

分享嘉宾:袁镱博士 腾讯 专家研究员 编辑整理:尹学正 腾讯音乐 出品平台:DataFunTalk
**导读:**随着推荐技术的不断发展,推荐系统的应用变得更加广泛。相比CV/NLP场景,推荐场景的模型训练和线上预测需要更强的实时性。因为场景的多样性,推荐系统的优化目标也更为复杂多变。推荐业务用户量大、实时服务吞吐量高、优化目标多变等特点使得常用的高维模型的训练和预测存在许多挑战。本次分享主要针对腾讯无量深度学习系统在推荐类业务中的应用。 全文将围绕以下三个部分展开: * 无量的背景和面对的问题 * 无量的解决方案 * 无量系统的演进
01
无量的背景和面对的问题
在介绍无量系统前,首先来看一下AI计算框架的全流程和无量的关系,以及无量系统在实际应用当中需要解决的问题。
1. AI 全流程和无量的关系
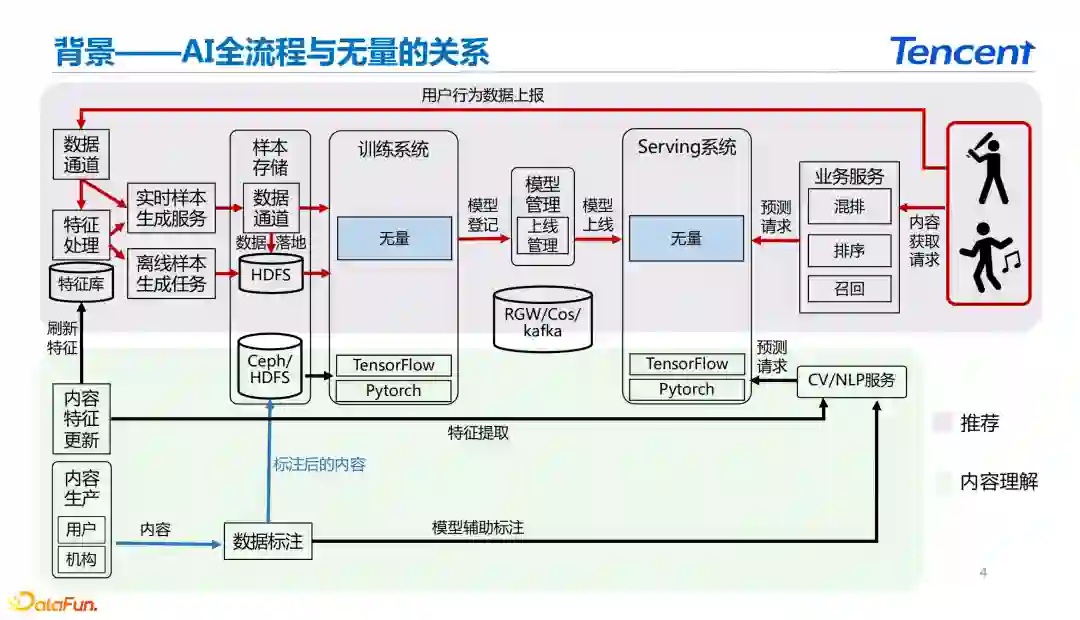
如上图所示我们可以将深度学习框架大致分为两种类型:一种是内容理解的应用场景,另外一种是推荐的应用场景。 推荐领域和传统内容理解面对的问题差异的如下: * 数据的实时性
从内容理解的应用场景来看,主要通过深度学习框架进行模型训练,然后完成模型上线得到内容的向量表示。在内容理解的大部分场景的最终产出主要是内容的特征和特征的embedding表示。 推荐的业务场景和内容理解的区别在于有用户的介入。在推荐场景中,用户作为系统的起点产生了实时的用户行为,经过数据上报、样本生成、训练建模、线上serving等过程,最终完成推荐结果的展示。整个数据闭环中因为用户实时行为的参与需要推荐系统具备更高的数据时效性。 * 建模目标的多变
由于用户的介入导致模型训练的学习目标是变化的。当用户使用场景和推荐上下文发生变化之后,推荐系统建模需要能够捕获到用户兴趣的变化。这是和传统内容理解场景下的深度学习框架比较大的区别。
2. 推荐业务的技术瓶颈

推荐系统的深度学习框架主要需要面临的技术瓶颈如下:
数据量大。推荐系统的用户量和物品量级都非常大,具备百亿级别的曝光,十亿级别的点击和亿级别的DAU。 * 具备很强的用户交互关系,整个系统的时效性要求更高。 * 需要完成千亿级别的模型在线训练和TB级别的模型上线。 * 需要完成高吞吐、低时延的在线服务。
02
无量的解决方案
1. 计算框架
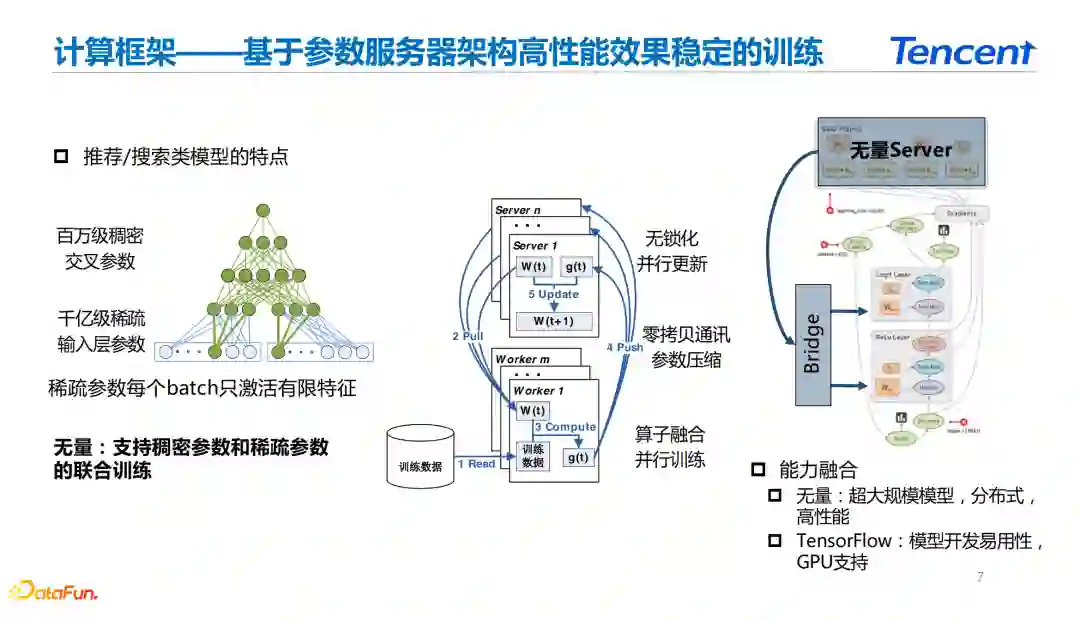
在介绍无量的整体计算框架之前,我们先了解一下推荐模型具备的特点。 * 推荐模型的特点
推荐场景下大型的TB级的模型的参数量主要取决于深度模型中的稀疏层。在模型训练和线上推理的过程中,稀疏层的特点是每次能够命中到的key并且激活的参数都是有限的。
我们以id类型的稀疏特征为例, 当batch大小为1024的时候,训练过程中每个batch所能命中的key最多为1024个。模型稀疏层实际大小可能有千亿级别的参数,和训练过程中真实使用的情况存在巨大的差异。系统在训练过程中使用key的时候可以按需获取,从而提高深度学习系统的性能。 * 参数服务器架构
基于推荐系统的模型特性,大部分推荐类型的深度学习框架都采用了参数服务器的架构。基于参数服务器架构的推荐框架能够比较方便地完成按需的参数获取和参数激活。 在模型训练过程中,可以只获取当前使用的参数计算梯度并推送回参数服务器做梯度更新,在参数服务器架构的基础上进行算子融合、并行训练。 在参数服务器架构中,由于参数服务器和训练worker的分离,使得深度学习系统可能存在通讯上的性能瓶颈。无量主要采用参数压缩、零拷贝通讯来减少通讯过程中的数据量。在server端, 无量主要做了一些无锁化和并行更新的优化。 * 无量系统的模型计算
在面对算法人员提供模型训练和建模能力时,无量系统主要是将参数服务器和TensorFlow的能力进行了融合。在server端对参数服务器参数获取和TensorFlow模型计算的能力进行桥接。在无量系统中比较完整地复用了TensorFlow的图构建以及自动求导能力,使得TensorFlow用户能够花费极小的学习成本掌握无量系统的使用。无量通过这种桥接方式能够完成高性能分布式模型训练和GPU部署能力的支持。
2. 推理服务
推理面临的问题
在推荐业务中训练得到的模型往往是TB级别的。在模型排序阶段,假设用户的单个请求item为300个。每个item特征需要的key为500个,那么对于线上推理而言,每次请求激活的key为15W个。在资讯类业务中线上1WQPS请求的情况下需要存储的key为15亿。同时推理服务还需要满足线上服务的实时响应(10ms以内的耗时)和模型的版本控制。 在推荐系统模型训练的参数访问中主要是key-value的模式。采用传统的分布式存储系统存在主备一致性问题,数据读写需要加锁,从而使得推理服务转化成CPU型的服务。对1WQPS的模型上线所需要的机器数量庞大,大概需要上千台机器,对业务方而言成本太高。
分布式serving服务
在模型训练过程中,主要的性能瓶颈在机器内存上,采用分布式训练主要是为了解决模型过大的问题。在推理服务阶段为了不增加CPU的占用,无量将性能的瓶颈控制在内存上,设计了一个分布式serving的服务采用多机多副本的并行读取来实现并发读取,通过多线程的无锁机制实现了模型版本的读写分离,通过L1缓存的查询优化来实现单机处理能力的提升。在提升单机处理能力的基础上,对高频热key进行缓存优化,将整个模型的推理服务改造成基于内存型服务。
3. 持续上线逻
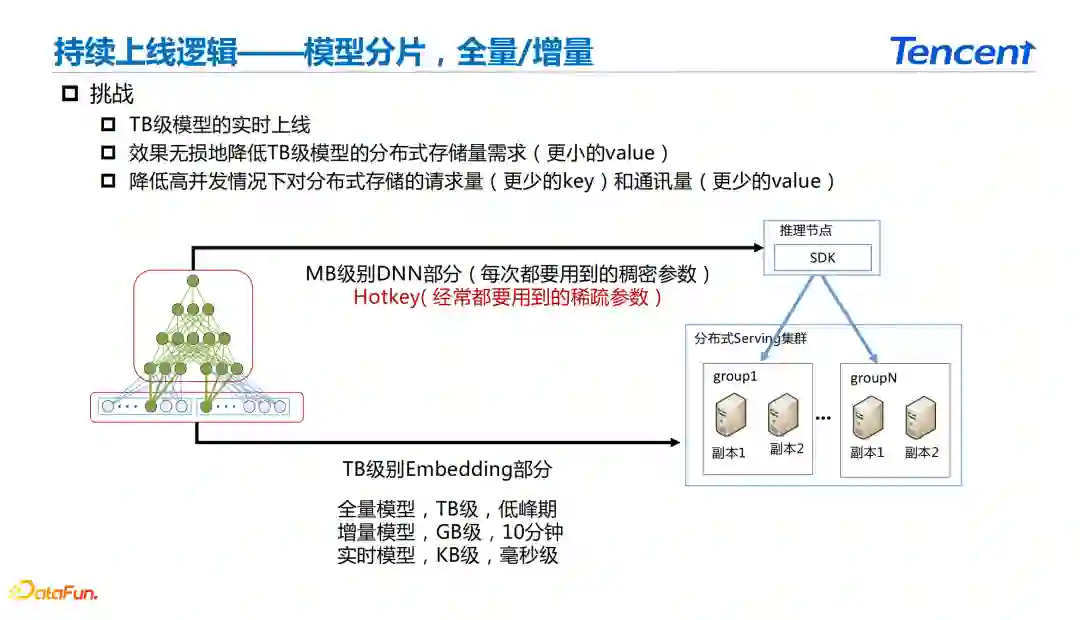
**在无量的深度学习框架中需要考虑从训练端到上线端完成实时的整体闭环。**主要考虑如何进行TB级别的模型实时上线,减少TB级模型的存储量并降低高并发的分布存储请求量。 无量在模型训练和上线过程中对模型进行切片,将DNN部分和Sparse Embedding部分分别上线到不同的节点上。在模型上线过程中,将DNN和特征里面的热key推送到推理节点上线,另外将模型整体的embedding推送到分布式Serving集群节点上。
在Serving集群节点embedding的更新主要采用三级的更新方式:
全量模型,TB级别的更新,用户根据业务情况设定在低峰值或者24小时更新。 增量模型,GB级别的更新,设置1小时或者是10分钟级别的更新。 实时模型,KB级别的更新,采用消息中间件实现毫秒级更新。
4. 模型压缩

在深度学习的训练过程中得到了TB级模型,但是在线上推理过程中不一定需要上线TB级别的模型。在传统CV、NLP领域里面常用的模型压缩方法包括:蒸馏、量化等。 传统的CV、NLP场景在模型训练后通常有重训和效果调试的过程。在推荐场景下由于推荐全链路的实时性要求,使得CV、NLP中的模型压缩方法无法在推荐中使用。 在推荐业务中模型的大小主要取决于稀疏层key-value的大小。在推荐系统的深度学习框架中主要采用的优化方式有两种:
① 使用更少的values
通过采用变长的embedding方式,对低频特征使用较少的value去表征,并且结合优化目标去控制value的长度,主要适用于有大量稀疏特征的情况下。 优点: 主要是与优化器无关
缺点:使用变长编码,影响推理端的性能优化。
② 使用更少的key
阿里的group lasso通过加入L21的正则项去除稀疏key减少数据量的存储。 优点: L1正则强度可控,在效果不影响的情况下可以将稀疏度控制到64%~94%;实现简单,只修改训练优化器。 缺点: 在FTRL才有稀疏效果,与原生Adam有AUC差距。
③ 使用更短的val****ues 混合精度
采用float16、int8、int4的压缩。 * 量化压缩
采用1bit或者2bit的压缩。 优点: 与优化器无关;可以与矩阵计算库适配加速。 缺点:二值/三值量化压缩需要量化训练,有效果验证成本。
03 无量的演进
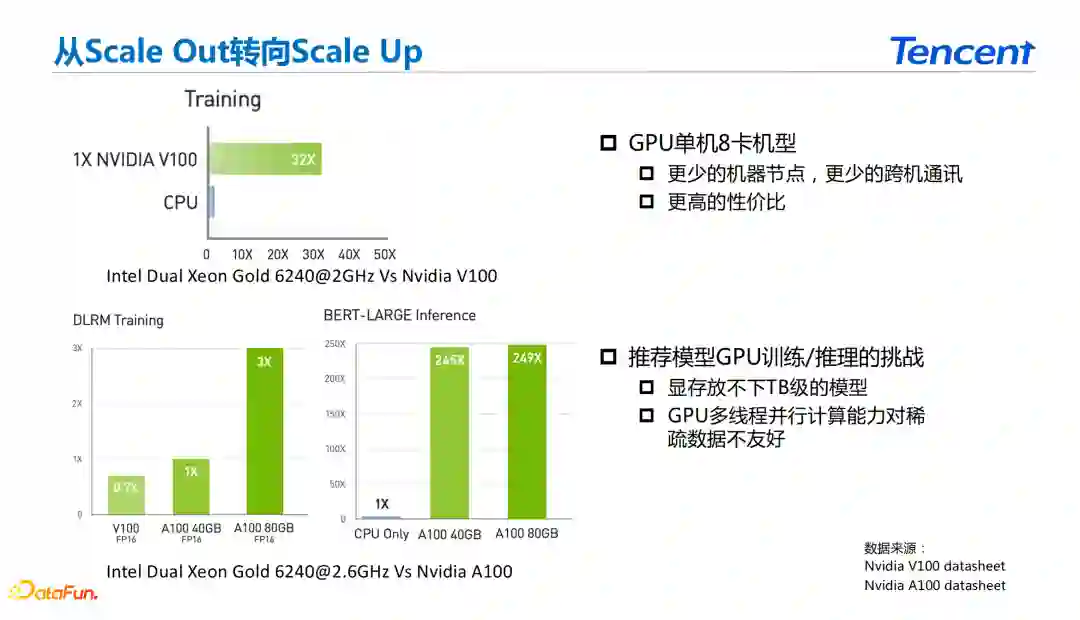
二值/三值量化压缩 在分布式训练的角度上讲对系统训练的加速主要分为两个方向: * Scale Out:使用更多的节点来加快训练速度。 * Scale Up:使得单机的训练速度更快来加快训练速度。
在使用GPU单机8卡机型的情况下,可以使用更少的节点。在分布式的深度学习系统中节点减少之后跨机的通讯会更少,同时减少了节点的异构问题,并且具备更高的性价比。在使用GPU的时候主要面对的问题在于显存内无法存放TB级别的模型,GPU的多线程并行能力对稀疏数据不够友好。
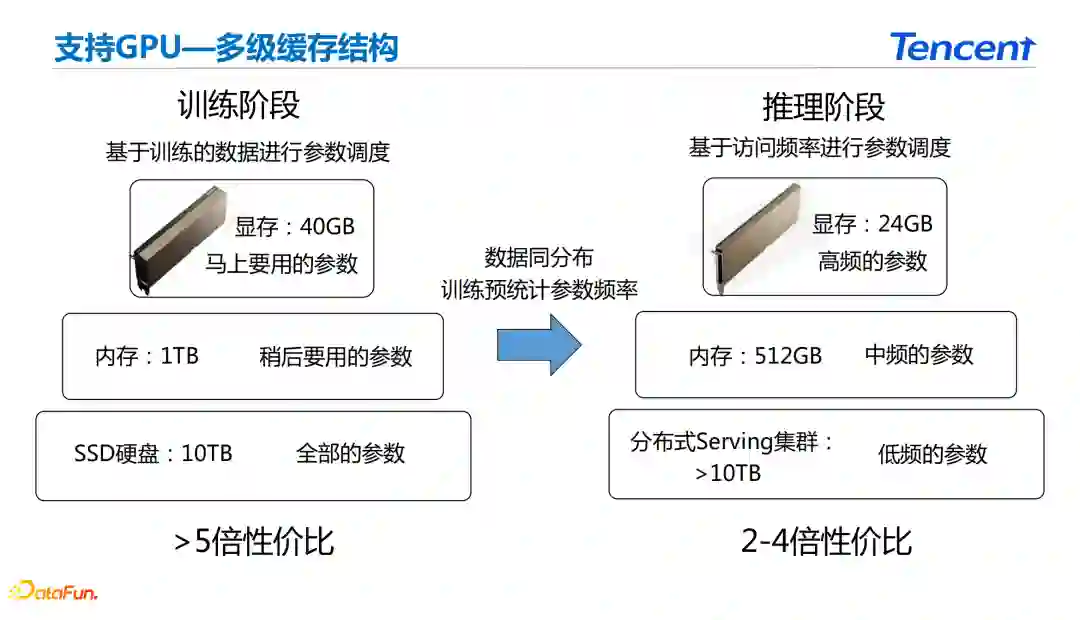
为了解决上面的问题,在支持GPU的情况下采用多级缓存的方案。在推荐当中使用到的数据具有很强的局部性。从训练的角度来讲,系统需要更高的训练样本吞吐能力。在推理阶段除了吞吐能力之外还需要满足系统的响应速度。 在训练过程中存储了全部的参数,在内存中存储了稍后需要使用的参数,在显存中存储了立刻需要使用的参数。在推理阶段在分布式Serving集群中存储低频的参数,在内存中存储中频的参数,在显存中使用高频的参数。在推理端位了减少参数频率统计带来的开销,基于数据同分布的假设统计训练端参数的频率来进行Serving端的三级缓存。
04
Q&A
Q1:无量推理端serving模型参数分布式和多副本是内存中存储吗?是通过serving来维护一致性吗? A1:推理端多副本是存储在内存当中进行存储的,这些副本之间可以进行强同步但是目前条件是放开的,在持续上线迭代的过程中对于推荐类模型的一致性要求相对来说不高。系统可以进行强一致,比如使用带版本号的访问,这个功能是否开启由使用方来决定。 Q2:三值量化能详细讲一讲吗? A2:在训练过程中模型是全精度保存的,但是在进入训练到应用的过程中会对模型进行量化。在量化完之后基于量化的结果训练出一个梯度,并且将梯度更新到全精度的模型上去。如果在推理过程中只是导出量化结果,然后在推理过程中进行反量化,从而保证推理结果的一致性。 Q3:GPU多级缓存实际参数放到SSD对于推荐这些悉数参数多的场景训练速度能跟上吗? A3:训练速度能不能跟上关键的地方在于SSD处理和训练相关的参数的速度,只要在训练的时候提前拿到下一个训练批次需要使用的参数就可以了。对于目前SSD的性能来说是可以满足的。 Q4:零拷贝通讯是怎么实现的? A4:零拷贝通讯是指计算完了假设有三个key,分别为key1、key2和key3。假设key1和key3在server1,key2在server2上。在通讯之前需要将key1和key3重新排布,这种情况下必然有一次拷贝过程。需要做零拷贝的话,只要预先知道key1和key3在server1上,key2在server2上。在发送的时候预先排布好key的顺序,将数据发给下一层就没有任何的拷贝操作。 Q5:如果训练样本都被污染了,导致线上模型都有问题如何保证线上模型预测的准确性? A5: 只能将模型回滚到污染点之前的模型上。 Q6:特征提取和处理是在推理服务上吗? A6:两种方案:业务可以在前端做好特征工程的工作,将数据处理放在业务方自己完成。无量的推理服务提供了一个特征工程的插件使得特征转化的工作可以在推理阶段完成。
分享嘉宾:


