ACL 2019 | 微软8篇精选论文解读,一览最新研究进展

编者按:ACL 2019将于7月28日至8月2日在意大利佛罗伦萨举行。在本届大会的录取论文中,共有25篇来自微软亚洲研究院和微软(亚洲)互联网工程院。内容涵盖文本摘要、机器阅读理解、推荐系统、视频理解、语义解析、机器翻译、人机对话等多个热门领域。本文将为大家介绍来自不同领域中有代表性的8篇论文。
近两年,自然语言中的预训练模型如ELMo、GPT和BERT给自然语言处理带来了巨大的进步,成为研究热点中的热点。这些模型首先需要在大量未标注的文本上训练一个从左到右(left-to-right language model)或从右到左(right-to-left language model)或完形填空式(masked language model)的语言模型。以上过程称为预训练(pre-training)。预训练完的模型便具有了表示一个句子或一个词序列的能力,再针对不同的下游任务进行微调(finetuning),然后可以在下游任务上取得不错的效果。
但是上述预训练模型无论是对句子还是文章进行建模时都把它们看成一个词的序列。而文章是有层级结构的,即文章是句子的序列,句子是词的序列。微软亚洲研究院针对文章的层级结构提出文章表示模型HIBERT(HIerachical Bidirectional Encoder Representations from Transformers),HIBERT模型在抽取式文本摘要任务中取得了很好的效果。
代表论文:HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization
论文链接:https://arxiv.org/abs/1905.06566
如图1所示,HIBERT的编码器是一个Hierachical Transformer(句子级别的Transformer和文章级别的Transformer)。句子级别的Transformer通过句内信息学习句子表示,而文章级别的Transformer通过句间信息学习带上下句背景的句子表示。
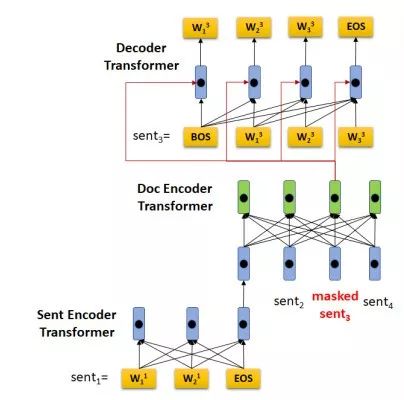
图1:HIBERT模型架构
与BERT类似,HIBERT需要先进行无监督的预训练(pre-training),然后在下游任务上进行有监督的微调(finetuning)。HIBERT预训练的任务是掩盖(MASK)文章中的几句话,然后再预测这几句话。如图1所示,文章的第三句话被MASK掉了,我们用一个Decoder Transformer去预测这句话。
在大量未标注数据上进行预训练后,我们把HIBERT用在抽取式摘要中。抽取式摘要的任务定义如下:给定一篇文章,摘要模型判断文章中的每个句子是否为这篇文章的摘要。得分最高的K个句子将被选为文章摘要(K一般在dev数据上调试得到)。基于HIBERT的摘要模型架构如图2所示,编码器仍然是一个Hierachical Transformer,一篇文章的句子被HIBERT读入后,对通过HIBERT学习到的带上下句背景的句子表示进行分类。
