【泡泡点云时空】LaserNet:一种用于自动驾驶的高效三维目标概率检测器
泡泡点云时空,带你精读点云领域顶级会议文章
标题:LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
作者:Gregory P. Meyer, Ankit Laddha, Eric Kee, Carlos Vallespi-Gonzalez, Carl K. Wellington
来源:arxiv 2019
编译:陈贝章
审核:徐二帅,吕佳俊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

在本文中,我们介绍一种用于自动驾驶的激光3D目标检测法——LaserNet。它高效的性能来自于激光雷达的视场范围中的原始点云数据进行压缩处理。在激光雷达视场范围中的操作涉及检测任务方面的公认挑战,包括遮挡和尺度变化,但它还基于传感器是如何感知数据来提供上下文信息。本方法使用全卷积网络来预测每个3D检测框内的点云多模态分布,然后高效地融合这些分布以生成每个对象的预测。实验表明,将每个检测建模为分布而不是单一确定性框会有更好的整体检测性能。基准测试结果表明,这种方法运行时明显低于其他目前的检测器,相比通过大量数据来克服视场范围目标检测训练的挑战,本方法取得了最先进的性能表现。
主要贡献
提出了一种以端到端的方式学习3D物体概率检测的有效方法——LaserNet。
当有足够的训练数据时,LaserNet能以更低的运行时间取得更高效的检测性能。
LaserNet不仅产生每次检测的类概率,而且产生检测边界框的概率分布,得益于使用小而稠密的范围视场而不是传统检测器中大而稀疏的鸟瞰图像作为检测的输入。
LaserNet是第一个通过对边界框角的分布建模来捕获检测的不确定性。

图1:本方法的检测结果如底部图所示,由中间的深度图输入生成。在顶部的图像仅供参考。值得注意的是,深度图像的数据稠密,但投影到3D空间时变得稀疏。
算法框架
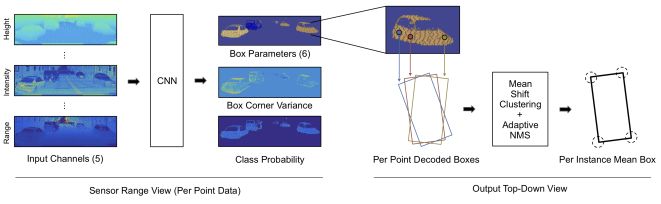
图2:本3D目标检测方法概述。我们使用传感器固有的视场范围表示来构建稠密的输入图像(第3.1节)。图像通过全卷积网络以产生一组预测(第3.2节)。对于图像中的每个LiDAR点,我们预测一个类概率,并在俯视图中对边界框中的概率分布进行回归(第3.3节)。这些每点分布通过均值偏移聚类相结合,以减少各个预测中的噪声(第3.4节)。对整个检测器端到端地进行训练,并在边界框上定义损失(第3.5节)。在推论中,我们利用一种新颖的自适应非最大抑制(NMS)算法来消除重叠的边框中的分布(第3.6节)。
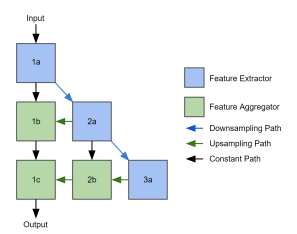
图3:我们的深层聚合网络架构。列表示不同的分辨率级别,行表示聚合阶段。
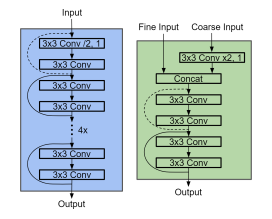
图4:我们的特征提取模块(左)和特征聚合模块(右)。这些模块是残差网络。虚线表示执行卷积以重建特征图。
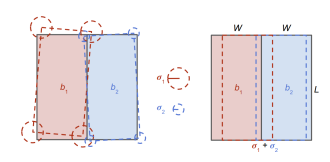
图5:我们的自适应非最大抑制(NMS)技术的图示。考虑一对并排放置的车辆。左侧的虚线轮廓描绘了我们的方法生成的一组可能的预测。为了确定边界框是否包含了唯一对象,我们利用预测的方差(如中心所示)来估计最坏情况下的重叠,如右图所示。在此示例中,将保留两个边界框,因为实际重叠小于估计的最坏情况重叠。
主要结果
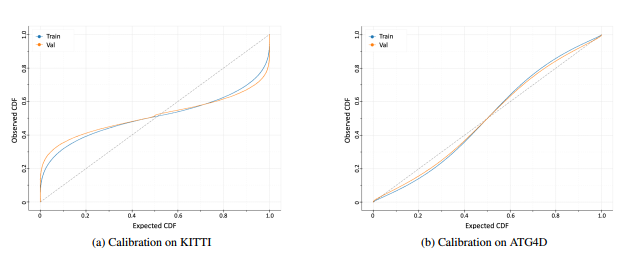
图6:显示在训练集和验证集上的边界框上的预测分布的校准的图。完美校准的分布对应于具有单位斜率的线(图中的虚线)。我们观察到该模型无法学习KITTI的概率分布,而它能够学习更大的ATG4D上的分布。
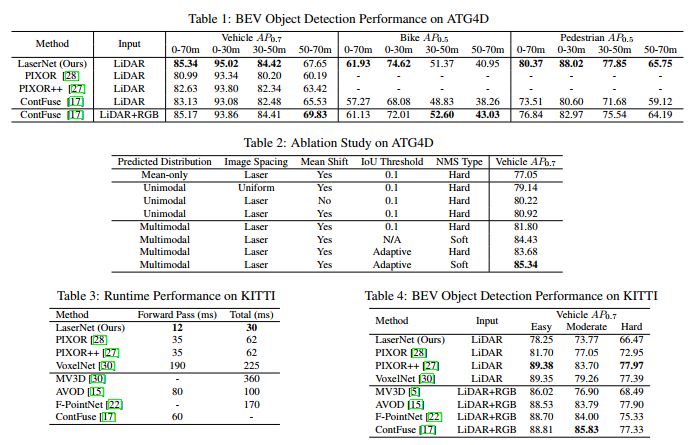
表1:显示了我们在验证集上与其他最先进方法相比的结果;表2:对ATG4D数据集进行模型简化测试结果;表3:比较了我们的方法(在NVIDIA 1080Ti GPU)和KITTI上的现有方法之间的运行时性能;表4:我们的方法在这个小型数据集上与目前最先进的俯视角检测效果比较。

Abstract
In this paper, we present LaserNet, a computationally efficient method for 3D object detection from LiDAR data for autonomous driving. The efficiency results from processing LiDAR data in the native range view of the sensor, where the input data is naturally compact. Operating in the range view involves well known challenges for learning, including occlusion and scale variation, but it also provides contextual information based on how the sensor data was captured. Our approach uses a fully convolutional network to predict a multimodal distribution over 3D boxes for each point and then it efficiently fuses these distributions to generate a prediction for each object. Experiments show that modeling each detection as a distribution rather than a single deterministic box leads to better overall detection performance. Benchmark results show that this approach has significantly lower runtime than other recent detectors and that it achieves state-of-the-art performance when compared on a large dataset that has enough data to overcome the challenges of training on the range view.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



