MOBIUS:百度凤巢新一代广告召回系统


文章作者:被包养的程序猿丶
内容来源:浅梦的学习笔记
01
创新点
1. 在召回层保证相关性的同时引入了CPM等业务指标作为召回的依据。
2. 将以往的CTR预估模型融合到召回层中,提出一种全新的多目标商业召回系统架构。
02
论文背景
在大部分公司的商业广告系统架构中,都会采用经典的“漏斗”结构,即召回——粗排——精排——重排序等模块,在现有的召回模块中,应该首先保证召回内容的相关性,保证用户的搜索query和候选广告之间的匹配程度,最为基础的召回链路就是要保证召回层的相关性,但是相关性高的广告并不一定具有很高的商业价值,所以开始尝试将一些商业化业务指标作为召回的依据,比如CPM ( 可以理解为变现能力 )。但是如果单纯的依靠CPM来进行召回的话又无法保证召回的准确性,会出现大量的badcase,即“所答非所问”,这种情况对于用户的体验来说是非常不友好的,所以召回层基本都是在保证相关性的大前提下尽量的筛选出一些变现能力较强的候选广告进入排序阶段。
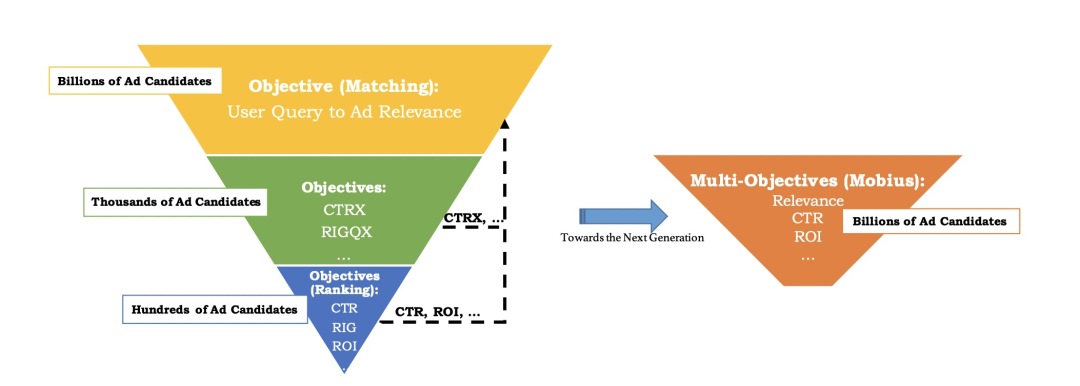
那么如何能够保证尽量筛选出变现能力比较强的广告呢,一般CPM=PCTR广告主出价*1000,假设广告主出价不变的情况下,我们可以认为PCTR越高的广告他的变现能力是越强的。所以一个很直观的方法就是在召回阶段利用CTR模型来对候选广告进行预测得到其PCTR值,从而作为召回的依据,而凤巢最新一代召回系统的核心思想就是上述提到的将CTR模型迁移到召回阶段。当然这其中需要解决很多的问题,不是直接套用CTR模型就可以的。所以接下来将会介绍凤巢是如何将CTR模型迁移到召回层的。
03
系统架构
整个“莫比乌斯”召回系统架构如下图所示:
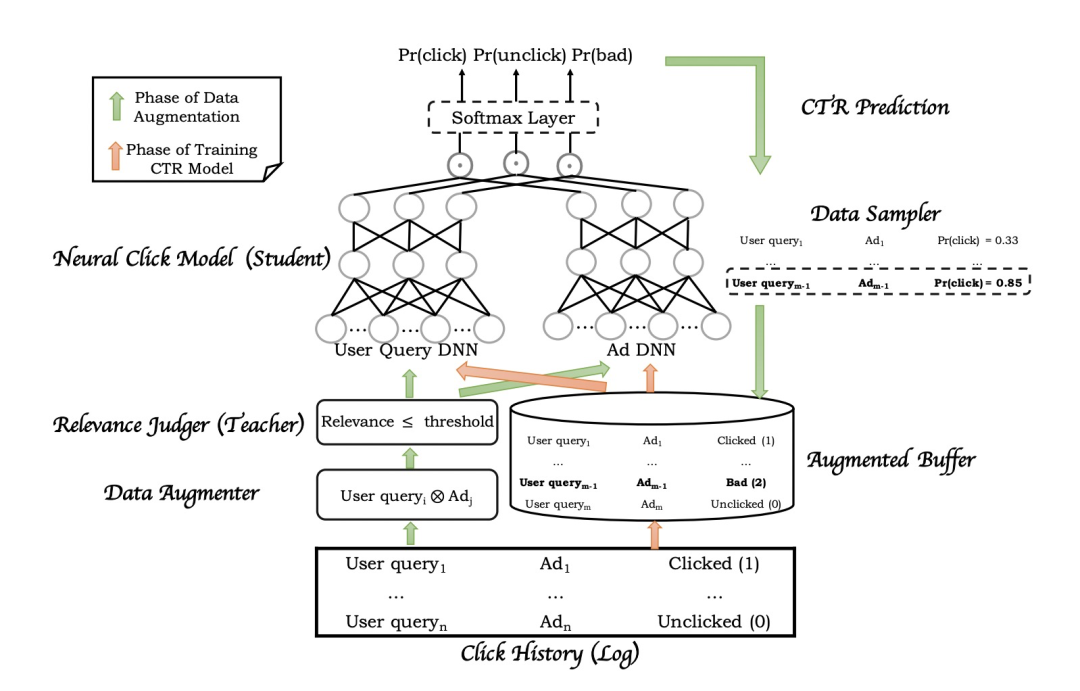
训练流程如下图:

整个系统其实分为两个核心的模块:数据增强模块、模型训练模块。论文中对整个系统的介绍还是比较清晰的,数据增强模块主要是用户生成模型所需的训练样本,生成的训练样本需要能够针对“低相关性高点击率”的badcase有所区分;模型训练模块主要就是介绍模型是如何利用生成的样本数据进行迭代更新的。
1. 数据增强模块
在传统的CTR模型中,模型只需要根据用户的搜索query为其找到最有可能点击的广告即可,所以可能出现序非常靠前的广告和搜索qeury的相关性不高的badcase,同时CTR模型训练所需的日志数据相对于召回层需要处理的数据量级是非常有限的,而且召回层可能需要面对更多的长尾稀疏的query和广告,所以为了解决上述的一系列问题,文章提出了一种基于active- learning的“teacher-student”模型训练框架。
从上面的训练流程图可以大致归结为如下几步:
(1)首先从点击日志中加载一个batch的数据
(2)利用这一个batch的数据构建两个集合,即query集合和广告集合
(3)对构建好的query集合和广告集合两两配对,构建augmented data,即query集合大小为N,广告集合大小为M,则生成的样本集合大小为N*M
(4)利用传统的召回阶段的相关性模型对每一个query-ad的pair进行相关性打分,筛选出其中相关性比较低的的pair
(5)利用CTR预估模型 ( T-2 ) 对相关性较低的pair进行CTR预估得到pctr
(6)利用采样器根据PCTR值对这批低相关性的pair进行采样,同时对这批数据打上对应的label——badcase,得到增强的样本数据
(7)将增强的样本数据补充到CTR模型的训练样本中,并且单独设计一个类别badcase,也就是将传统的CTR模型的二分类任务扩展到了三分类任务
其实整个流程在论文中描述的还是比较清晰的,值得注意的是召回阶段需要处理的数据相较于排序阶段来说是更大规模而且更加稀疏的,点击训练日志中中的数据是十分有限的,所以文章利用query集合和ad集合两两配对的方式来进一步丰富样本的规模以及对长尾流量的覆盖;同时为了解决直接利用CTR模型进行召回而引入badcase的问题 ( 低相关性高点击率 ),需要利用到相关性召回模型 ( teacher ) 来“教”会CTR模型 ( student ) 哪些样本是badcase,所以这里首先利用相关性模型对构造的query-ad pair进行相关性打分,并从中筛选出来相关性较低的样本交给CTR模型进行预测,根据预测的PCTR值从中选出低相关性高PCTR的样本作为badcase ( 这类样本在原始CTR样本中是不存在的,是为了让CTR模型学会哪些是badcase而构建出来的,原始的CTR模型是不需要关注相关性的,只需要关注CTR )。
2. 模型训练模块
整个模型的结构是比较经典的双塔模型,利用用户侧的特征构建用户queyr的embedding向量,利用广告侧的特征构建广告的embedding向量,文中提到每个embedding’向量的维度是96维,每一侧将96维的embedding分为三组vector,每组32维,分别对两侧的同一组vector计算inner product得到三个分数,然后经过softmax layer得到最终预测label ( click、unclick、badcase ),整个模型还是比较清晰易懂的。
04
线上广告召回
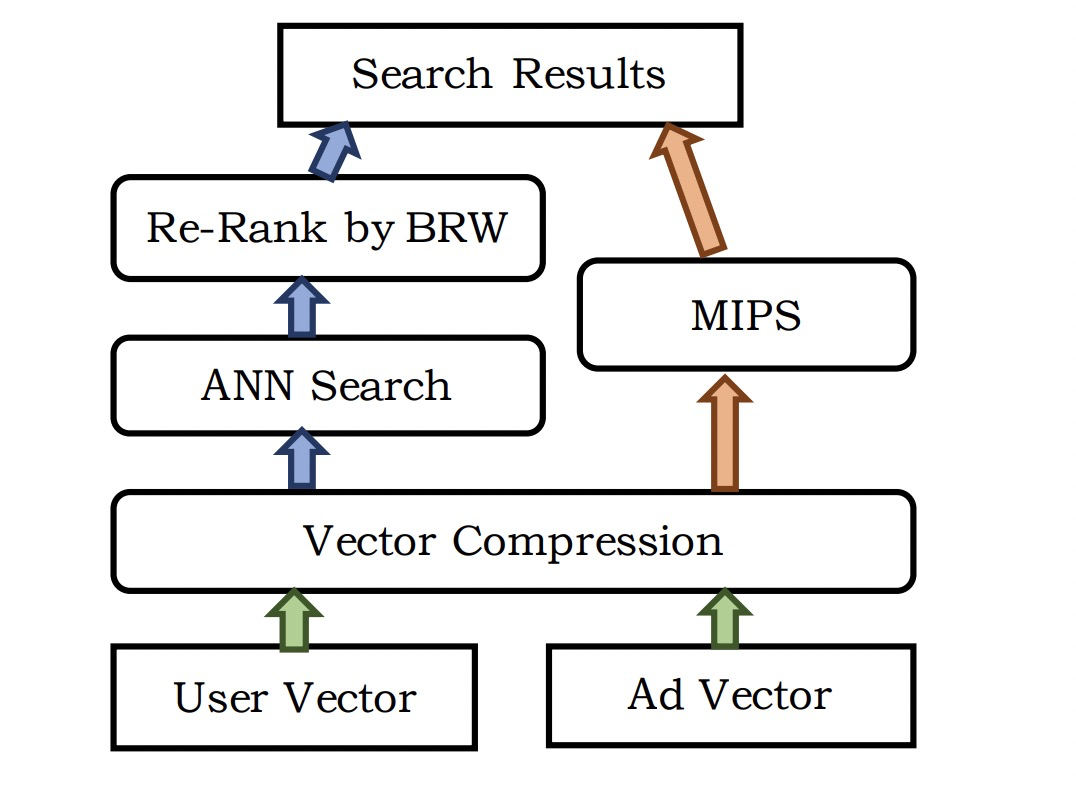
在线上进行广告检索召回的时候,当收到一个用户请求 ( query ) 时,线上计算可以得到用户的query embedding,利用query embedding需要在保证相关性的前提下筛选出变现能力最高的一批候选广告,这时就需要利用query embedding去进行检索,暴力的全库检索基本是不可实现的 ( 线上计算开销太大,根本无法满足耗时的要求 ),所以比较常用的是近似最近邻 ( ANN ) 检索 ( 开源库比较多,例如ANNOY,FAISS,HNSW等 ),ANN检索通常是根据余弦相似度来进行计算的,在ANN检索之后对检索的结果进行相应商业指标权重来进行重排序得到检索结果。除此之外文章还提到了最大内积检索 ( MIPS ),上述提到的检索方式是先检索再根据业务指标排序,MIPS则是将业务指标改写进了相似度计算的公式中,也就是在检索的过程中是考虑了商业指标的,具体计算公式如下:
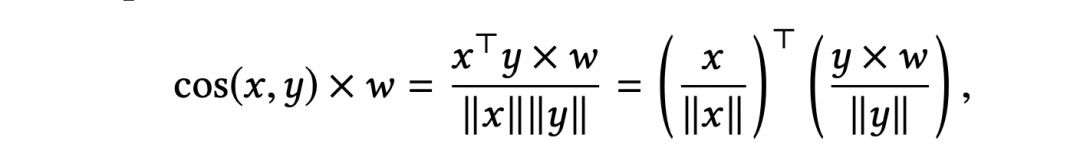
另外文章还提到考虑到磁盘以及内存的开销,文章对高维的浮点数embedding向量进行了压缩的处理。
05
实验效果
具体离线实验效果可以参考原文:
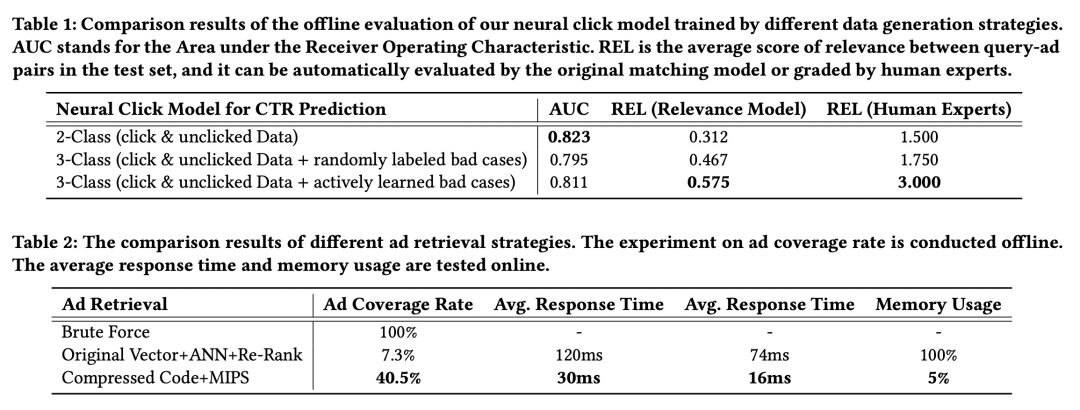
实验效果
目前“莫比乌斯”已经部署到PC端百度搜索以及移动端百度APP上,从线上一周的监控指标来看,CPM涨幅还是非常大的,可以说效果还是比较明显的。
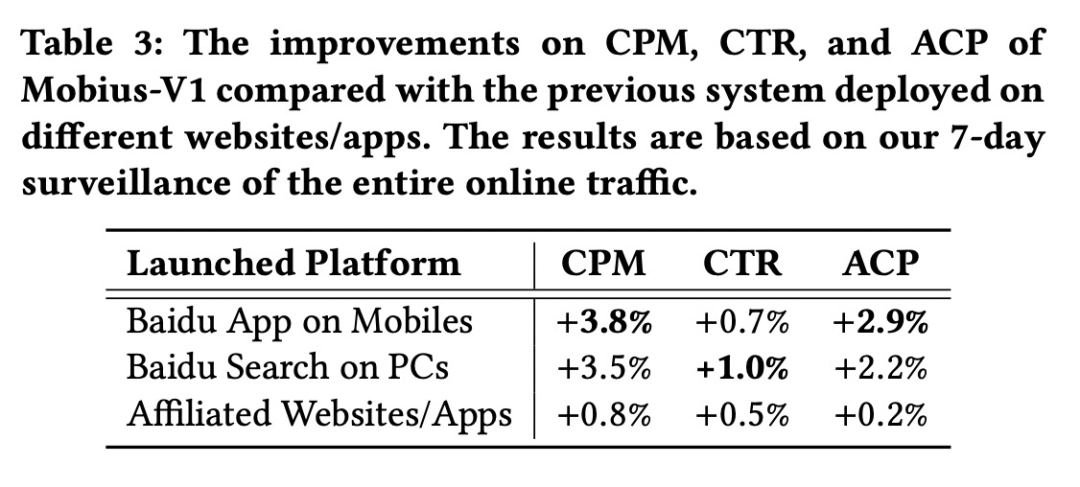
线上实验效果
06
结论
传统的广告召回都是需要首先保证相关性,但是这就牺牲了一部分的变现能力,毕竟广告平台是需要盈利的,而如果要在召回阶段尽可能的提升变现能力的话,就很有可能引入一些badcase,如何在保证相关性的大前提下,尽可能的提升候选广告的变现能力是非常有必要的。毕竟如果变现能力高的广告未出现在召回的结果中,就算排序阶段再怎么努力也不可能大幅提升平台的收入,因此召回的结果对后续的排序以及最终的收入影响是非常大的。凤巢提出的新一代召回系统线上的效果还是非常不错的,在保证相关性的前提下又在一定程度上提升了候选广告集的变现能力,给我们提供了一种新的思路。
原文链接:
https://zhuanlan.zhihu.com/p/146210155
参考资料:
MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search
作者介绍:
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:

文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇



