解析京东大数据下高效图像特征提取方案
本文主要分享英特尔和京东在基于Spark和BigDL的深度学习技术在搭建大规模图片特征提取框架上的实战经验。
背景
图像特征提取被广泛地应用于相似图片检索,去重等。在使用BigDL框架(下文即将提到)之前,我们尝试过在多机多GPU卡、GPU集群上分别开发并部署特征抽取应用。但以上框架均存在比较明显的缺点:
♦ 在GPU集群中,以GPU卡为单位的资源分配策略非常复杂,资源分配容易出问题,如剩余显存不够而导致OOM和应用崩溃。
♦ 在单机情况下,相对集群方式,需要开发者手动做数据分片、负载和容错。
♦ GPU模式的应用以Caffe为例有很多依赖,包括CUDA等等,增加了部署和维护的难度,如碰到不同操作系统版本和GCC版本有问题时,都需要重新编译打包。
以上问题使得基于GPU的前向程序从架构上面临诸多技术应用挑战。
再来看看场景本身。因为很多图片的背景复杂,主体物体占比通常较小,所以为了减少背景对特征提取准确性的干扰,需要将主体从图片中分离出来。自然地,图片特征提取的框架分为两步,先用目标检测算法检测出目标,然后用特征提取算法提取目标特征。在这里,我们采用SSD[1] (Single shot multibox detector) 进行目标检测,并用DeepBit[2]网络进行特征提取。
京东内部有海量的(数亿张以上)商品图片存在于主流的分布式的开源数据库里。因此如何高效地在大规模分布式环境下进行数据检索和处理,是图片特征提取流水线一个很关键的问题。现有的基于GPU的方案在解决上述场景的需求中面临着另外一些挑战:
♦ 数据下载耗费很长的时间,基于GPU的方案不能很好地对其进行优化。
♦ 针对分布式的开源数据库中的图片数据,GPU方案的前期数据处理过程很复杂,没有一个成熟的软件框架用于资源管理,分布式数据处理和容错性管理等。
♦ 因为GPU软件和硬件框架的限制,扩展GPU方案去处理大规模图片有很大的挑战性。
BigDL集成方案
在生产环境中,利用现有的软件和硬件设施,将大幅提高生产效率(如减少新产品的研发时间),同时降低成本。基于在这个案例中,数据存储在大数据集群中主流的分布式开源数据库上,如果深度学习应用能利用已有的大数据集群(如Hadoop或Spark集群)进行计算,便可非常容易地解决上述的挑战。
Intel开源的BigDL项目[3],是在Spark上的一个分布式深度学习框架,提供了全面的深度学习算法支持。BigDL借助Spark平台的分布式扩展性,可以方便地扩展到上百或上千个节点。同时BigDL利用了Intel MKL数学计算库以及并行计算等技术,在Intel Xeon服务器上可以达到很高的性能(计算能力可取得媲美主流GPU的性能)。
在我们的场景中,BigDL为支持各种模型(检测,分类)进行定制开发;模型从原来只适用于特定 环境移植到了支持通用模型(Caffe,Torch,Tensorflow)BigDL大数据环境 ;整个pipeline全流程获得了优化提速。
通过BigDL在spark环境进行特征提取的流水线如Figure 1所示 :
♦ 使用Spark从分布式开源数据库中读入上亿张原始图片,构建成RDD
♦ 使用Spark预处理图片,包括调整大小,减去均值,将数据组成Batch
♦ 使用BigDL加载SSD模型,通过Spark对图片进行大规模、分布式的目标检测,得到一系列的检测坐标和对应的分数
♦ 保留分数最高的检测结果作为主题目标,并根据检测坐标对原始图片进行裁剪得到目标图片
♦ 对目标图片RDD进行预处理,包括调整大小,组成Batch
♦ 使用BigDL加载DeepBit模型,通过Spark对检测到的目标图片进行分布式特征提取,得到对应的特征
♦ 将检测结果(提取的目标特征RDD)存储在HDFS上
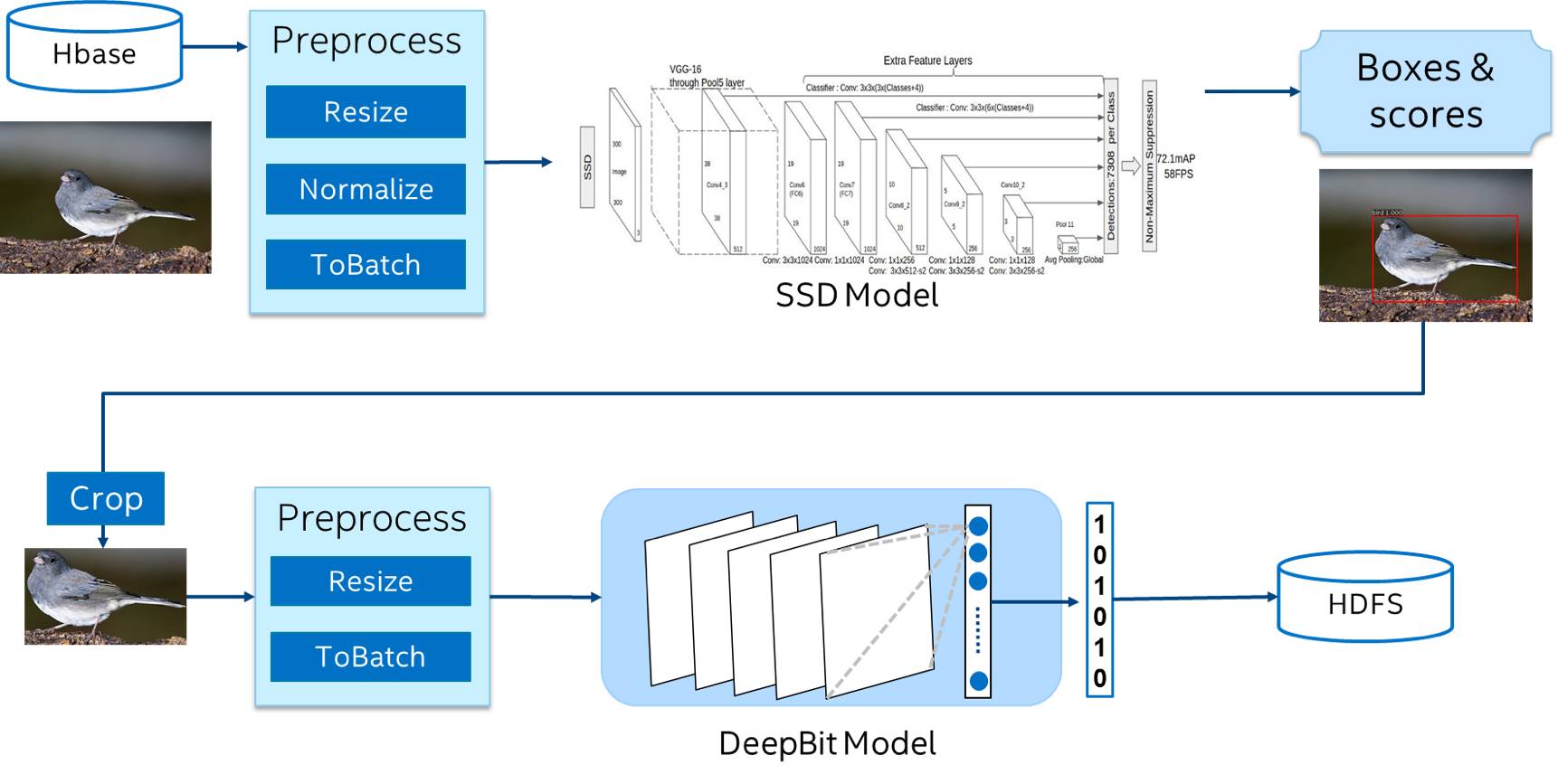
Figure 1 Image FeatureExtraction Pipeline Based on BigDL
整个数据分析流水线,包括数据读取,数据分区,预处理,预测和结果的存储,都能很方便地通过BigDL在Spark中实现。在现有的大数据集群(Hadoop/Spark)上,用户不需要修改任何集群配置,即可使用BigDL运行深度学习应用。并且,BigDL利用Spark平台的高扩展性,可以很容易地扩展到大量的节点和任务上,因此极大地加快数据分析流程。
除了分布式深度学习的支持,BigDL也提供了很多易用的工具,如图片预处理库,模型加载工具(包括加载第三方深度学习框架的模型)等,更方便用户搭建整个流水线。
图片预处理
BigDL提供了基于OpenCV[5]的图像预处理库[4], 支持各种常见的图像转换和图像增强的功能,用户可以很容易地使用这些基本功能搭建图像预处理的流水线。此外,用户也可以调用该库所提供的OpenCV操作自定义图像转换的功能。

这个样例的预处理流水线将一个原始RDD通过一系列的转换,转成一个Batch的RDD。其中,ByteToMat把Byte图片转换成OpenCV的Mat存储格式,Resize将图片的调整为300x300的大小,MatToFloats将Mat里的像素存成Float数组的格式,并减去对应通道的均值。最后,RoiImageToBatch把数据组成Batch,作为模型的输入,用于预测或训练。
加载模型
用户可以方便地使用BigDL加载预训练好的模型,在Spark程序中直接使用。给定BigDL模型文件,即可调用Module.load得到模型。
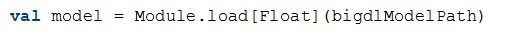
另外,BigDL也支持第三方深度学习框架模型的导入,如Caffe,Torch,TensorFlow。

用户可以很方便地加载已经训练好的模型,用于数据预测,特征提取,模型微调等。以Caffe为例,Caffe的模型由两个文件组成,模型prototxt定义文件和模型参数文件。如下所示,用户可以很容易地将预训练好的Caffe模型加载到Spark和BigDL程序中。
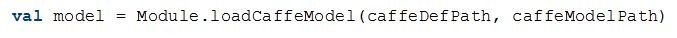
性能
我们对基于Caffe的GPU集群解决方案和基于BigDL的Xeon集群解决方案进行了性能基准测试,测试均运行在京东的内部集群环境里。
测试标准
端到端的图片处理和分析流水线,包括:
♦ 从分布式的开源数据库中读取图片(从图片源下载图片到内存)
♦ 输入到目标检测模型和特征提取模型进行特征抽取
♦ 将结果(图片路径和特征)保存到文件系统
注:下载因素成为端到端总体吞吐率的重要影响因素,在这个案例里面,这部分耗时占处理总耗时(下载+检测+特征)约一半。GPU服务器对下载这部分的处理是无法利用GPU加速的。
测试环境
GPU: NVIDIA Tesla K40,20张卡并发执行
CPU: Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz,共1200个逻辑核 (每台服务器有24个物理核,启用超线程,配置成YARN的50个逻辑核)
测试结果
Figure 2显示了Caffe在20个K40并发处理图片的吞吐量约为540图片/秒,而BigDL在1200个逻辑核的YARN(Xeon)集群上对应的吞吐量约为2070图片/秒。BigDL在Xeon集群上吞吐量上约是GPU集群的3.83倍,极大地缩短了大规模图片的处理时间。
测试结果表明,BigDL在大规模图片特征提取应用中提供了更好的支持。BigDL的高扩展性,高性能和易用性,帮助京东更轻松地应对海量,爆炸式增长的图片规模。基于这样的测试结果,京东正在将基于GPU集群的Caffe图片特征提取实现,升级为基于Xeon集群的BigDL方案部署到Spark集群生产环境中。

Figure 2比较 K40和Xeon在图片特征提取流水线的吞吐量
结论
BigDL的高扩展性,高性能和易用性,帮助京东更容易地使用深度学习技术处理海量图片。京东会继续将BigDL应用到更广泛的深度学习应用中,如分布式模型训练等。
引用
[1]. Liu, Wei, et al. "SSD: Single Shot Multibox Detector." European conference on computer vision. Springer, Cham, 2016.
[2]. Lin, Kevin, et al. "Learning compact binary descriptors with unsupervised deep neural networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
[3]. https://github.com/intel-analytics/BigDL
[4]. https://github.com/intel-analytics/analytics-zoo/tree/master/transform/vision
[5]. http://opencv.org/






