ICSE 2021:微软亚洲研究院精选论文,洞察软件工程前沿研究

编者按:作为软件工程领域的顶级会议,ICSE (International Conference on Software Engineering) 今年共接收了138篇论文,录取率为22.44%。微软亚洲研究院有多篇论文被收录,今天为大家介绍其中的4篇,研究主题包括:故障分析、逆向工程、配置空间、云计算系统、黑盒后门攻击、深度学习等等。
AutoCCAG:生成约束覆盖阵列的自动化方法

论文链接:
https://www.microsoft.com/en-us/research/publication/autoccag-an-automated-approach-toconstrained-covering-array-generation/
现如今,伴随着软件定制化需求的不断增长,开发高度可配置的软件系统在学术界和工业界也都得到了广泛的关注。高度可配置的系统提供了很多选项,用户可以通过调节这些选项来轻松自定义系统。但是,由于所有可能的配置总数会随着选项数量的增加呈指数级增长,“一不小心”还可能因为某些特定的(不合法的)配置导致系统故障,所以测试一个高度可配置系统所有的可能配置(即所有可能的选项组合)代价极高。
例如,假设一个软件系统有15个选项,每个选项有3个可能的取值,那么在最坏情况下这个系统会有超过一千万种可能的配置(3^15=14,348,907)。因此,这个领域迫切需要更实用并且更高效的测试方法。
组合交互性测试(Combinatorial Interaction Testing, CIT)是一种有效的用于测试高度可配置系统的测试方法。相比较于测试所有可能的配置,CIT 仅需测试少量的配置,大大减少了测试所需的代价。CIT 方法能够生成一个覆盖阵列(Covering Array, CA)。一个 t-way CA 可覆盖所有可能的 t 个不同选项之间取值的合法组合(t被称为覆盖强度)。所以约束覆盖阵列生成(Constrained Covering Array Generation, CCAG)的问题表述是:在给定硬约束的情况下,找到一个最小的约束覆盖阵列(Constrained Covering Array, CCA)。CCAG 已经被证明是一个 NP-hard 优化问题,因此理论上求解 CCAG 问题,非常困难。
已有的 CCAG 方法(如贪心算法、约束编码算法以及元启发式算法)通常只能有效求解 2-way CCAG 和 3-way CCAG,但求解 t-way CCAG(t>=4)仍然是一个技术上的挑战。而有效地求解 t-way CCAG(t>=4)非常重要。例如,有文献表明,在测试交通系统时,3-way CCAG 只能检测74%的故障,然而 4-way CCAG 和 5-way CCAG 则可以分别检测89%和100%的故障。
对此,微软亚洲研究院的研究员们提出了一个生成约束覆盖阵列的自动化方法 AutoCCAG。AutoCCAG 采用了先进的自动算法配置技术(Automated Algorithm Configuration)和自动算法选择技术(Automated Algorithm Selection),可以更加有效地求解 4-way CCAG 和 5-way CCAG 问题。
