承上启下:基于全域漏斗分析的主搜深度统一粗排

一、背景
1.1 概述

1.2 模型基础结构
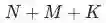 的列表,即样本维度为
的列表,即样本维度为
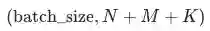 ,其中
,其中
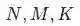 分别表示曝光样本、未曝光样本和随机负样本对应的长度。去年只是通过推测和分析进行的这部分样本构造工作,在今年提出和发现全域成交指标后,对此部分工作进行了回测,发现未曝光样本和随机负样本这两部分负样本的扩充共带来约5.5 pt的场景外的hitrate的提升。
分别表示曝光样本、未曝光样本和随机负样本对应的长度。去年只是通过推测和分析进行的这部分样本构造工作,在今年提出和发现全域成交指标后,对此部分工作进行了回测,发现未曝光样本和随机负样本这两部分负样本的扩充共带来约5.5 pt的场景外的hitrate的提升。

二、全域漏斗空间分析(新指标的初步检验)
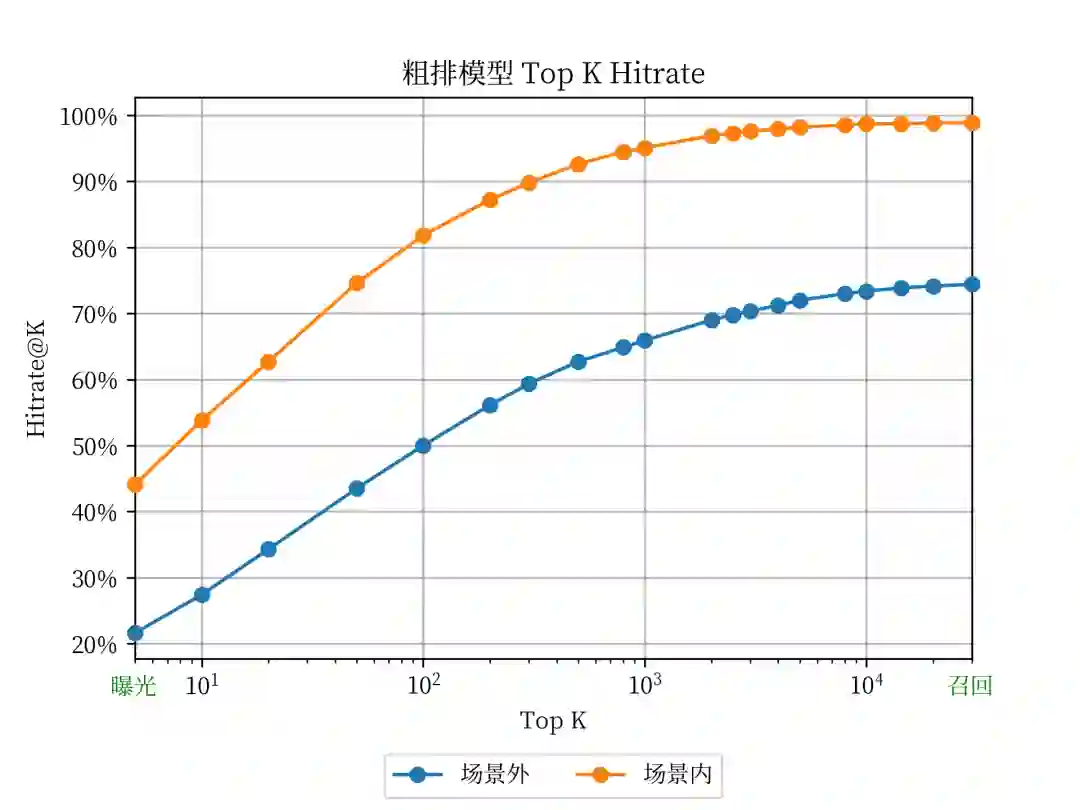
三、粗排离线衡量指标分析与修正
3.1 启下:衡量粗排->精排损失
3.2 承上:衡量召回->粗排损失
3.3 离线hitrate提升幅度与线上A/B test中hitrate提升幅度的一致性分析

四、优化方法
4.1 减少粗排-精排损失
4.1.1 蒸馏样本的进一步扩充
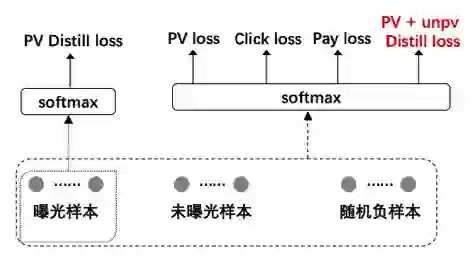
 蒸馏作为例子,pctr = pctr * 1 =P(海选->点击) 即可以表征其从海选到点击的概率,但是对于未曝光商品其后验P(海选->曝光)=0,从数学角度来说 pctr 没办法乘0或者直接表征海选到点击的概率。对于以上两个问题,我们发现由于曝光集合是在top10,未曝光采样集合在10-5000随机,通常显著小于曝光商品打分,(i)中存在的问题可以忽略。对于问题(ii)其中一种解决方式是使用label smoothing方法使用 pctr * scale代替 pctr *0的表征使其保留梯度,其中scale << 1。
蒸馏作为例子,pctr = pctr * 1 =P(海选->点击) 即可以表征其从海选到点击的概率,但是对于未曝光商品其后验P(海选->曝光)=0,从数学角度来说 pctr 没办法乘0或者直接表征海选到点击的概率。对于以上两个问题,我们发现由于曝光集合是在top10,未曝光采样集合在10-5000随机,通常显著小于曝光商品打分,(i)中存在的问题可以忽略。对于问题(ii)其中一种解决方式是使用label smoothing方法使用 pctr * scale代替 pctr *0的表征使其保留梯度,其中scale << 1。
4.1.2 进一步对齐粗排精排特征
4.1.3 交叉特征的引入
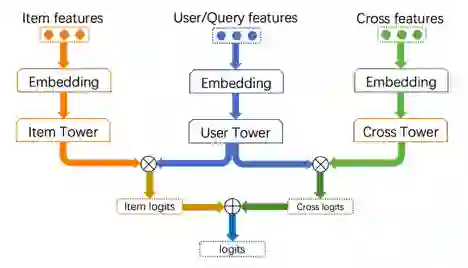
4.1.4 从内积到MLP的尝试
4.2 减少召回-粗排损失
4.2.1 全域样本
4.2.2 采样方式的优化

上述分析表明,相较于头部高曝光商品,模型对低曝光的长尾商品的打分的准确度都明显较差,这提示我们在这部分商品上,模型还有很大的优化空间,同时我们还统计了此部分商品在总体成交中占比也很高,因优化低曝光商品也能对整体成交进行提升。

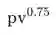 ,其中
,其中
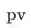 表示对应商品历史的曝光次数。调整采样方式后,长尾商品的占比有了明显变化:
表示对应商品历史的曝光次数。调整采样方式后,长尾商品的占比有了明显变化:


4.3 其他优化工作
4.3.1 损失函数的形式优化
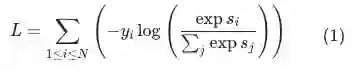
 表示item侧和user侧向量的内积,即similarity;
表示item侧和user侧向量的内积,即similarity;
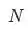 表示list的长度。
不同于其他场景下的任务,粗排模型的三个任务,尤其是曝光任务,在每个list中,
正样本的数量都可能不为1
(尤其是曝光任务,正样本的数量通常为10)。
我们发现,在粗排的场景下,直接套用softmax在多正样本的情况下的优化目标具有不合理之处,并据此对该损失函数进行了改进,使之更加适合粗排模型的优化目标。
表示list的长度。
不同于其他场景下的任务,粗排模型的三个任务,尤其是曝光任务,在每个list中,
正样本的数量都可能不为1
(尤其是曝光任务,正样本的数量通常为10)。
我们发现,在粗排的场景下,直接套用softmax在多正样本的情况下的优化目标具有不合理之处,并据此对该损失函数进行了改进,使之更加适合粗排模型的优化目标。

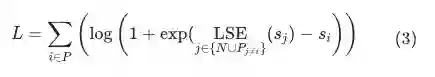

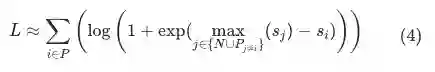
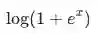 (也称为
SmoothReLU[3]
函数)近似为ReLU:
(也称为
SmoothReLU[3]
函数)近似为ReLU:

 ,上述损失函数都在试图拉大正样本
,上述损失函数都在试图拉大正样本
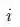 与当前list中所有其他样本上界之间的距离,这里的“其他样本”既包括全部的负样本,
也包括除样本
以外的其他正样本
。在绝大多数情况下,正样本的内积相似度大于负样本内积相似度,即
与当前list中所有其他样本上界之间的距离,这里的“其他样本”既包括全部的负样本,
也包括除样本
以外的其他正样本
。在绝大多数情况下,正样本的内积相似度大于负样本内积相似度,即
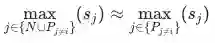 ,因此式(5)可以进一步写成:
,因此式(5)可以进一步写成:

 与除
与除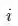 以外的全部正样本的上界之间的距离
,最终达到的效果是拉大正样本之间的距离,而忽视了真正重要的正样本和负样本之间的差异。
以外的全部正样本的上界之间的距离
,最终达到的效果是拉大正样本之间的距离,而忽视了真正重要的正样本和负样本之间的差异。
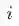 以外的正样本从
以外的正样本从
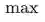 项中删除,
即计算当前样本与除以外的全部负样本的上界:
项中删除,
即计算当前样本与除以外的全部负样本的上界:
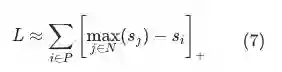 以外的其他所有正样本剔除即可:
以外的其他所有正样本剔除即可:
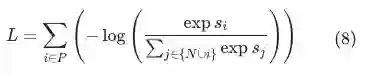
4.3.2 基于全域分析的精排打分量调整
五、总结与展望
[1]https://en.wikipedia.org/wiki/LogSumExp
[2]https://en.wikipedia.org/wiki/LogSumExp#Properties
[3]https://en.wikipedia.org/wiki/Rectifier_(neural_networks)#Softplus
职位描述
1. 设计和优化淘宝主搜排序下超大规模点击率、转化率精准预估任务,包括且不局限于特征样本loss设计、全域用户行为建模、大规模商品表达、端到端多模态排序等
2. 设计和优化淘宝主搜排序框架,设计合理的多阶段漏斗,设计合理的多维度排序因子融合机制
职位要求
1.计算机、数学或统计学相关专业硕士及以上学历;
2. 具备扎实的数据结构,算法和编码能力,精通至少一种编程语言,如C++、JAVA、Python等;
3. 机器学习基础扎实熟悉,持续跟进学术界及业界召回,排序,NLP等领域的算法模型,有大规模机器学习/个性化推荐/广告/信息检索/自然语言处理相关领域工作经验;
4. 有强烈的技术热情,有皮实乐观、不畏挫折的心态;具备优秀的分析和解决问题的能力;具备优秀的学习能力和团队合作精神;
5. 有国际顶会论文者优先;
联系方式 oudan.od@alibaba-inc.com
登录查看更多
相关内容

专知会员服务
31+阅读 · 2020年5月20日
Arxiv
18+阅读 · 2022年11月7日

相关VIP内容
专知会员服务
31+阅读 · 2020年5月20日
相关资讯