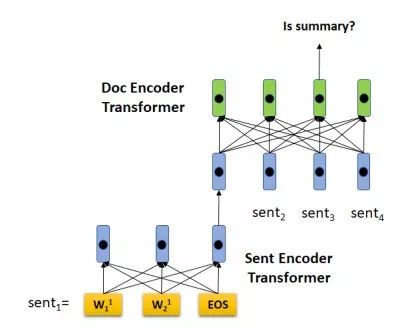
图2:基于HIBERT的摘要模型架构
HIBERT在两个著名的摘要数据集CNN/DailyMail和New York Times上结果都表现很好,超越了BERT及其它在2018年和2019年初提出的所有摘要模型。
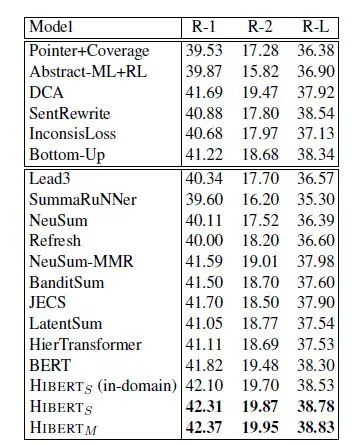
表1:摘要数据集CNN/DailyMail上不同模型的实验结果
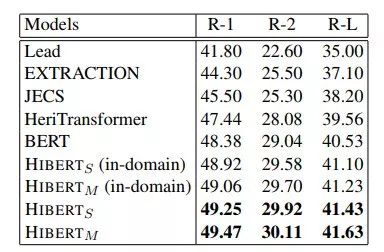
表2:摘要数据集New York Times上不同模型的实验结果
机器阅读理解在近两年取得了巨大的进步,当答案为文档中的一个连续片段时,系统已经可以十分准确地从文档中抽取答案。有许多工作从模型结构的角度来提高阅读理解系统的表现,借助大规模标注数据训练复杂模型,并不断刷新评测结果;同时也有工作通过增强训练数据来帮助系统取得更好的结果,如借助其它数据集联合训练、通过回译(back translation)丰富原文等。
然而在现实生活中,往往无法保证给定的文档一定包含某个问题的答案,这时阅读理解系统应拒绝回答,而不是强行输出文档中的一个片段。针对这一问题,同样有很多工作从模型角度切入,以提高系统判断问题是否可以被回答的能力,做法可大致分为在抽取答案的同时预测问题可答性和先抽取答案再验证两类。而微软亚洲研究院的研究员从数据增广的角度来尝试解决这一问题。
代表论文:Learning to Ask Unanswerable Questions for Machine Reading Comprehension
论文链接:https://arxiv.org/abs/1906.06045
该论文提出根据可答问题、原文和答案来自动生成相关的不可答问题,进而作为一种数据增强的方法来提升阅读理解系统的表现。我们利用现有阅读理解数据集SQuAD 2.0来构造不可答问题生成模型的训练数据,引入Pair2Seq作为问题生成模型来更好地利用输入的可答问题和原文。

图3:SQuAD 2.0数据集中的问题样例
SQuAD 2.0数据集包含5万多个不可答问题,并且为不可答问题标注了一个看起来正确的答案(plausible answer)。图3展示了SQuAD 2.0中一个文档和相应的可答与不可答问题,可以看到这两个问题的(plausible)答案对应到同一个片段,用词十分相似且答案具有的类型(organization),通过对可答问题进行修改就能得到相应的不可答问题。根据这一观察,我们以被标注的文本片段为支点来构造训练问题生成模型所需的数据。
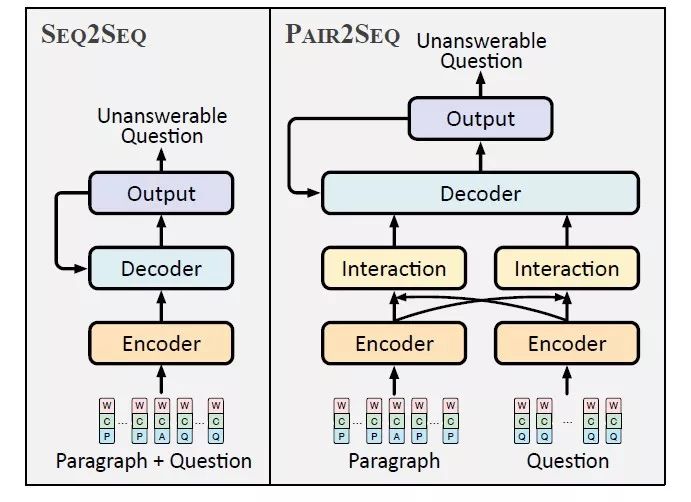
图4:Pair2Seq模型与Seq2Seq模型的流程图对比
在阅读理解系统中,问题与文档的交互是最为关键的组成部分,受此启发,该论文提出Pair2Seq模型,在编码(encoding)阶段通过注意力机制(attention mechanism)得到问题和文档的加强表示,共同用于解码(decoding)。如表3所示,Pair2Seq模型在多个评价指标上超过Seq2Seq模型。
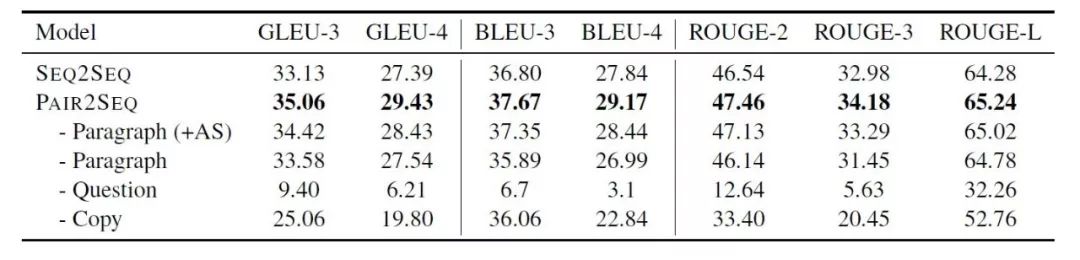
表3:Pair2Seq模型与Seq2Seq模型在多个评价指标上的对比结果
如表4所示,生成的问题作为增强数据能够提高机器阅读理解模型的表现。
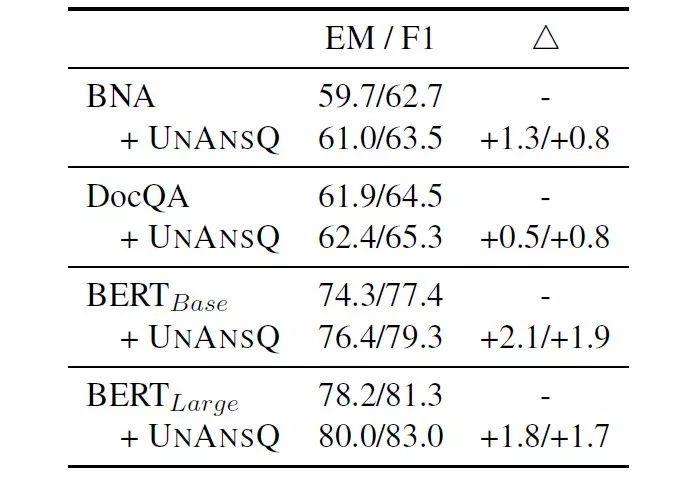
表4:SQuAD 2.0数据集上的实验结果
个性化新闻推荐是解决新闻信息过载和实现个性化新闻信息获取的重要技术,能够有效提升用户的新闻阅读体验,被广泛应用于各种在线新闻网站和新闻APP中。学习准确的用户兴趣的表示是实现个性化新闻推荐的核心步骤。对于很多用户来说,他们不仅存在长期的新闻阅读偏好,也往往由于受社会和个人环境的影响,拥有一些短期和动态的兴趣。然而已有的新闻推荐方法通常只构建单一的用户表示,很难同时准确建模这两种兴趣。
代表论文:Neural News Recommendation with Long- and Short-term User Representations
论文链接:https://nvagus.github.io/paper/ACL19NewsRec.pdf
该论文提出了Long- and Short-term User Representations(LSTUR)模型,用于在新闻推荐任务中同时学习用户长期和短期的兴趣表示。模型的整体结构可分为四个模块,分别是新闻编码器、用户长期兴趣和短期兴趣模型、以及候选新闻的个性化分数预测模型。
新闻编码器模块从新闻标题、新闻的类别和子类别构建新闻表示向量。新闻标题的原始文本先映射为词向量,然后通过CNN获得局部表示,最后通过Attention网络选取重要的语义信息构成新闻标题表示。新闻的类别和子类别分别映射为稠密向量,与新闻标题表示拼接作为最终的新闻表示。
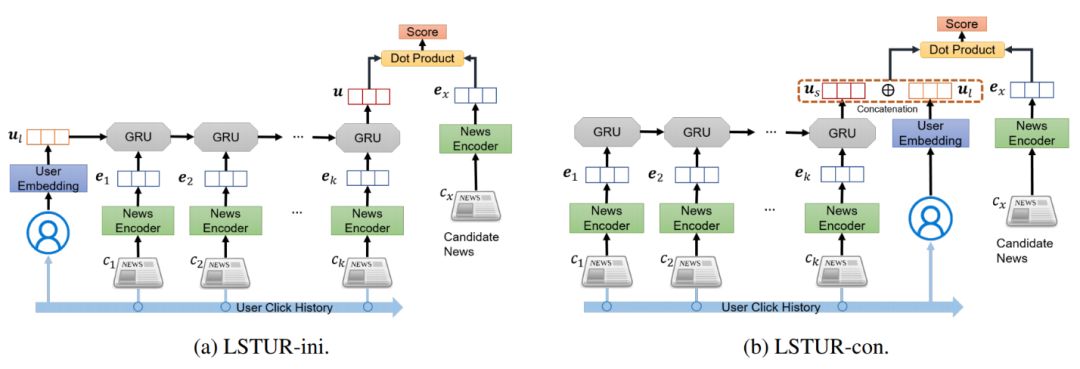
图5:LSTUR模型架构
用户短期兴趣表示模块用于从用户近期点击过的新闻历史中学习用户的表示向量,然后将这些点击的新闻的表示向量按时间顺序依次通过GRU模型得到用户短期兴趣表示。用户长期兴趣表示模块则是从用户的ID中学习用户的表示向量。对于如何同时学习用户长期和短期的兴趣表示,该论文提出了两种结合方式:(1)将用户长期兴趣表示作为用户短期用户表示计算中GRU的初始状态(LSTUR-ini);(2)将用户长短期兴趣表示拼接作为最终用户表示(LSTUR-con)。候选新闻的个性化分数通过用户表示向量和新闻表示向量的内积计算,作为众多候选新闻针对特定用户个性化排序的依据。
该论文提出的方法存在的一个问题是无法学习新到来用户的长期兴趣的表示向量。在预测的过程中简单地将新用户的长期兴趣表示置为零向量可能无法取得最优的效果。为了解决这个问题,该论文提出在模型训练的过程中模拟新用户存在的情况,具体做法是随机掩盖(mask)部分用户的长期兴趣表示向量,即用户的长期兴趣表示向量会以概率p被置为全零向量。实验表明,无论是LSTUR-ini还是LSTUR-con,在训练过程中加入长期兴趣随机掩盖(random mask)的做法均能明显提升模型效果。
该论文在MSN新闻推荐数据集上进行了实验,并和众多基线方法进行了对比,结果如表5所示。
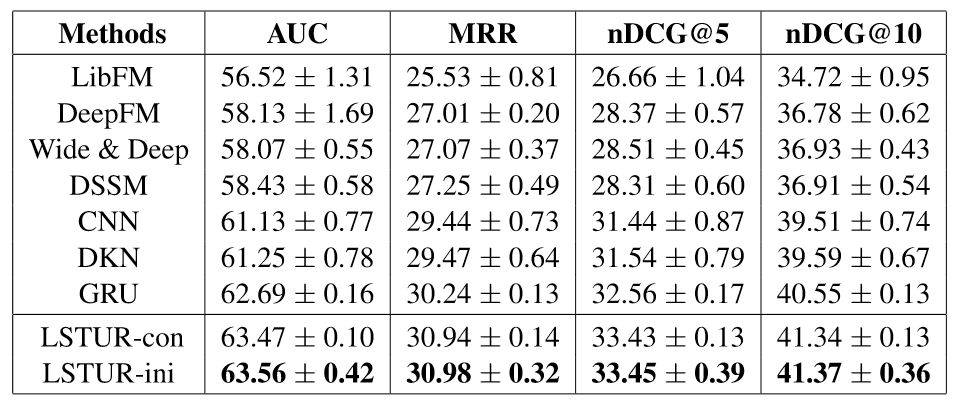
实验结果表明,同时学习长期和短期用户兴趣表示能够有效地提升新闻个性化推荐的效果,因此该论文提出的两种方法均明显优于基线方法。
近年来,随着运算能力的提升和数据集的涌现,有关视频理解的研究逐渐成为热点。视频数据往往蕴含着丰富的信息。其中,既包含较底层的特征信息,例如视频帧的编码表示;也包含一些高级的语义信息,例如视频中出现的实体、实体所执行的动作和实体之间的交互等;甚至还包含很多时序结构性语义信息,例如动作序列、步骤和段落结构等。而从数据的角度来看,视频往往同时包含了图像序列、音频(波形)和语音(文本)等模态。视频理解的目的就是通过各种精心设计的任务,利用多种不同模态的数据,来让计算机学会“浏览”视频,并产生“理解”行为。
代表论文:Dense Procedure Captioning in Narrated Instructional Videos
论文链接:https://www.msra.cn/wp-content/uploads/2019/06/DenseProcedureCaptioninginNarratedInstructionalVideos.pdf
视频可以看作是在时间维度上展开的一系列图像帧,但相较于“一目了然”的图片,视频需要人们花费更多的精力去观看并进行理解。如果机器能自动地提取视频内容的摘要,并对视频中的每一个结构化的片段给出相应的文字描述,这将能够大量地节省用户的时间——用户不再需要完整地浏览整个视频,而只需要浏览文字化的摘要即可获悉其中内容。(场景如图6所示)

图6:视频结构化片段相应文字描述的场景展示
为了满足这个需求,我们针对 “指导性视频 (Instructional Video)”,设计了一个名为Procedure Extractor的视频理解系统:通过输入视频和视频内的叙述性旁白(Narrative Transcript),输出视频中每一个步骤(Procedure)的时间片段(起始时间与结束时间),并且为每一个视频片段生成一段文本描述。
模型结构如图7所示。我们首先对视频旁白(Transcript)进行分句,再使用一个经过预训练的BERT模型提取句子特征表示,然后通过多层self attention获得整个transcript的特征表示,将其与利用ResNet抽取的视频帧特征拼接,并形成一个完整的特征矩阵。为了能处理不同长度Procedure的信息流动,我们仿照Fast-RCNN系列模型的方法,使用了多个不同大小的卷积核和多个不同尺度的Anchor来对整个视频特征矩阵进行卷积操作,并通过一个LSTM模型来挑选包含正确Procedure的Anchors。在描述生成阶段,我们使用与片段时间对应的视频、Transcript信息,通过一个Sequence to Sequence模型来生成最终的视频片段描述。
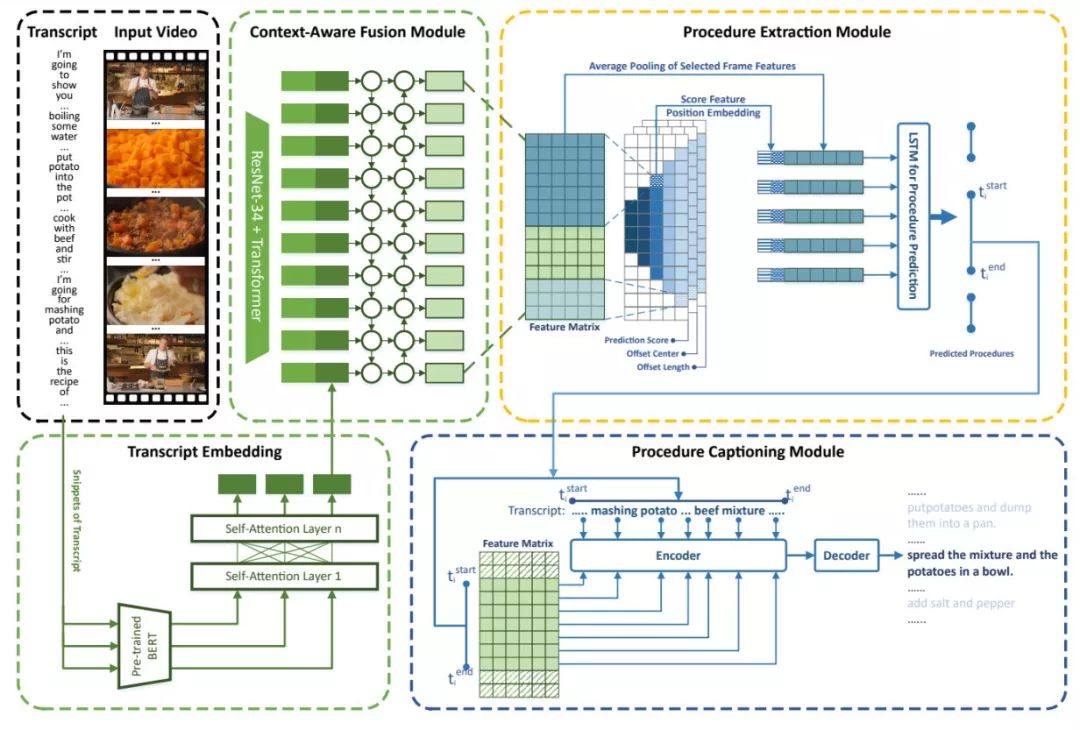
图7:Procedure Extractor模型架构
这项工作通过Azure Speech to Text云服务从视频中抽取旁白中Transcript。在YouCook II数据集上的Procedure Extraction和Procedure Captioning任务上都取得了最好的成绩。
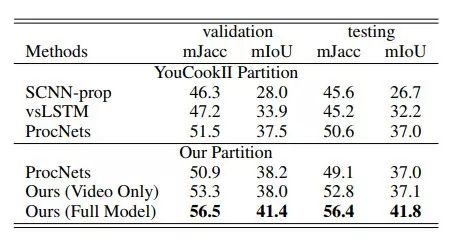
表6:不同模型在YouCook II数据集的Procedure Extraction任务上的实验结果
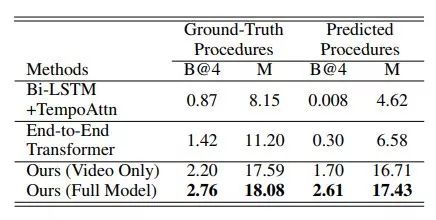
表7:不同模型在YouCook II数据集的Procedure Captioning任务上的实验结果
语义解析(semantic parsing)的目的是把自然语言自动转化为一种机器可以理解并执行的表达形式。在基于知识库的搜索场景中,语义解析模型可以将用户查询转换为可以在结构化知识库(如Microsoft Satori、Google Knowledge Graph)上可以执行的SPARQL语句;在企业数据交互场景中,语义解析模型可以将用户的语言转换为结构化查询语句(Structured Query Language, SQL);在虚拟语音助手场景中,语义解析模型可以将用户的语言转换为调用不同应用程序的API语句。
代表论文:Coupling Retrieval and Meta-Learning for Context-Dependent Semantic Parsing
论文链接:https://arxiv.org/abs/1906.07108
在该论文中,我们以对话式问答和基于上下文的代码生成为例介绍了我们在语义解析领域的研究进展。人们在对样例x做决策的时候,往往不是从头开始写,而是先从已有的知识库中找到相似的样例(x’,y’),然后进行改写。传统的retrieve-and-edit的方法通常只考虑一个(x’,y’)样例,而一个结构化规范语义表示可能来自于多个相关的样例中。以此为出发点,本论文提出了一种结合检索与元学习(meta-learning)的语义解析方法。
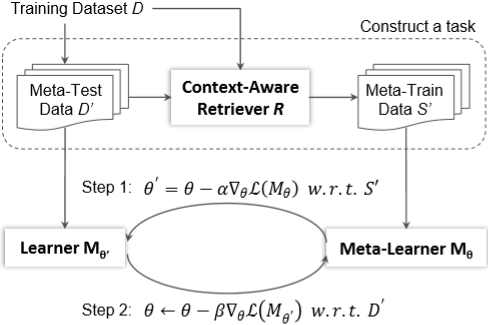
图8:结合检索与元学习和语义解析方法框架
整体框架如图8所示,其中包含了检索和元学习两部分。在检索部分,首先采样一批测试数据D’,然后利用基于上下文的检索模型R找到相似的样例S’作为训练数据,从而构成一个任务。在训练阶段,首先使用训练数据得到特定任务的模型M_(θ^')(step 1),然后再利用测试数据更新元学习器M_θ(step 2)。在预测阶段,先使用相似样本更新元学习器的参数,然后再进行预测。
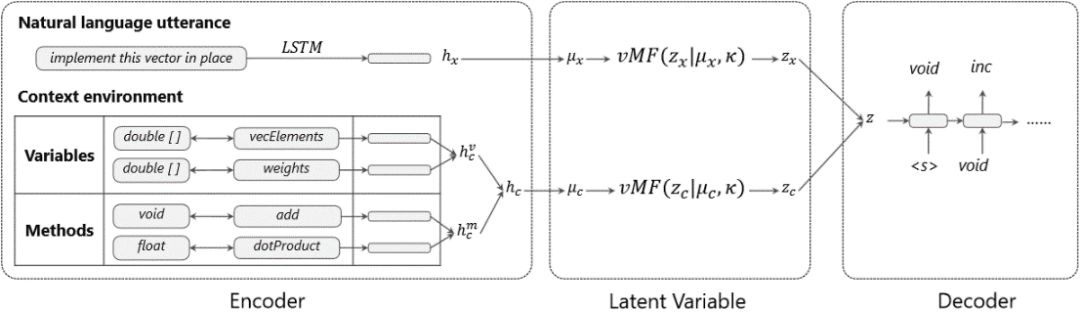
图9:基于上下文的检索模型框架
图9是基于上下文的检索模型,该模型是一个建立在变分自编码器(VAE)框架下的编码-解码(encoder-decoder)模型,将文本和上下文环境编码成一个潜层变量z,然后利用该变量解码出逻辑表达式。在检索的过程中,使用KL散度作为距离度量得到相似的样本。
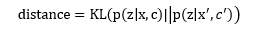
该论文在CONCODE和CSQA两个公开数据集上进行实验,可以看出结合检索和元学习取得了最好的成绩。
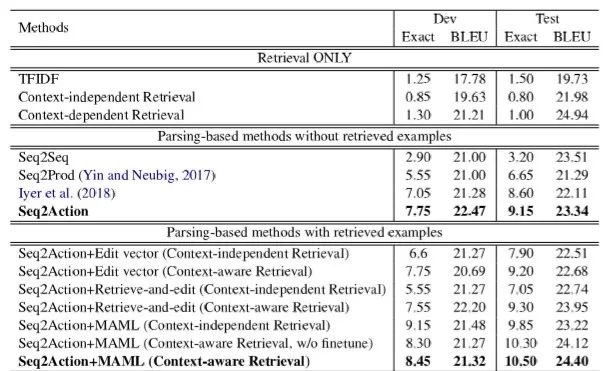
表8:不同模型在CONCODE数据集上的实验结果
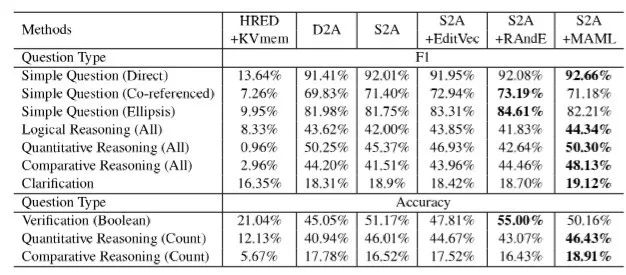
表9:不同模型在CSQA数据集上的实验结果
同时,这种检索模型不仅能够考虑语义信息,如“spouse” 和 “married”,而且能够考虑上下文信息,如HashMap和Map,因此能够很好提升检索的质量。
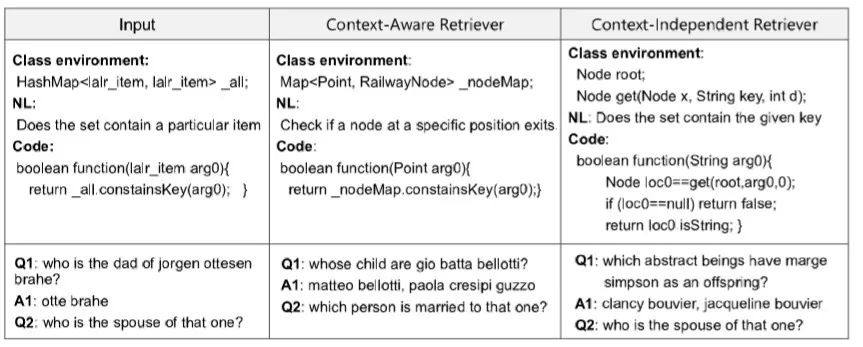
代表论文:Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation
论文链接:https://arxiv.org/abs/1905.08205
近年来,通过自然语言直接生成SQL查询语句引起了越来越多的关注。目前比较先进的模型在已有的NL-to-SQL的数据集上(例如WikiSQL、ATIS、GEO等)都取得超过80%的准确率。然而,在最近发布的Spider数据集上,这些已有的模型并没有取得令人满意的效果。究其原因,Spider数据集有两个特点:首先,Spider数据集里的SQL查询语句比目前已有的Text-to-SQL数据集更加复杂,例如SQL语句中包含GROUPBY、HAVING、JOIN、NestedQuery等部分。通过自然语言生成复杂的SQL查询语句尤其困难,本质原因是面向语义的自然语言和面向执行的SQL查询语句之间不匹配,SQL越复杂,不匹配的越明显;其次,Spider数据集是跨领域的(cross-domain),即训练和测试是在完全不同的database上做的。在跨领域的设置下,自然语言中出现了大量的out-of-domain(OOD)的单词,给预测列名造成了困难。
针对这两个挑战,我们提出了IRNet模型。IRNet使用了一个schema linking模块,根据数据库的schema信息,识别自然语言中的提到的表名和列名,建立自然语言和数据库之间的连接。接下来,为了解决面向语义的自然语言和面向执行的SQL查询语句之间不匹配的问题,与以往的Text-to-SQL方法直接生成SQL查询语句不同的是,IRNet首先生成一种中间的语义表示形式SemQL,然后再将中间表示转换成SQL查询语句。
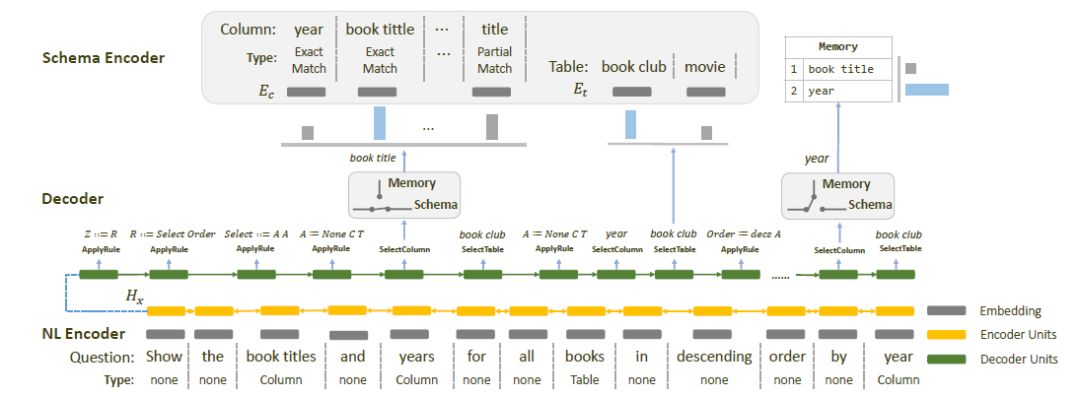
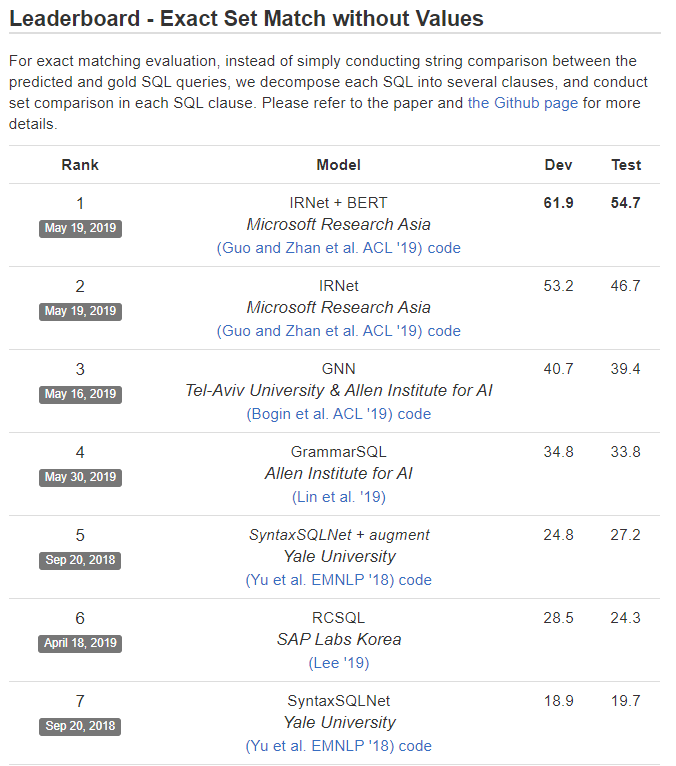
实验结果如表10所示,在Spider数据集上,IRNet实现了46.7%的准确率,比已有的最好方法提升了19.5%的准确率。同时,IRNet+Bert实现了54.7%的准确率。
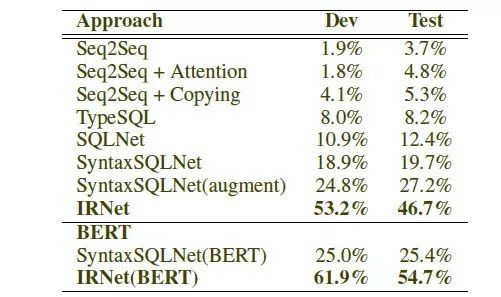
表10:不同模型在Spider数据集上的实验结果
到目前为止,微软亚洲研究院的IRNet模型在Spider Challenge比赛上取得了第一名的成绩。
无监督机器翻译仅仅利用单语的数据而不是双语并行数据进行训练,对于低资源的语言翻译非常重要。当前,无监督机器翻译在相似语言对上(例如英语-德语、葡萄牙语-加利西亚语)取得了非常好的效果。然而在距离较远的语言对上(例如丹麦语-加利西亚语),由于无监督的语义对齐比较困难,通常表现较差。在实验中,我们发现在距离较近的葡萄牙语-加利西亚语上能取得23.43的BLEU分,而在距离较远的丹麦语-加利西亚语上只有6.56分。微软亚洲研究院的研究人员尝试解决远距离语言的无监督翻译问题。
代表论文:Unsupervised Pivot Translation for Distant Languages
论文链接:https://arxiv.org/abs/1906.02461
我们考虑到两个距离较远的语言能通过多个中转语言链接起来,其中两个相邻的中转语言间的翻译易于两个原始语言的翻译(距离更近或者可用单语数据更多)。如图13所示,距离较远的丹麦语-加利西亚语(Da-Gl,图中红色路径)能拆分成丹麦语-英语(Da-En)、英语-西班牙语(En-Es)、西班牙语-加利西亚语(Es-Gl)三跳无监督翻译路径(图中蓝色路径),拆分后的翻译性能为12.14分,相比直接的丹麦语-加利西亚语翻译(6.56分)有大幅提高。因此,我们在论文中针对远距离语言对提出了无监督中转翻译(Unsupervised Pivot Translation)方法。
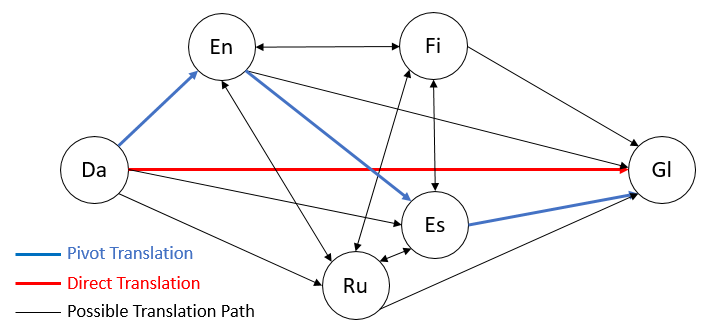
无监督中转翻译面临的一个挑战是两个语言之间可选路径很多(如图13蓝色、黑色路径所示,实际场景中可选路径更多),而不同路径的翻译精度不同,如何选择精度最高的路径对于保证无监督中转翻译的效果非常重要。由于可选路径随着跳数以及中转语言数呈指数增长趋势,遍历计算每条路径的精度代价巨大。对此,我们提出了Learning to Route(LTR)的路径选择算法,该算法以单跳的BLEU分及语言ID作为特征,利用多层LSTM模型预测多跳翻译的精度,并据此来选择最好的中转路径。关于LTR算法的详细内容可参考论文。
我们在20个语言一共294个语言对上进行了实验,来验证我们的无监督中转翻译以及LTR路径选择算法的性能。表11列出了部分语言对的实验结果,其中DT代表直接从源语言到目标语言的无监督翻译,LTR代表我们提出的中转算法,GT(Ground Truth)代表最好的中转翻译,也决定了我们方法的上限,GT(∆)和LTR(∆)分别代表GT和LTR相对于直接翻译DT的提升,Pivot-1和Pivot-2代表中转路径的两个中转语言(我们最多考虑三跳路径)。如果是一个两跳路径,那么Pivot-1和Pivot-2相同;如果是直接翻译,那么Pivot-1和Pivot-2为空。
