双塔召回模型的前世今生(上篇)
最近水群的时候发现很多人在纠结像双塔归一化和temperature、采样方式等问题,与sar的小伙伴也深入探讨了一些相关细节,断断续续看了一些论文,决定趁着下雪在家没事干把一些相关文献整理整理。
【上篇】尽量以一个面向初学者的视角阐述双塔召回模型的前世今生,包括为何双塔能够在海量候选低延时召回topK,归一化和温度系数的起因经过结果,以及负采样的一些研究。【下篇】会介绍双塔的局限性,以及在双塔大框架下学术界和工业界的优化路线,如果感兴趣可以关注作者的后续更新~
一些历史相关文章如下,知乎昵称【iwtbs】,转载合作 or 同行交流请加微信:937927101
01
—
双塔的诞生
首先来看一下经典的精排模型DIN(Deep Interest Network for Click-Through Rate Prediction),通过user历史行为序列和目标item依次算权重得到用户的兴趣表征,并和user、item、context等特征拼接过DNN计算loss。
这种复杂的精排模型在线上serving时需同时输入user+item特征得到最终的预估值,速度很慢,一般只能支持百、千级别的候选。
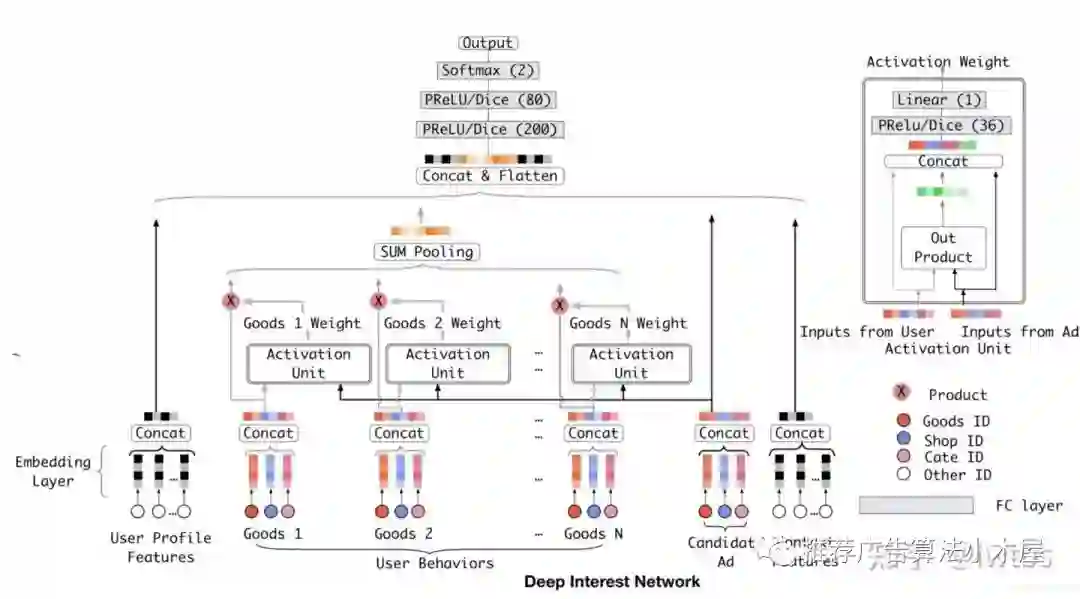
可是召回的候选巨大,像淘宝、抖音等场景召回候选量级是千万乃至亿级别,上述模型显然是难以招架,需要牺牲精度换取延迟,最简单的想法便是:不要线上对所有候选均过图预估一遍,最好能将一部分结果离线提前算好
于是双塔模型闪亮登场,结构非常简单,但是却能对海量候选进行召回
user和item特征分别单独输入DNN,得到user embedding与item embedding
将最后一层embedding计算cosine(下文会详细介绍为什么要用余弦距离)得到logit
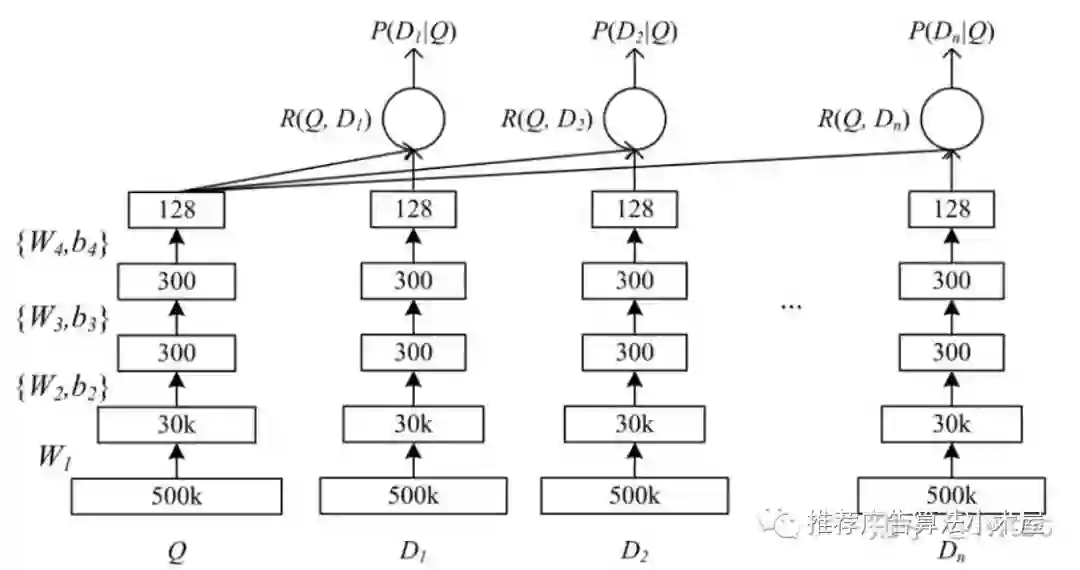
logit代表user&item之间的匹配程度,比较经典的双塔DSSM(Deep Structured Semantic Models)结构如下,这里的query便是推荐场景的user
那么可能有人会疑惑:双塔模型也是神经网络啊,为什么速度就会快很多呢?
02
—
离线构图+近邻检索=海量候选实时召回
精排模型之所以慢,是因为对于所有的候选item都要实时过图;而双塔之所以快,当然不只是因为模型结构简单了,而是因为中间结果可以离线提前算好,并且通过高效的检索实现精度和效率的平衡。
首先我们先理清楚一件事:
item侧的embedding需要实时算吗?
每个用户访问,都需要对item算一次embedding吗?
答案是不需要。因为在双塔结构下,无论对于userA还是userB而言,面对的item embedding都不会有区别,所以可以离线对所有的物料提前过item tower得到item embedding,当userA来时,只需要计算userA embedding即可,由此双塔的第一个好处便浮出水面:无需每次请求重复计算,节省了一大批算力资源
可是user embedding还是需要实时算,并且需要依次和存好的item embedding计算相似度,时间上真的能省很多吗?
当然还不够,这时候就引出ANN(Approximate Nearest Neighbor Search)了,其目的是将相似度关系提前构建索引图,线上只需要对构建好的图进行检索便可以快速找到topk,当然精度肯定比不上遍历+排序,但是效果已经很不错。去年我写过一篇文章简述常见的近邻检索算法有哪些,感兴趣的同学可以看看向量召回—近邻快速查找算法总结,具体在工作中需要结合候选大小、精度要求选择合适的算法,这里仅简单介绍HNSW(和下文要讲的cosine息息相关)
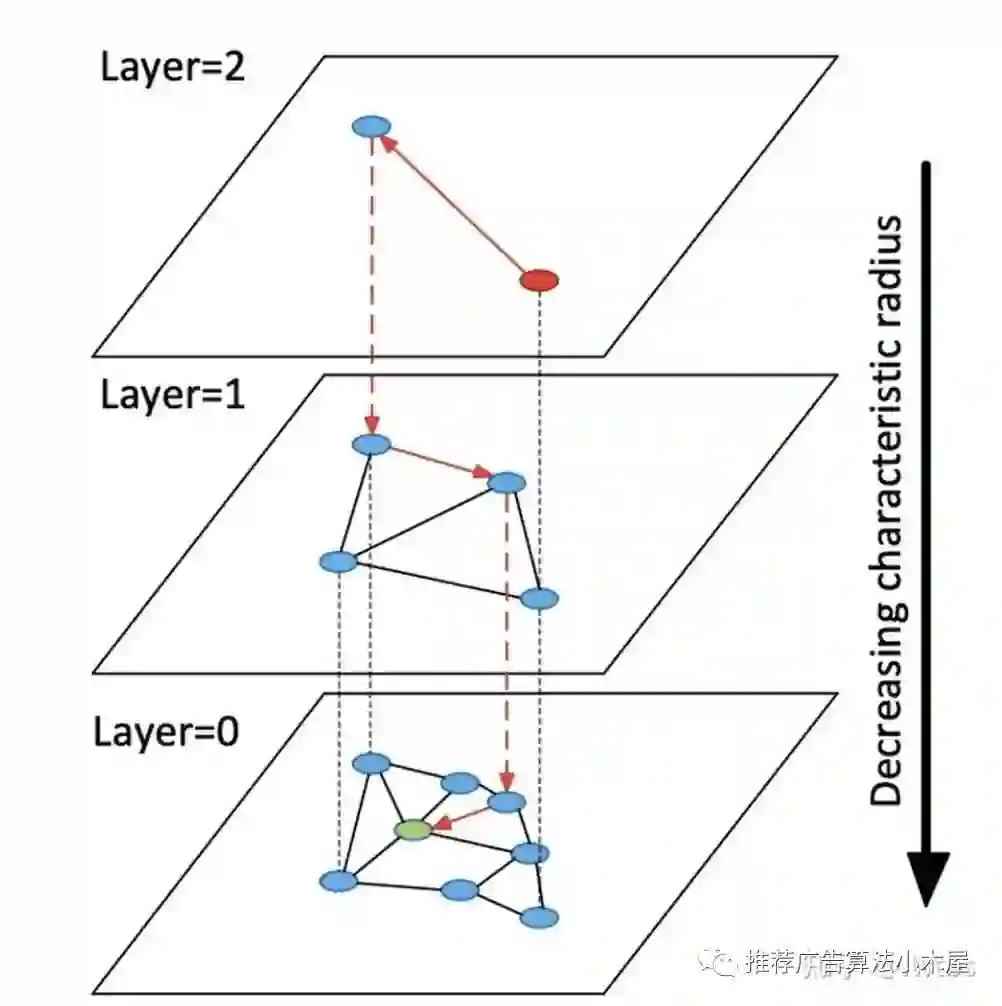
在HNSW中,引入Layers的概念,总体思想如下:
在Layer = 0 层中,包含了连通图中所有的点。
随着层数的增加,每一层的点数逐渐减少并且遵循指数衰减定律
图节点的最大层数,由随机指数概率衰减函数决定。
从某个点所在的最高层往下的所有层中均存在该节点。
在对HNSW进行查询的时候,从最高层开始检索。
凭借离线构建+ANN,我们终于能够在面对千万上亿的候选时,快速的召回topK
03
—
永远被问的cosine
这里的“永远被问“,是因为我几乎每周都会在技术群看到有人问:
为什么双塔要用cos距离
双塔最上层为什么要归一化
归一化后为什么要乘温度系数
虽然我之前在借Youtube论文,谈谈双塔模型的八大精髓问题2.6节介绍过原因(归一化后不乘系数压根就收敛不了),但是对于其原理脉络没有详细的介绍。希望这次能够阐述清楚,以后大家再遇到有人问直接甩本文链接即可
让我们重新回顾一下问题。Youtube双塔召回《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》提到
双塔最上层进行归一化能提高最终召回效果
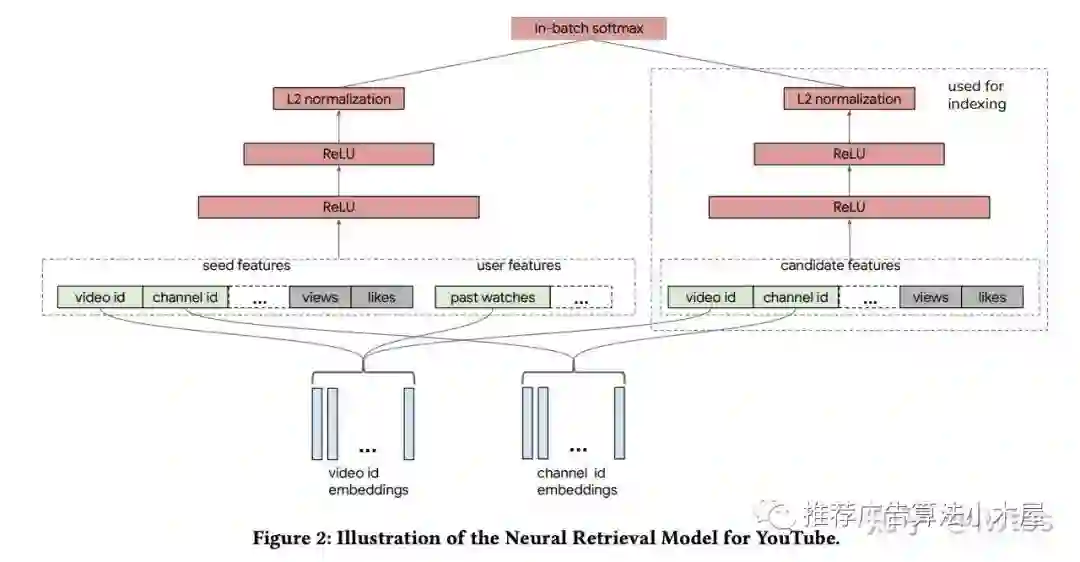
而且归一化需要与temperature配套使用

那原因究竟是什么呢?还记得上文我们提到了HNSW算法对吧,在hnswlib项目(github.com/nmslib/hnswl)中可以看到HNSW 算法在点乘距离的数据集上效果差

本质是因为点乘距离非度量空间,不满足三角不等式 ,距离比较没有传递性。更通俗的说内积不保序,假设有三个点ABC,点击意义下|A,B|<|A,C|,但是欧式距离下不一定有|A,B|<|A,C|,比如A=(100,0),B=(0,100),C=(101,0)。
因此一般HNSW采用欧式距离构建检索图,而归一化则巧妙地将双塔点积行为转化为了欧式距离,证明如下(item模长是1)
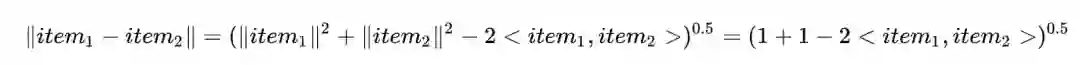
自此,归一化解释清楚:双塔召回需要ANN,点积不保序一般使用欧式距离,双塔最上层归一化能将输入映射到欧式空间,保证了训练检索的一致性,提高了效果。
04
—
和归一化永不分离的temperature
下一个问题是temperature的来由和设置,我觉得这是一个很好的面试题,因为如果一个人做过双塔模型,又使用了归一化操作,他一定知道没有temperature模型几乎收敛不了(所以可以看出,真的很多人光说不做,但凡跑个模型都想清楚问题在哪了)
我们先画一下logit和交叉熵的关系,第一列为logit,第二列为交叉熵
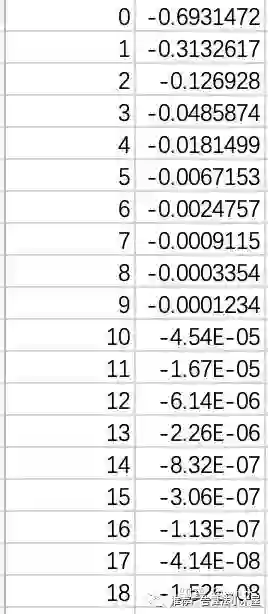
首先我们要认识到模型把正样本分对了,loss应该是极小值才对。而由于归一化点积值域必在[-1,1],导致模型预估点击概率为1时模型loss仍然很大,temperature的作用其实就是放大loss,让模型容易学习。
有一句话:做召回的同学,要多follow人脸的paper
最近有很多人开始将对比学习和推荐相结合,而度量学习、孪生网络可以说早就称为人脸的基操,事实上关于temperature的作用和大小在《Heated-Up Softmax Embedding》中有详细的分析。下图展示了数字识别任务的分类可视化结果和温度系数的关系
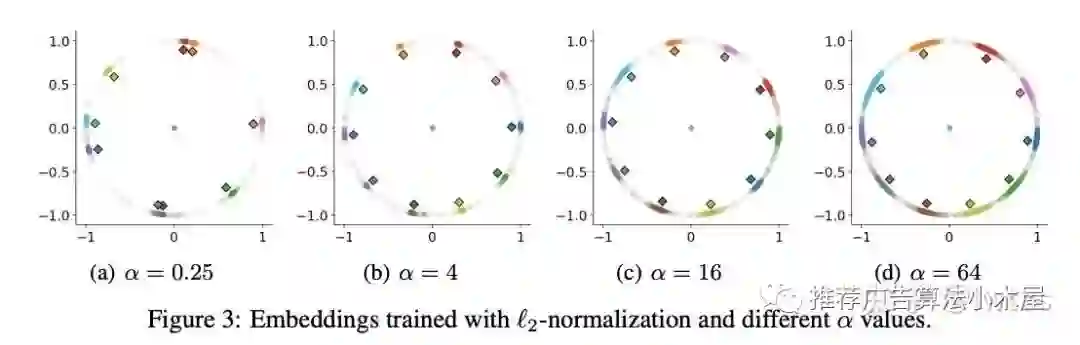
用我的话来解释,对于动物而言猫、狗就是centroid,而布偶、短毛、折耳猫就是boundary
大倍数时,centroid几乎无梯度,boundary样本学习较好
小倍数时,centroid学得好
那么为了更好的trade-off,则应该选择intermediate temperature(图b)
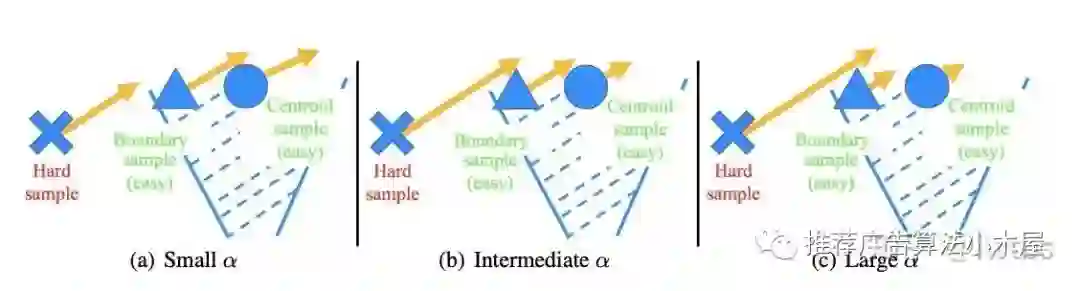
本文顺势提出了一种巧妙的heated-up方法,先用大倍数把难样本学好,等难样本成为简单样本后,再用小倍数fine-ture把决策面学好,使同类样本分布更集中
05
—
负样本的艺术
与排序不同,召回负样本不能只用真实点展样本,需要采样。早期我也写过一篇文章说明,为什么召回需要进行负采样&有哪些采样方法召回模型中的负样本构造,这里做个补充
负采样有什么难的,搞个列表然后random不就好了?
事实上在工业界这么搞有问题:在类似dssm这种双塔模型中,item侧特征除了itemid外,还有其他meta特征,此时负样本对itemid做负采样后,还需要取相应负样本的meta特征。物料库比较大的时候,需要维护一个比较大的物料池,同时在tf训练数据中并不方便建立itemid与各类meta特征的映射表,特征join太费资源。
因此以batch采样为主线有了以下常用手段:
in-batch采样
取一个batch内其他用户的正样本做为本用户的负样本,以解决负采样meta特征问题。同batch其他user正样本,某种程度上表述自己对这部分样本的敏感性不如其他user,可以认为是一定程度的hard负例。但是直接使用in-batch负采样,需要较大的batch size,如果size太小则采样效果很差,而如果batch size太大存储资源就会承受不住,因此负样本的多少会受到资源的限制
in-batch采样+bias校正
batch softmax有一个问题在于,为了达到最好的效果理应batch内的数据分布与真实分布一致,而这在流训练架构下并不容易实现。同时把batch中除了这个item外的所有item作为负样本,会导致热门物品被当成负样本的概率也很大,会造成对热门商品的惩罚过高,经验证item频率会严重影响双塔模型精度,所以需要纠偏机制。
借Youtube论文,谈谈双塔模型的八大精髓问题这篇论文中引入频率修正,提出了流式训练中预估item的频率的方法,细节可以看上述博客。
混合采样
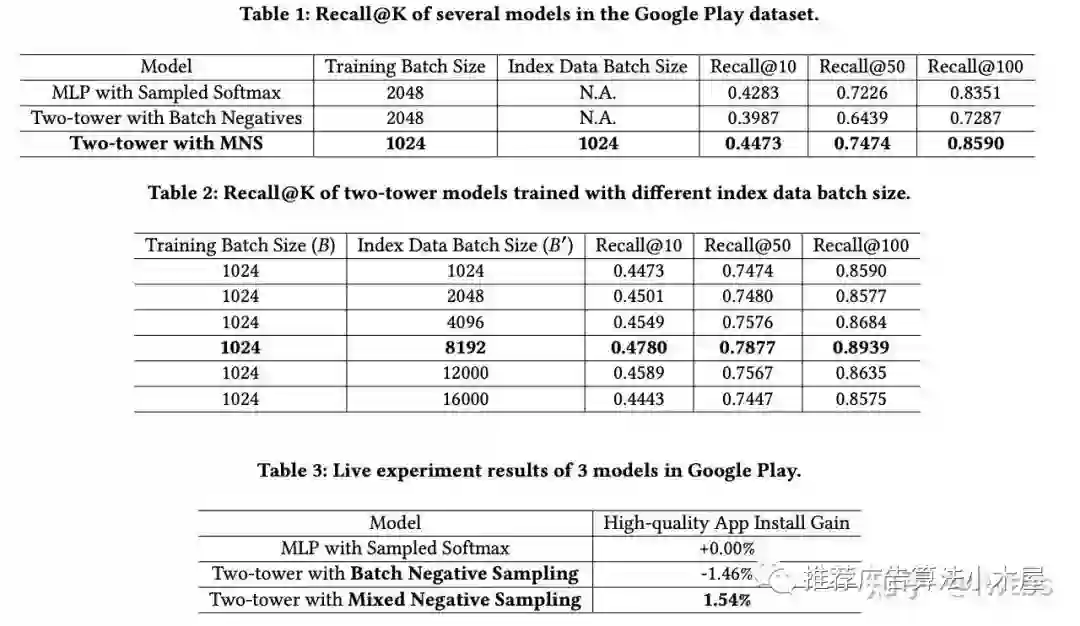
谷歌的论文《Mixed Negative Sampling for Learning Two-tower Neural Networks in Recommendations》提出了混合负采样:batch内负采样+物料池中全局均匀采样,batch内负采样贴合物品出现频率的采样,节省了计算资源但是存在偏差问题,负样本不包含长尾中item;因此引入了物料池中均匀采样,一方面解决冷启动问题,一方面引入全局分布避免batch size太小导致的分布剧变。
其实这篇论文没什么理论,更像一个实验报告,测试了不同的training batch size和index data batch size给出了一个不错的组合方式
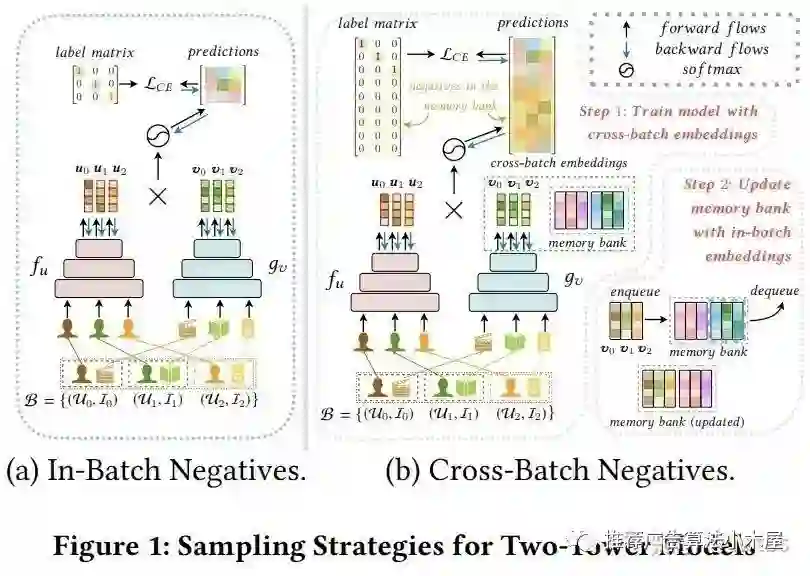
Cross Batch Negative Sampling
这里不得不提华为的《Cross-Batch Negative Sampling for Training Two-Tower Recommenders》,虽然下面图画的好看,名字CBNS也起的牛逼,但看完后只想吐槽:这不就是维护了一个队列吗。
业务向的hard mining
本质都是提高模型的训练难度,让模型感受世界的参差,不能只识别出来我不喜欢看美妆美食 喜欢看篮球,还要能识别出来我喜欢看湖人队还是篮网队,其中前者就是随机负采样干的事情,而后者就主要靠hard mining提供了,比如分商品类目、视频频道、同城等。
在Airbnb《Real-time Personalization using Embeddings for Search Ranking at Airbnb》一文中作者提出:
增加“与正样本同城的房间”作为负样本,增强了正负样本在地域上的相似性;
增加“被房主拒绝”作为负样本,增强了正负样本在“匹配用户兴趣爱好”上的相似性
以及《Embedding-based Retrieval in Facebook Search》论文精读提出了online和offline两种mining方式
online:在线一般是batch内其他用户的正例当作负例池随机采,本文提到选相似度最高的作为hard样本,同时强调了最多不能超过两个hard样本。
offline:在线batch内池子太小了不一定能选出来很好的hard样本,离线则可以从全量候选里选。具体做法是对每个query的top-k结果利用hard selection strategy找到hard样本加入训练,然后重复整个过程。这里提到要从101-500中采,太靠前的也许根本不是hard负例,压根就是个正例。以及两个很好的经验,第一个是样本easy:hard=100:1,第二个是先训练easy再训练hard效果<先hard后easy