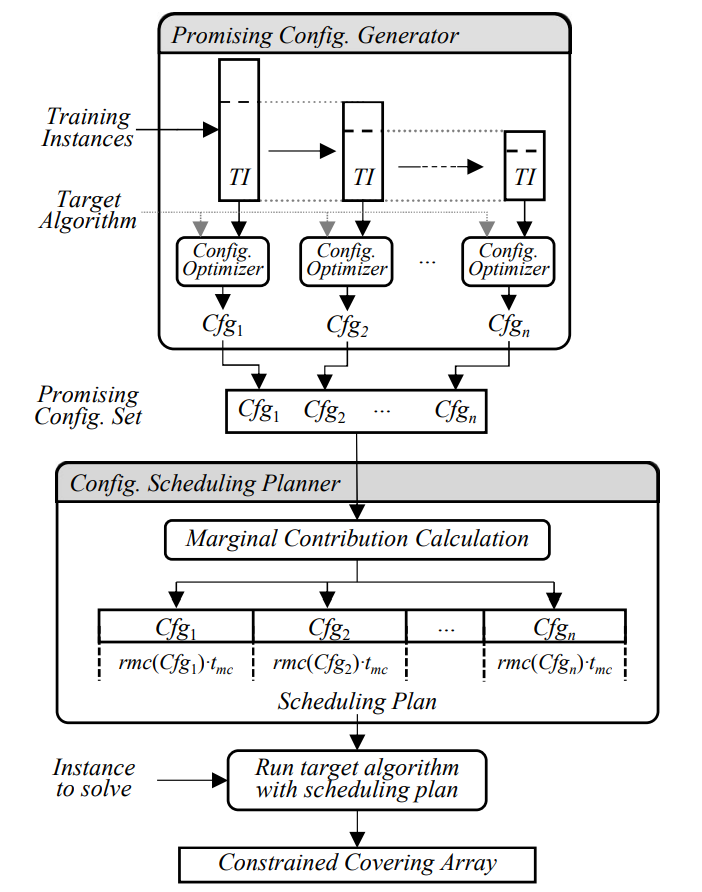
图1: AutoCCAG 架构图
AutoCCAG 包括三个组件:1)配置优化器(Configuration Optimizer),2)有效配置生成器(Promising Configuration Generator),3)配置调度规划器(Configuration Scheduling Planner)。
AutoCCAG 的架构如图1所示。给定一个可配置的 CCAG 算法 a,AutoCCAG 的配置优化器会采用自动算法配置技术用于确定算法 a 的优化参数;然后 AutoCCAG 的有效配置生成器的会生成算法 a 的多个配置并且使得这些配置之间有很强的互补性;之后,AutoCCAG 的配置调度规划器会采用自动算法选择技术构造一个关于算法 a 的配置调度规划。最终,AutoCCAG 通过采用该配置调度规划用来求解给定的 CCAG 问题实例,并且生成相应的约束覆盖阵列。
研究员们将 AutoCCAG 与多种先进的 CCAG 求解算法进行了实验对比(相关实验结果请见表1、2)。实验结果表明,相比较于已有的 CCAG 求解算法,AutoCCAG 在求解 4-way CCAG 以及 5-way CCAG 问题上都展现出了更好的求解性能。
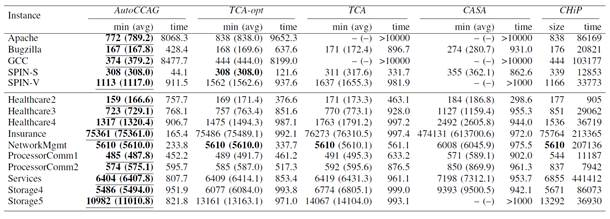
表1: 不同方法在求解 4-way CCAG 问题上的性能对比
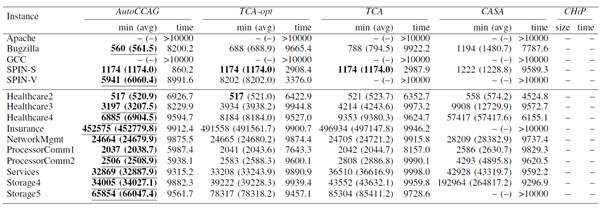
表2: 不同方法在求解 5-way CCAG 问题上的性能对比
DeepPayload:用逆向工程技术对深度学习模型进行黑盒后门攻击

论文地址:
https://arxiv.org/pdf/2101.06896.pdf
如今深度神经网络(DNN)已经被越来越多地应用于安全攸关的移动/边缘端场景中,例如身份认证、自动驾驶、智能安防等,这使得模型的安全性显得愈发重要。目前,神经网络模型运行时,会面对两类攻击——对抗样本攻击(adversarial attack)、后门攻击(backdoor attack)等。其中,后门攻击是指,在模型中植入一些隐藏的逻辑,且在特殊条件下才会触发。显然,后门攻击的存在会导致模型预测结果被“操纵”。例如,一个被植入后门的图片分类模型,可能在当输入的图片有一个特殊标识的时候,将图片识别为某个特定的类别,而当输入图片没有特殊标识的时候则正常工作。
有两种应对后门攻击的主流方法:1. 通过数据投毒(data poisoning)向训练数据中加入异常的样本,从而让模型在训练之后“自带”后门逻辑;2. 对模型内部的神经元进行分析,自动生成后门触发标识,以及生成后门的训练数据。
但以上方法存在两个“致命”的缺点,使其在移动/边缘端场景中并不适用:1. 大多数部署在移动/边缘端应用中的模型,其存在形式都近似于黑盒,例如 .pb, .tflite, .onnx 格式等,其具体功能具有不确定性,所以对模型进行二次训练较为困难;2. 这类方法大多只能实现数字世界的攻击,其后门触发标识往往是对图片中某些特定像素进行直接修改,而对于部署在物理世界的模型,却很难做到对输入进行像素级的控制。因此,要想达成物理世界的攻击,就需要使得后门可以被物理世界真实的物体触发。
在传统软件中,后门攻击往往是通过一系列逆向工程的方法达成,例如通过将程序二进制文件反汇编(disassemble)、植入恶意代码(malicious payload)、重新汇编(reassemble)等过程。这样的做法不需要了解目标程序的具体功能就可以进行大范围的攻击。
因此,微软亚洲研究院的研究员们开始思考,类似的逆向工程思路能否用于黑盒神经网络模型的攻击?答案是肯定的,类似于传统软件,模型也可以被反汇编成数据流图的形式。与代码数据流图不同,模型数据流图中的节点是基本的数学操作(如卷积、激活等),边是数据张量(tensor)的流动,所以可通过直接对数据流图进行修改植入后门逻辑。
研究员提出的 DeepPayload 方法的具体思路是:在模型中自动加入一个旁路。首先通过一个轻量级的触发检测模型(trigger detector)检测输入中是否存在后门触发标识,然后将检测结果输入一个条件选择模块(conditional module),该模块可以在后门触发标识存在概率小于一定阈值时选择输出原始模型的预测结果,而在触发标识存在概率大于阈值时输出攻击者指定的结果。在没有关于模型所在环境数据分布的先验知识的情况下,攻击者可以通过使用数据增强的方法,模拟出触发标识在图片不同位置、角度、大小、光照条件下的情形,进而在增强之后的数据上训练,使得模型能在不同背景环境下检测到触发标识。另外,条件选择模块是由 ReLU、Mask、Sum 等神经网络基础操作符构成,实现了与传统程序中 if-else 语句等价的逻辑。
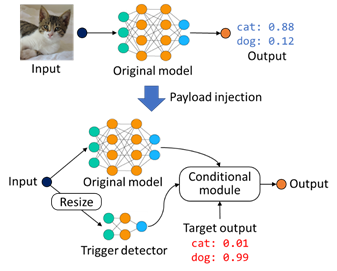
图2:基于逆向工程的后门攻击原理示例
为了验证 DeepPayload 方法的有效性,研究员们使用从30个用户处收集的真实场景图片对攻击方法进行了评估,实现证明该方法能够以93.5%的准确率触发后门。同时,植入的后门对模型的延迟、准确率影响都很小(0.3%~3.1%)。
通过分析116个包含深度学习模型的安卓应用,研究员们还发现其中54个应用可以被该方法成功攻击。这些应用的领域包括:支付、商业、教育等等,有的下载量达到了千万级别。这表明目前开发者对模型保护的意识还相对薄弱,希望这项工作能唤起广大开发者和市场监管者对软件中神经网络模型的保护意识。
COT:利用服务关系挖掘、加速大规模云系统故障分析

论文地址:
https://arxiv.org/pdf/2103.03649.pdf
随着云计算系统的快速发展,越来越多的企业选择将它们的服务迁移到云计算平台上。因此,大规模云计算平台,如微软 Azure 云计算平台等,在支撑着数量庞大的云计算服务与终端用户的同时,保障其高可用性十分关键。
然而,尽管云服务提供商们在保障其云服务可靠性上都投入巨大,但云平台仍然会面临各种故障(Incidents)。其中有一类故障称之为 Outage,其特征是:可能会对云平台中多个互相依赖的服务产生严重影响,并导致故障传递至面向用户的服务中。显然,Outage 一方面会影响用户的使用体验,另一方面也会带来巨大的经济损失。
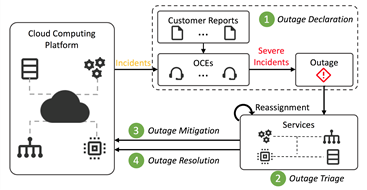
图3 :Outage 生命周期
在现有基于服务分层抽象、虚拟化等技术的 Devops 工业实践中,由于 Outage 会从多个服务(如用户直接使用的服务)的报告中同时得知,寻找 Outage 原因的过程会涉及大量诊断与跨团队沟通,所以这个过程十分耗时。对此,微软亚洲研究院的研究员们设计实现了 COT(Correlation-based Outage Triage),通过挖掘历史 Outage 诊断记录中的有用信息,加速 Outage 根因定位的过程。
COT 的思路是,对于历史上的每一个 Outage,研究员们都挖掘与该 Outage 相关的故障之间的关联信息,并以服务为单位,将故障之间的关联信息进行聚合,然后,以 Outage 中服务之间的故障关联为特征,以 Outage 的根因服务为标签,训练机器学习模型。在新的 Outage 发生后,研究员们可以通过历史故障的关联信息,快速找到与该 Outage 相关的故障,并用相同的方法对这些故障进行聚合与特征提取,再利用先前训练好的机器学习模型来预测其根因服务。
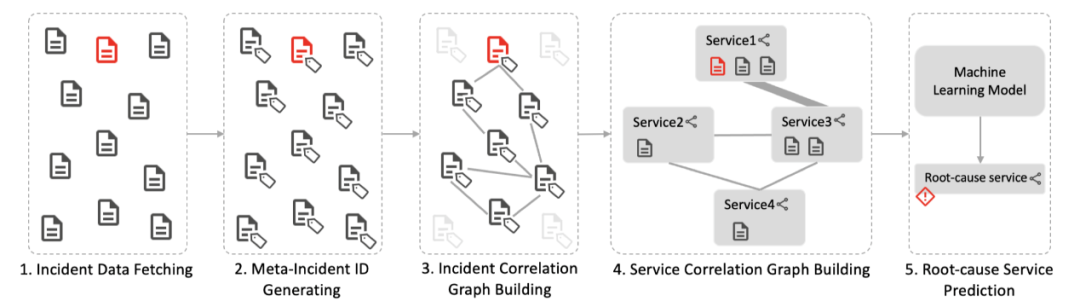
图4:COT 方法概览
研究员们将 COT 与当前研究中最先进的方法(DeepCT)进行了对比测量。COT 在不同时间窗口设置下,可以实现 82.1% ∼ 83.5% 的预测准确率,相较于 DeepCT 的准确率高出 28.0%∼29.7%。同时 COT 的执行十分高效,其预测 Outage 根因服务的时间开销可控制在一分钟以内。
现在,COT 已经部署于微软 Azure 云计算平台的生产环境中,辅助工程师加速 Outage 的分析过程。另外,针对 Outage 所构建的服务之间的故障关联,COT 也为工程师理解故障在服务之间的传递模式提供了重要的参考依据。
DnnSAT:用于深度学习模型资源导向的配置空间约简

论文地址:
https://www.microsoft.com/en-us/research/publication/resource-guided-configuration-space-reduction-for-deep-learning-models/
许多传统的软件系统,例如编译器和 Web 服务器,都提供了大量的配置选项(configuration option),通过不同的选项组合来满足不同条件下的系统质量(例如吞吐量)要求。与传统的可配置软件系统类似,语音识别、聊天机器人和游戏等部署深度学习技术的现代软件系统,也为开发人员提供了两大类的多种模型配置选项——超参选项(如批处理大小和学习率)以及网络结构选项(如网络层数和每层的类型)。
由于模型的选项众多,组合而成的模型配置(model configuration)数量呈指数方式增长,从而导致手工调参方式低效、繁琐且易出错。尽管有大量的自动化机器学习(AutoML)工具可供使用,也能通过提交成百上千的训练任务搜索优质的模型配置,但依然无法解决配置空间的指数爆炸问题。
微软亚洲研究院的研究员们认为,约简模型的配置空间是快速搜寻最优模型配置以及整体提升深度学习开发效率的有效途径。其理由为:由于资源方面的限制,不满足资源需求约束的模型配置会造成训练任务的失败或产出不符合要求的模型,从而浪费系统资源、降低生产力。例如某个批处理大小为256的 PyTorch ResNet-50 训练任务在 NVIDIA Tesla P100 GPU 上触发了 out-of-GPU-memory 的异常。这是因为该任务需要 22GB 显存,但是 P100 GPU 只有 16GB。此外,AutoML 工具的使用还会“放大”这些故障的危害,因为其它使用相同批处理大小的上百个训练任务都可能把显存耗尽。
如何有效地约简模型的配置空间?微软亚洲研究院的研究员们提出了 DnnSAT,一种资源导向的配置空间约简方法。DnnSAT 能够帮助开发人员和 AutoML 工具提前去除不满足资源需求约束的模型配置,从而节省出可观的系统资源用于搜寻更多的模型配置。
实现 DnnSAT 方法的具体思路是,把配置空间的约简归约成约束满足问题(constraint satisfaction problem),提供一个统一的、解析的代价模型来构建关于模型权重大小(model weight size)、浮点操作数目(number of floating-point operations)、模型推理时间(model inference time)和 GPU 显存消耗(GPU memory consumption)的常用约束,并调用微软 Z3 SMT (satisfiability modulo theories)solver 获得所有可满足的模型配置。对于模型的任一系统质量属性(quality attribute),DnnSAT 方法都可以定义一组约束,从而进一步约简模型的配置空间。(本论文仅讨论了资源需求的约束。)
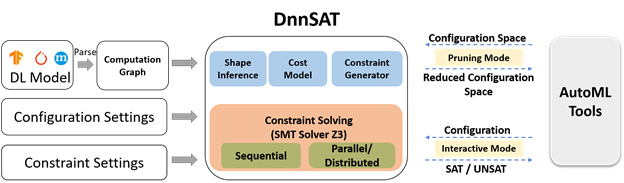
图5:DnnSAT 的工作流程
在图5 DnnSAT 的工作流程中,可以看到工具的输入是模型文件、模型配置信息和约束设置。DnnSAT 首先加载了模型文件以构建出相应的计算图(computation graph),再根据操作符(operator)的实际执行顺序遍历此图,随后使用预建的操作符代价函数逐步创建模型的资源使用函数(该函数以超参和网络结构为参数,使用 SMT LIB 格式描述),最后将资源使用函数和用户设置的资源上下界交由微软 Z3 SMT solver 求解。
研究员们设计了多项实验用于来验证 DnnSAT 对 AutoML 算法的加速效果、配置空间约简效率以及约束求解速度。首先,在公开的 AutoML 基准测试——HPOBench 和 NAS-Bench-101 中,DnnSAT 明显地加速了随机、演化、Hyperband 以及强化学习等多种代表性超参数与模型结构搜索的算法,获得1.19—3.95倍的加速比。此外,DnnSAT 还显著地约简了 VGG-16 和基于 LSTM 的 Seq2Seq 这两种典型深度学习模型的配置空间。例如,在多种 GPU 显存容量的实验约束下,VGG-16 模型的配置空间约简为原有的42.1%~84.3%;在不同批推理时间上界的实验约束下,Seq2Seq 模型的配置空间约简为原有的33.2%~74.1%;越严格的约束条件会产生更明显的约简效果。最后,为了加快约束求解速度,DnnSAT 实现了并行求解、微小配置空间和区间过滤的优化策略,从而获得了数量级的求解加速效果。研究员们相信,DnnSAT 可以让 AutoML 技术在资源受限的实际环境中更加高效和实用。

你也许还想看: