ICML 2021 | 微软亚洲研究院精选论文一览

基于数据采样的影响力最大化问题

论文链接:https://arxiv.org/abs/2106.03403
基于数据采样的优化(Optimization from Samples,OPS)是将机器学习和优化相结合,实现从数据到优化的端到端的性能保证。然而近期的研究指出,虽然从数据到模型的学习过程和基于模型的优化各自能给出较好的理论保证,但是 OPS 在一些情况下是不能达到端到端的理论保证的。
微软亚洲研究院和中国科学院计算技术研究所的研究员们在去年的 ICML 会议上提出了基于结构化数据采样的优化方法(Optimization from Structured Samples, OPSS),通过巧妙地利用采样数据中的结构化信息,将学习和优化更紧密地结合, 从而达到端到端性能的理论保证。
在今年 ICML 会议上发表的本文,沿 OPSS 方向进一步探索,更进一步研究了比较复杂的基于数据采样的影响力最大化问题(Influence Maximization from Samples, IMS)。具体是指:当社交网络未知,只能观察到其上的历史传播数据时,如何选取少数种子结点以达到影响力最大化的传播效果。传统的方式是先从历史传播数据中学习,得到一个传播模型和模型参数,然后在这套模型和参数上运行成熟的基于影响力最大化的算法。但这样的方法会导致在某些情况下,模型及其参数的学习效果不好时,优化的效果也不尽如人意。因此需要对这种传统模式加以改进,在模型参数学习效果不好时仍能找到替代方法,从而达到良好的优化效果。
从端到端来讲,本文的算法可以保证对于任何网络结构和传播参数的组合,都能从传播数据采样中得到影响力最大化的常数近似解,而且该算法不再依赖于最大似然估计,而是通过简单直接的等式推导,使得网络推断可以基于更宽泛的假设从而达到运算速度更快、需要更少数据样本的效果。同时,在解决 IMS 问题的过程中,网络推断(Network Inference)算法也得到了改进。
PoolingFormer:具有池化注意力机制的长序列输入模型

论文链接:https://arxiv.org/abs/2105.04371
Transformer 模型已被广泛应用于自然语言处理、计算机视觉、语音等诸多领域,并且取得了卓越的结果。但对于超长序列输入,Transformer 模型受到了极大的限制,因为其核心组件“自注意力机制”导致计算和记忆复杂度随序列长度呈二次增长。为了限制这种增长,微软亚洲研究院提出了一种新颖的两级注意模式:PoolingFormer,经验证,该机制在 Natural Question、TyDi QA、Arxiv 摘要生成数据集上,都取得了较好的效果。
在自注意力机制中,token 的表征计算可以简述为其视野范围内邻居表征的加权和。一般来说,令牌“看”得越远,性能就越好,但计算复杂度也更高。微软亚洲研究院的研究员们观察到,对于一个 token 的表征,离它最近的邻居更重要,而越远距离的邻居,包含的冗余信息就越多。根据这一观察,研究员们探索了更有效的自注意力机制。
PoolingFormer 将原始的全注意力机制修改为一个两级注意力机制:第一级采用滑动窗口注意力机制,限制每个词只关注近距离的邻居;第二级采用池化注意力机制,采用更大的窗口来增加每个 token 的感受野,同时利用池化操作来压缩键和值向量,以减少要参加注意力运算的令牌数量。这种结合滑动注意力机制和池化注意力机制的多级设计可以显著降低计算成本和内存消耗,同时还能获得优异的模型性能。与原始的注意力机制相比,PoolingFormer 的计算和内存复杂度仅随序列长度线性增加。
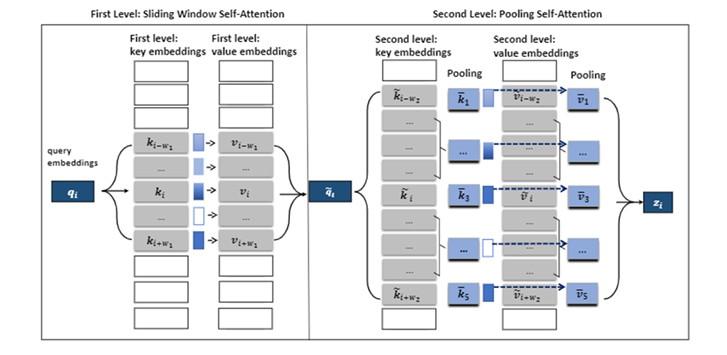
图1:PoolingFormer 的两级注意力机制
在主试验部分,研究员们选取了三个具有挑战性的长文档建模任务进行测评,分别是:单语言长文本问答——Natural Question;跨语言长文档问答——Tydi QA;长文档摘要生成——Arixiv 摘要数据集。结果如下图:
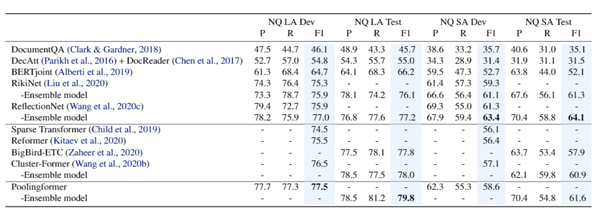
图2:Natural Question 实验结果
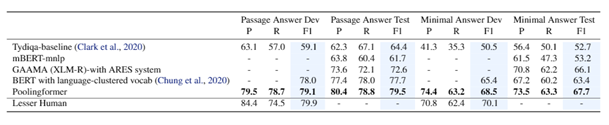
图3:TyDi QA 实验结果
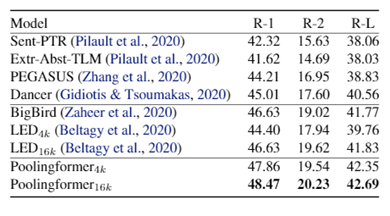
图4:Arxiv 摘要生成数据集实验结果
为序列学习训练的时间关联型任务调度器

论文链接:http://proceedings.mlr.press/v139/wu21e/wu21e.pdf
序列学习(Sequence Learning)是一类很重要的机器学习任务,在序列学习中,很多任务是时间相关联的(Temporally Correlated),例如,在同声传译中,给定输入的句子,不同延迟下的翻译是时序相关的;在股票预测中,未来几天的股票价格也是相关的。一组时序相关联任务的区别在于能够利用多少输入信息(如同传),以及需要预测未来哪一步的信息(如股票预测)。给定一个主任务,直观上来说,它的时序相关联任务对提升主任务效果是有帮助的,然而如何利用辅助任务并没有得到充分探索。为此,微软亚洲研究院的研究员们提出了一种基于 Bi-level Optimization 的方案,对于一个给定的序列学习任务,能够自适应地利用它的时间相关联任务,提升任务效果。
给定一个序列学习任务 T,研究员们将输入和输出数据记作 x 和 y, 其中 x 是序列,y 可以是序列也可以是标签。一组给定的 x 和 y 可以对应不同的任务 T,例如在不同延迟下的同声传译,以及预测不同未来天数的股票。
研究员们提出的 Bi-level Optimization 方案训练了一个任务调度器(Task Scheduler),用来决定应该利用哪些时间相关联任务进行训练,训练目标函数如下:
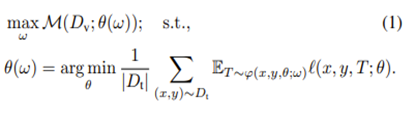
图5:训练目标函数
其中,θ 是主任务的参数,φ 和 ω 是任务调度器的模型和参数,M(D_v, θ(ω)) 表示模型 θ(ω) 在验证集上的结果。在优化过程中,先要固定调度器 φ, 根据当前输入,以及当前主模型(也就是感兴趣的序列学习模型)的状态,决定用哪些任务来学习;而后,再固定主模型,反过来去优化任务调度器。最后,重复前两步,直至收敛。研究员们在同声传译(图6和图7)和股票趋势预测的任务上(表1)都取得了提高。
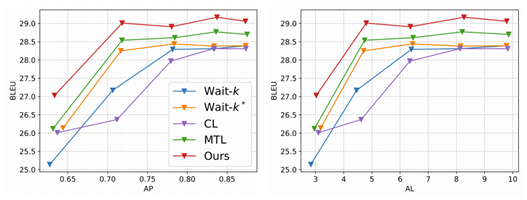
图6:在 IWSLT‘’15 英语到越南语翻译上,本文的算法和其他任务调度算法(课程学习,多任务学习)对比
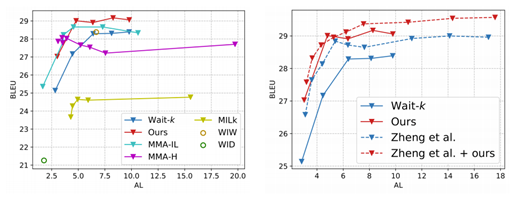
图7:在 IWSLT‘’15 英语到越南语翻译上,本文的算法和近期 State-of-The-Art 算法对比
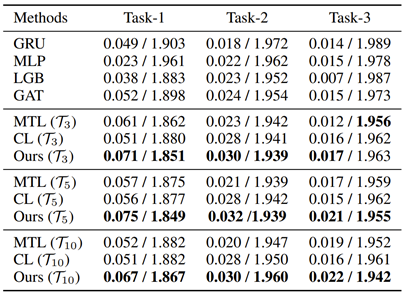
表1:股票预测的结果,其中:Task-i 的任务是预测(price_(t+i))/(price_(t+i-1) )-1,表中展示了 MSE/IC 值
目前研究中的代码已开源:
https://github.com/shirley-wu/simul-mt_temporally-correlated-task-scheduling
https://github.com/microsoft/qlib/tree/main/examples/benchmarks/TCTS
应用于齐次神经网络的隐式正则自适应优化器

论文链接:https://arxiv.org/abs/2012.06244
自适应优化器(Adaptive Optimizer)是一类基于损失函数梯度(Gradient of Loss Function)的优化器,可根据梯度的历史信息,自适应地调节优化步长的特点。AdaGrad、RMSProp 和 Adam 这三个算法是自适应优化器的代表,因为他们能够加速神经网络的训练所以在深度学习领域受到了广泛的关注。与这三个算法在训练集上取得的良好表现相比,它们在测试集上的表现(泛化性质,Generalization Error)有时却不尽人意,并且如何从理论上理解这一现象仍旧是一个丞待解决的问题。本篇论文从隐式正则(Implicit Bias)的角度,解决了损失函数是指数尾部分布情形下的问题。
隐式正则,是指优化算法面对神经网络的多个最优点时,会带有“偏好”地选择收敛点,从而影响神经网络的泛化能力。更具体来说,本文证明了对于齐次的神经网络(包含使用ReLU/多项式激活函数的全连接/卷积神经网络)和 AdaGrad 选取的最优点会严重依赖于参数的初始化,而 RMSProp 以及 Adam 则会收敛到二范数意义 Max Margin Problem 的最优解。
在深度学习的泛化理论中,Margin(模型在数据集上最小的正确标签得分与其他标签中最大得分之差)可以用来被估计泛化误差(Margin 越大,泛化误差越小),所以研究员们证明了 RMSProp 和 Adam 收敛,会收敛到 Margin 意义下泛化误差最大的解,而 AdaGrad 所收敛到的解的泛化性质则会劣于 RMSProp 和 Adam。需要注意的是,对于 Adam 优化器,研究员们只分析了不含动量项(Momentum)的情况,这是由于动量项的加入会使得每一步的迭代不再能保证梯度函数是下降的,从而不能用现有的分析方法解决。对一般的 Adam 优化器进行分析将是一个有趣的课题。
值得一提的是,在技术层面,研究员们给出了分析自适应优化器算法的隐式正则的通用框架——自适应梯度流优化器(Adaptive Gradient Flow),同时给出了该优化器的收敛方向,并提供了如何将 AdaGrad、RMSProp 和 Adam 这类优化器等价为自适应流优化器的方法。该分析通过简单的修正也可以涵盖其他的自适应优化器。
最后,研究员们在 MNIST 数据集上使用卷积神经网络对实验结果进行了验证,实验表明,RMSProp 和 Adam 的 Margin 和泛化性质和 SGD 接近,均优于 AdaGrad,从而支持了文章的理论结果。
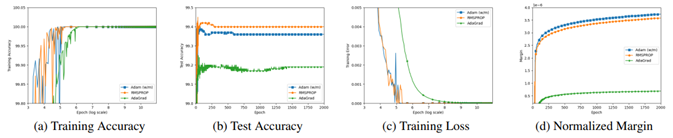
图8:实验分析及验证结果示意图
Unispeech: 基于标记和未标记数据的统一语音表示学习

论文链接:https://arxiv.org/abs/2101.07597
端到端语音识别(Speech Recognition, SR)系统的训练需要大量的标注数据,这对低资源场景来说是一个挑战。为此,微软亚洲研究院的研究员们提出了一种名为 UniSpeech 的方法,能够同时利用监督数据和无监督数据来学习统一的上下文表示。
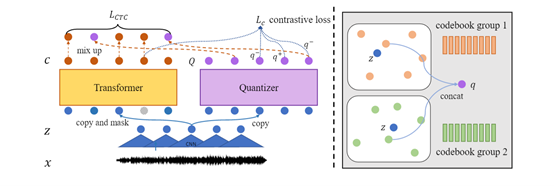
图9:UniSpeech 方法示意图
如图9所示,研究员们的模型包含了基于卷积神经网络(Convolution Neural Network,CNN)的特征提取网络,基于 Transformer 的上下文网络和一个特征量化模块用于学习离散的向量。对于预训练,研究员们采用了多任务学习的方式;对于标记数据,则指定了两个训练目标:第一个是音素级别的 CTC 损失函数,该函数作用于 Transformer 的输出;第二个是在掩码上下文表示和离散潜在表示上定义的对比任务,该任务与 wav2vec2.0 相同。CTC 将每个上下文表示与音素标签对齐,同时,对比损失缩小了离散表示和上下文表示之间的距离。为了进一步明确指导量化器学习 SR 的特定信息,在计算 CTC 损失时,研究员们随机将一部分 Transformer 输出,替换为相应时间的离散表示。
在实验中,研究员们发现这种方法可以激活量化器码本中的更多码字。对于那些未标记数据,研究员们只进行了对比学习。在预训练之后,研究员们固定了特征提取器,并在少量标记的低资源数据上微调了 Transformer 部分。论文在 CommonVoice 数据集上验证了该方法,如表2-表4所示,UniSpeech 在以下三种设置中,均明显优于监督迁移学习和无监督对比学习:(1)单一高资源语言设置到单一低资源语言设置(One-to-One)(2)多语言高资源语言到单一低资源语言设置(Many-to-One)(3)多语言高资源语言到多语言低资源语言设置(Many-to-Many)。
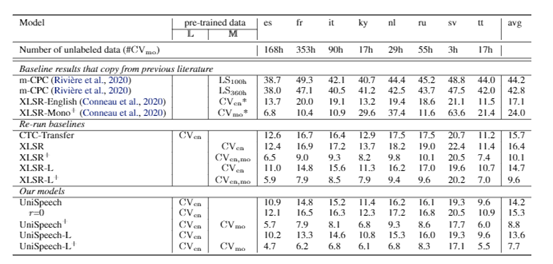
表2:单一高资源语言设置到单一低资源语言设置(One-to-One)
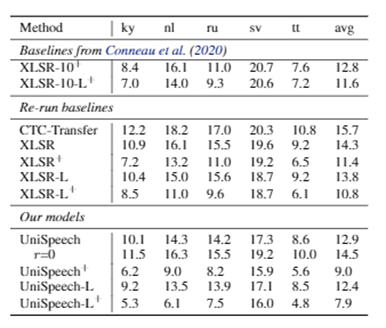
表3:多语言高资源语言到单一低资源语言设置(Many-to-One)
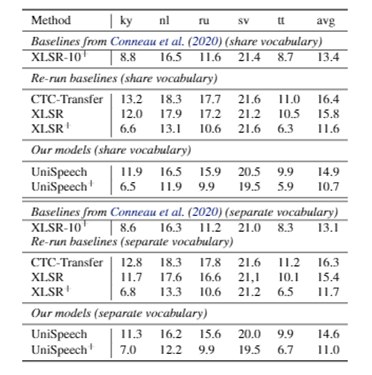
表4:多语言高资源语言到多语言低资源语言设置(Many-to-Many)
你也许还想看: