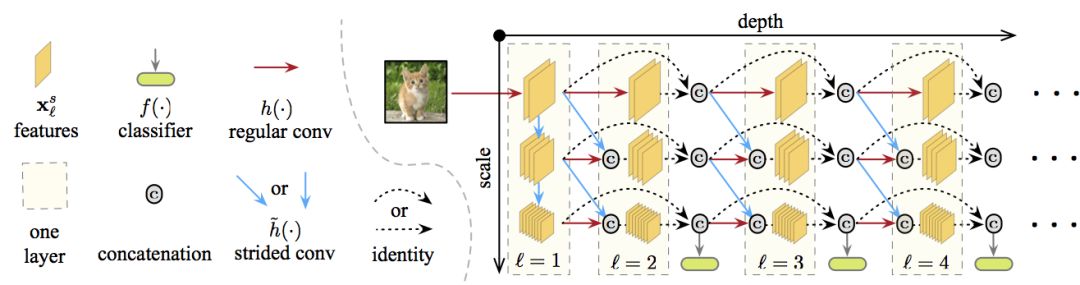
在上图中,深度由左往右依次加深,尺度由上往下,从精细到粗糙,所有分类器都使用粗糙层的特征(粗糙层和分类高度相关)。特定层和尺度上的特征映射通过连接以下一个或两个卷积计算得出:
同一尺度上之前层的通常卷积操作的结果(图中横向的红线)
(如果可能的话,)前一层更精细尺度上的特征映射的步进卷积操作(图中对角的蓝线)。
结合这两种,就得到了多尺度密集网络(Multi-Scale Dense Network),简称MSDNet.
MSDNet架构
如前所示,MSDNet的架构为下图:
第一层 第一层(l=1)比较特别,因为它包含垂直连接(图中蓝线)。它的主要作用是在所有尺度上提供表示“种子”。粗糙尺度的特征映射通过降采样获得。
后续层 后续层遵循DenseNet的结构,特定层和尺度上的特征映射的连接方式如上一节所述。第一层和后续层的输出详见下图。

分类器 分类器同样遵循DenseNet的密集连接模式。每个分类器由两个卷积层、一个平均池化层、一个线性层组成。如前所述,在anytime设定中,当预算时间用尽后,输出最近的预测。在batch budget设定下,当分类器fk的预测置信度(softmax概率的最大值)超过预先定义的阈值θk时退出。在训练前,计算网络到达第k个分类器的算力开销Ck。相应地,一个样本在分类器k处退出的概率为qk = z(1-q)k-1q. 其中,q为样本到达分类器且得到置信度足够的分类并退出的退出概率。我们假定q在所有层上都是恒定的。z是一个归一化常数,确保∑kp(qk) = 1. 在测试时,需要确保分类测试集Dtest中的所有样本的总开销不超过期望预算B。也就是|Dtest|∑kqkCk ≤ B这一限制。我们可以在验证集上求解这一限制中的q值,进而决定θk.
损失函数 在训练中,所有分类器使用交叉熵损失函数L(fk),并最小化加权累积损失:
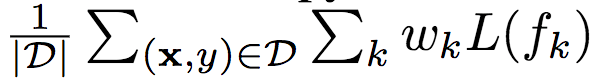
上式中,D为训练集,wk为第k个分类器的权重,wk ≥ 0. 如果预算分布P(B)是已知的,我们可以使用权重wk结合关于预算B的先验知识。在实践中,我们发现,所有损失函数使用同样的权重效果较好。
网络化简和惰性演算 以上的网络架构可以通过两种直截了当的方法进一步化简。首先,在每层维持所有尺度并不高效。一个简单的降低网络尺寸的策略是将网络分为S块,在第i块中仅仅保留最粗糙的(S - i + 1)尺度。移除尺度的同时,在块之间加上相应的过渡层,使用1x1卷积合并连接起来的特征,并在通过步进卷积将精细尺度的特征传给粗糙尺度之前截取一半的频道。
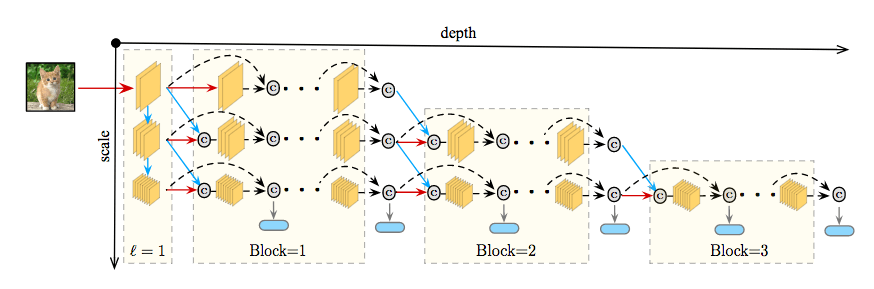
其次,由于第l层的分类器只使用最粗糙尺度的特征,第l层的更精细的特征映射(以及S-2层之前的一些更精细的特征映射)不影响该分类器的预测。因此,只沿着下一个分类器所需路径传播样本可以最小化不必要的计算。研究人员称这一策略为惰性演算。
试验
数据集
研究人员在3个图像分类数据集上评估了MSDNet的效果:
CIFAR-10
CIFAR-100
ILSVRC 2012(ImageNet)
CIFAR数据集包括50000张训练图像和10000张测试图像,图像大小为32x32像素。研究人员留置了5000张训练图像作为验证集。CIFAR-10包含10个分类,CIFAR-100包含100个分类。研究人员应用了标准的数据增强技术:图像每边补零4个像素,接着随机剪切以得到32x32图像。图像以0.5概率水平翻转,通过减去频道均值和除以频道标准差进行归一化。
ImageNet数据集包含1000分类,共计一百二十万张训练图像和50000张验证图像。研究人员留置50000张训练图像以估计MSDNet的分类器的置信度阈值。研究人员应用了Kaiming He等在Deep Residual Learning for Image Recognition(arXiv:1512.03385)中提出的数据增强技术。在测试时,图像被缩放到256x256像素,然后中央剪切为224x224像素。
训练细节 在CIFAR数据集上,所有模型(包括基线模型)使用随机梯度下降(SGD)训练,mini-batch大小为64. 使用了Nesterov动量法,动量权重为0.9(不带抑制),权重衰减为10-4。所有模型训练300个epoch,初始学习率为0.1,在150和225个epoch后除10. ImageNet的优化规划与此类似,只不过mini-batch大小增加到256,所有模型训练90个epoch,在30和60个epoch后降低学习率。
用于CIFAR数据集的MSDNet使用3个尺度。第一层使用3x3卷积(Conv),组归一化(BN),ReLU激活。后续层遵循DenseNet的设计,Conv(1x1)-BN-ReLU-Conv(3x3)-BN-ReLU. 3个尺度上的输出频道数分别为6、12、24. 每个分类器包含2个降采样卷积层(128维3x3过滤器),1个2x2平均池化层,1个线性层。
用于ImageNet的MSDNet使用4个尺度,相应地,每层生成16、32、64、64特征映射。在传入MSDNet的第1层之前,原始图像先经过7x7卷积和3x3最大池化(步长均为2)转换。分类器的结构和用于CIFAR的MSDNet相同,只不过每个卷积层的输出频道数和输入频道数一样。
CIFAR数据集上,用于anytime设定的MSDNet有24层。分类器对第2x(i+1)层的输出进行操作,其中i=1,...,11. 而用于budgeted batch设定的MSDNet深度为10到36层。第k个分类器位于第(∑ki=1i)层。
ImageNet上的MSDNet(anytime和budgeted batch设定)使用4个尺度,相应地,第i个分类器操作第(kxi+3)层的输出,其中i=1,...,5,k=4,6,7.
ResNet有62层,每个分辨率包含10个残差块(共3个分辨率)。研究人员在每个分辨率的第4、8个残差块训练中间分类器,共计6个中间分类器(再加上最终分类器)。
DenseNet有52层,包含3个密集块,每块有16层。6个中间层位于每块的第6、12层。
所有模型均使用Torch框架实现,代码见GitHub(gaohuang/MSDNet)。
CIFAR-10
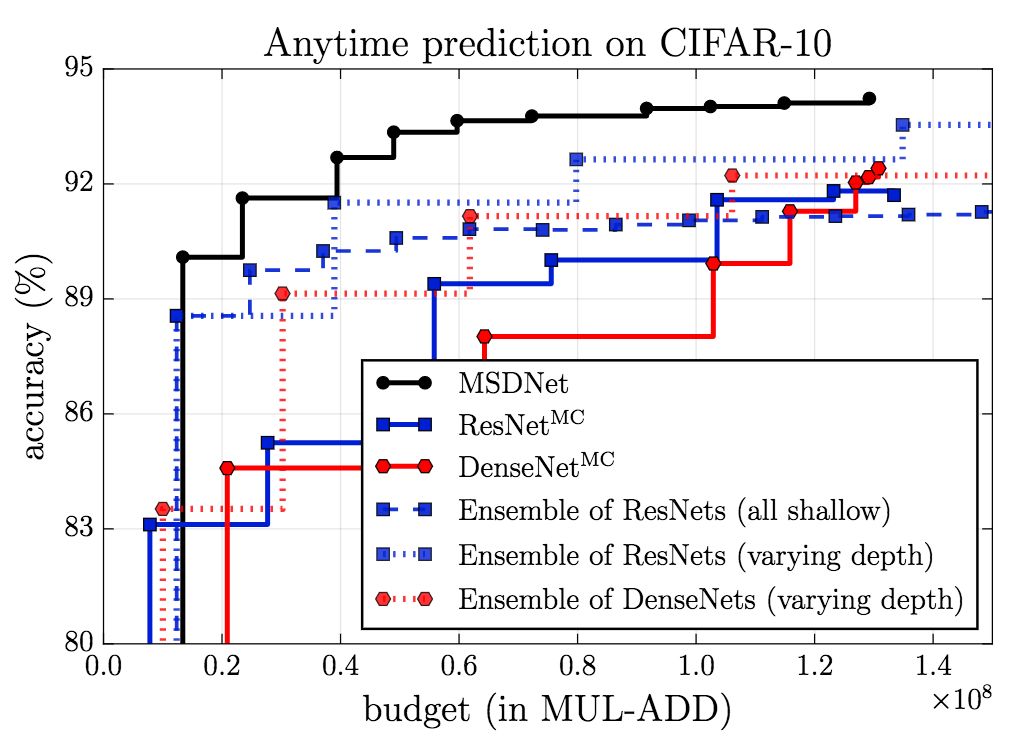
在CIFAR-10上,无论是在anytime设定下,还是在budgeted batch设定下,MSDNet的表现(精确度)都显著超过基线。
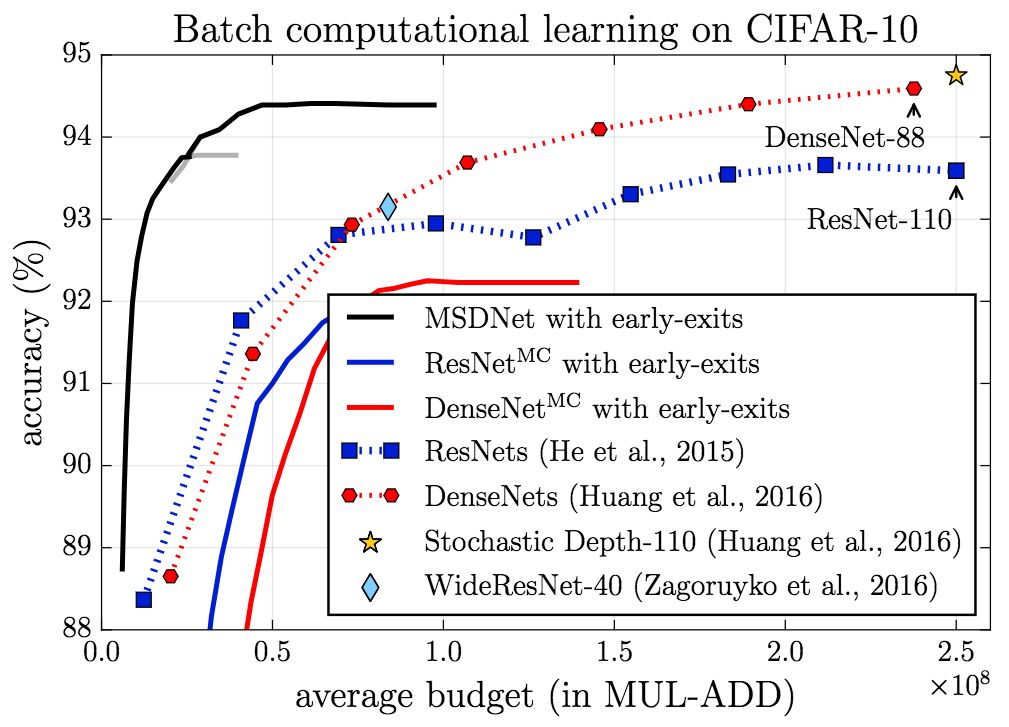
CIFAR-100
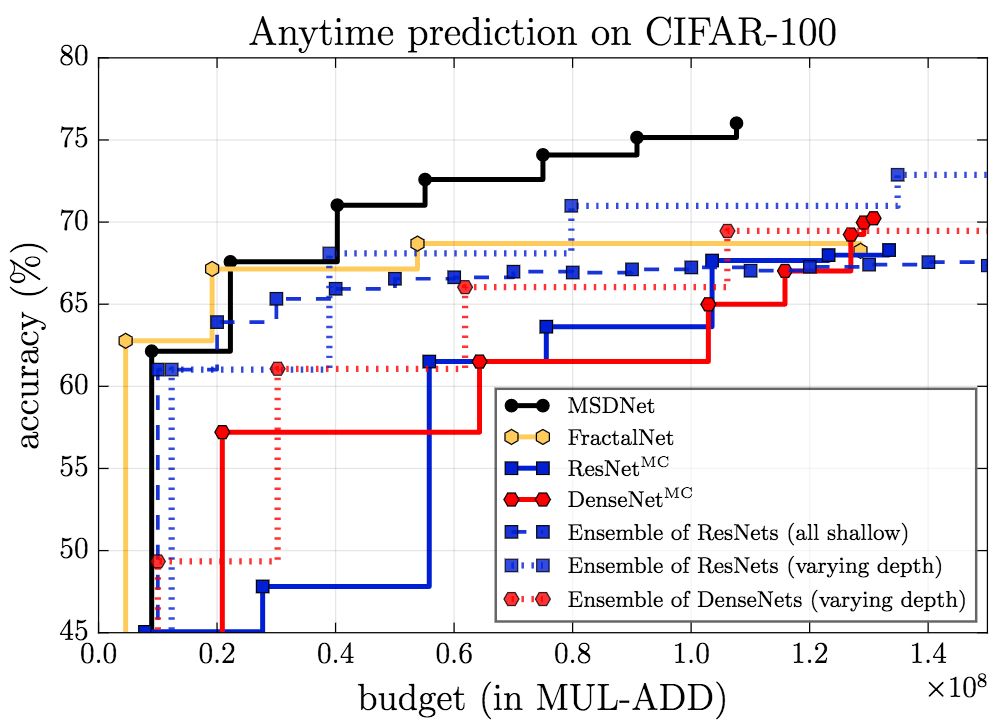
上图为anytime设定下的结果,可以看到,除了在预算极小的情形下,MSDNet的表现都超过了其他模型。在预算极小的情形下,集成方法具有优势,因为预测是由第一个(小型)网络作出的,这一网络专门为预算极小的情形优化。
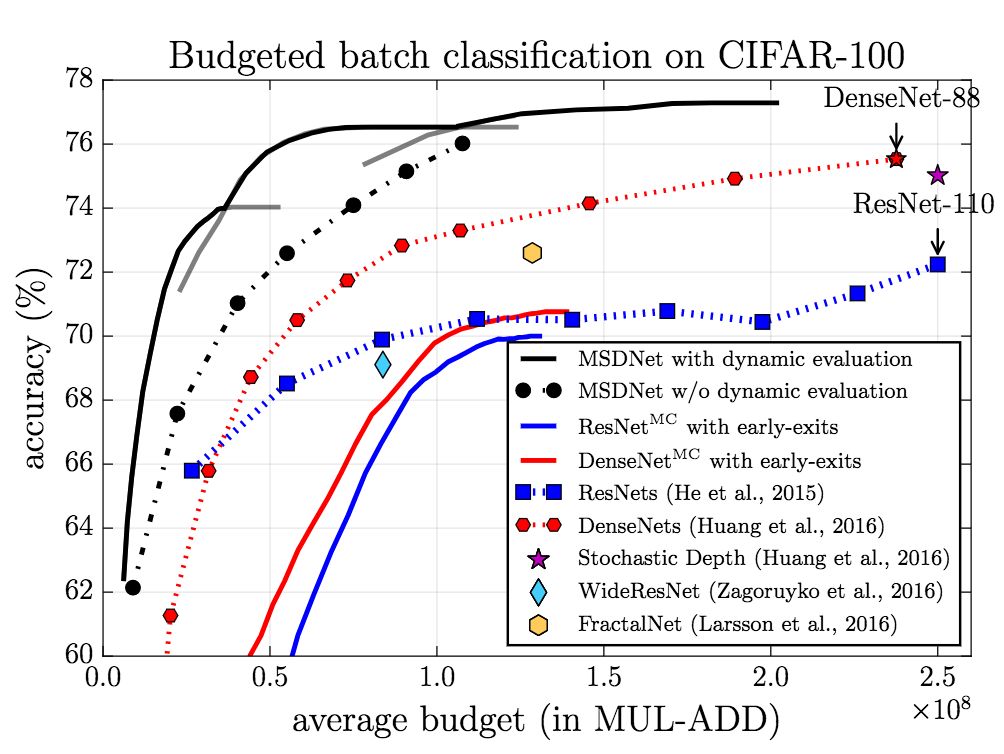
而在budgeted batch设定下,MSDNet的表现优于其他模型。特别值得注意的是,MSDNet仅使用110层ResNet的十分之一的算力预算就达到了相当的表现。
ImageNet
MSDNet在ImageNet上的表现同样让人印象深刻。
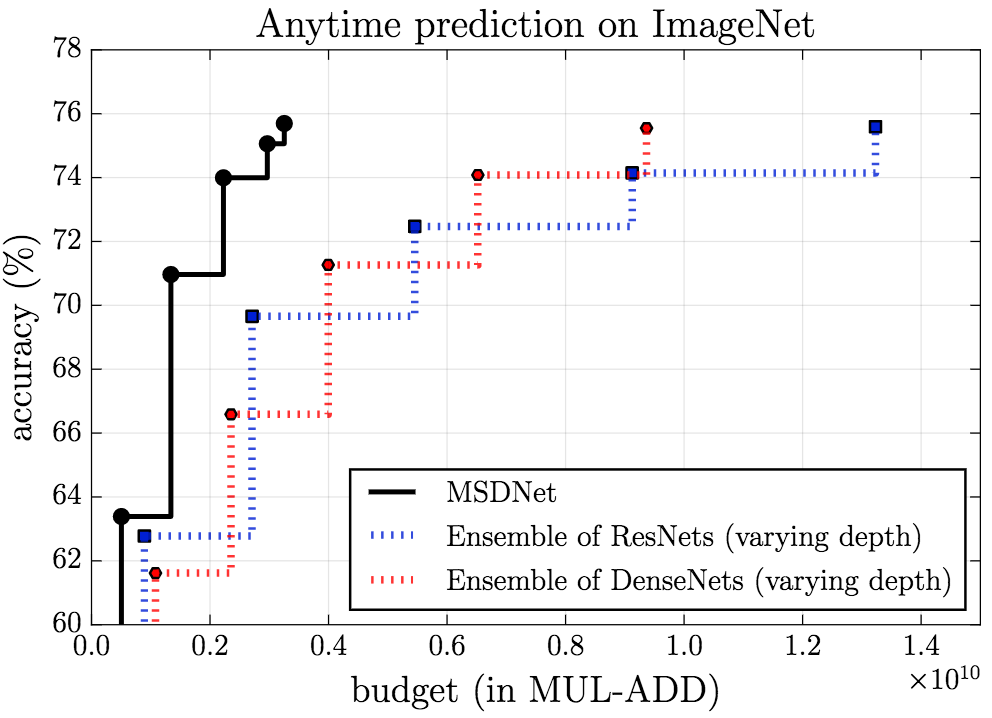
anytime
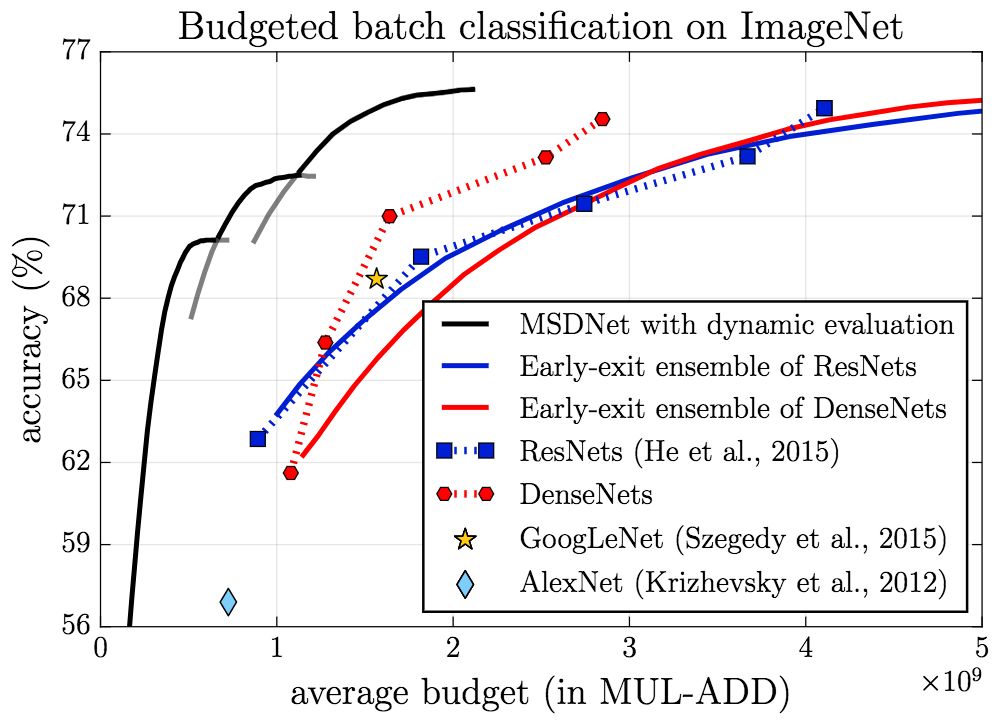
budgeted batch
消融测试
消融测试验证了密集连接、多尺度特征、中间分类器的有效性。
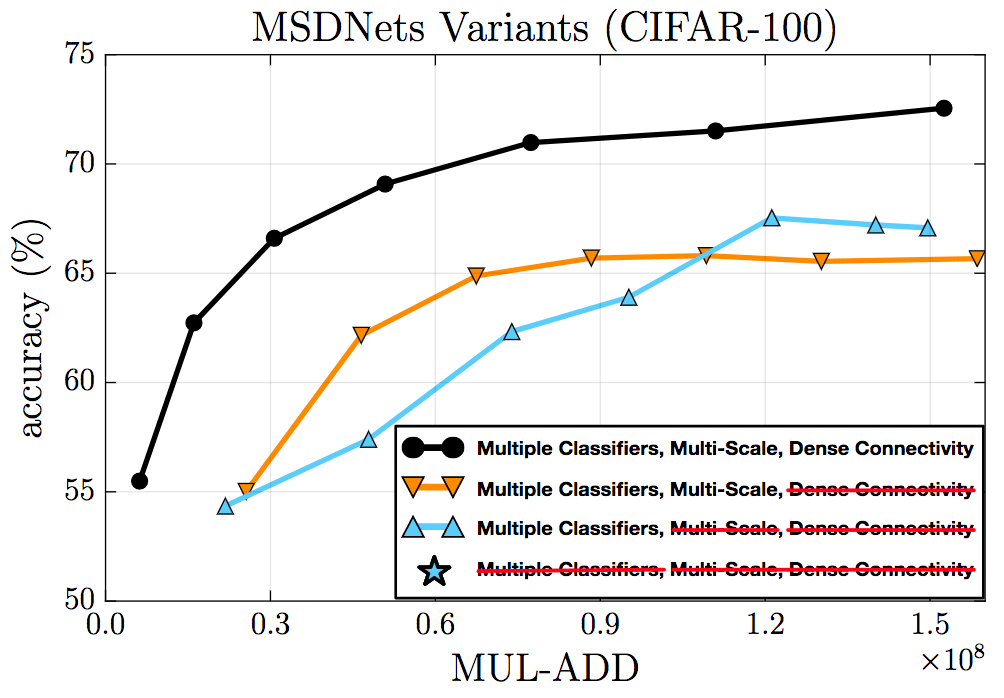
CIFAR-100上的消融测试
此外,研究人员还从ImageNet随机选择了一些图片。下图分为两行,上面一行的图像容易分类,下面一行的图像较难分类。MSDNet的第一个分类器正确预测了“容易”图像的分类,而没能成功预测“困难”图像的分类,而MSDNet的最终分类器正确预测了“困难”图像的分类。

结语
在刚结束的ICLR 2018上,本文作者做了口头报告(5月1日 04:00 -- 04:15 PM;Exhibition Hall A)。
研究人员打算以后进一步探索分类以外的资源受限深度架构,比如图像分割。此外,研究人员也有意探索更多进一步优化MSDNet的方法,比如模型压缩,空间适应计算,更高效的卷积操作。