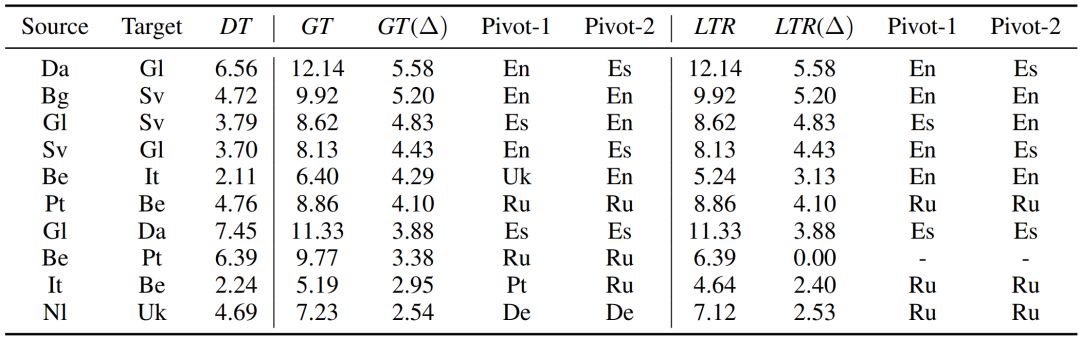
表11:Learning to Route(LTR)路径选择算法在部分语言对上的实验结果
可以看到,无监督中转翻译相比无监督直接翻译有较大的BLEU分提升,而且我们提出的LTR方法的精度非常接近于最好的中转翻译GT,表明了我们提出的无监督中转翻译以及LTR路径选择算法的有效性。例如,我们的方法(LTR)在丹麦语-加利西亚语(Da-Gl)、保加利亚语-瑞典语(Bg-Sv)、葡萄牙-白俄罗斯语(Pt-Be)上分别有5.58、5.20、4.10分的提升。
端到端开放域对话生成是人机对话领域近几年的一个研究热点。开放域对话生成中的一个基本问题是如何避免产生平凡回复(safe response)。一般来讲,平凡回复的产生来源于开放域对话中存在的输入和回复间的 “一对多”关系。相对于已有工作“隐式”地对这些关系进行建模,我们考虑“显式”地表示输入和回复间的对应关系,从而使得对话生成的结果变得可解释。不仅如此,我们还希望生成模型可以允许开发者能够像“拼乐高玩具”一样通过控制一些属性定制对话生成的结果。
代表论文:Neural Response Generation with Meta-Words
论文链接:https://arxiv.org/pdf/1906.06050.pdf
在这篇论文中,我们提出用meta-word来表示输入和回复间的关系。Meta-word代表了一组回复属性(如图14中的回复意图(Act),回复长度(Len)等)。利用meta-word进行对话生成的好处包括:(1)模型具有很好的可解释性;(2)通过订制meta-word,开发者可以控制回复生成;(3)情感,话题,人格等都可以定义为meta-word中的一个属性,因此诸如情感对话生成,个性化对话生成等热点问题都可通过该论文提出的框架解决;(4)工程师们可以通过增加或调整meta-word不断提升生成模型的性能。

图14:基于meta-word的回复生成
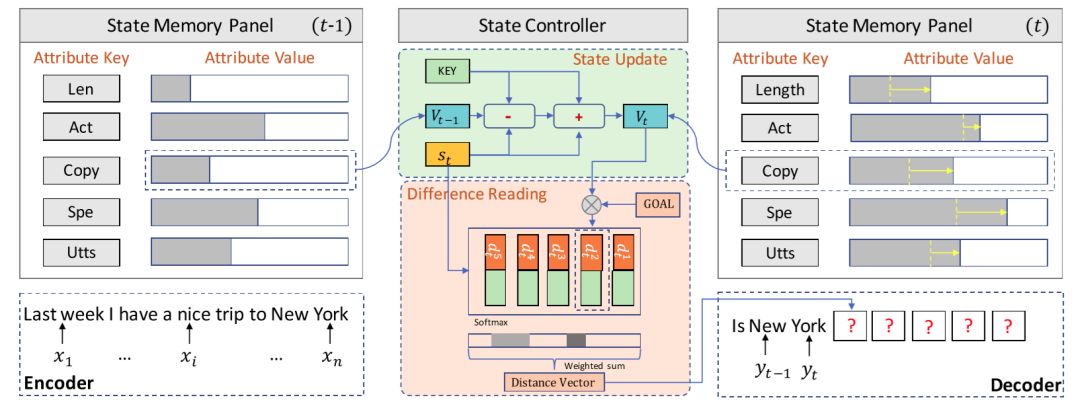
利用meta-word进行回复生成需要解决两个问题:(1)如何确保回复和输入相关;(2)如何确保回复能够如实地表达预先定义的meta-word。为了解决这两个问题,我们将meta-word的表达形式化成回复生成中的目标,提出了一个基于目标跟踪记忆网络的生成模型(如图15)。该网络由一个状态记忆板和一个状态控制器组成,前者记录生成过程中meta-word的表达情况,后者则根据当前已经生成的部分动态地更新记忆板中的存储并将目前的表达情况和最终表达目的的差距传达给解码器。在模型学习过程中,我们在传统的似然目标之外增加了一个状态更新损失,以使得目标追踪能够更好地利用训练数据中的监督信号。不仅如此,我们还提出了一个meta-word的预测方案,从而使得整个架构可以在实际中使用。
我们在Twitter和Reddit两个数据集上考察了生成回复的相关性、多样性、“一对多“关系建模的准确性、以及meta-word表达的准确性。不仅如此,我们还对生成结果进行了人工评测。实验结果如下:
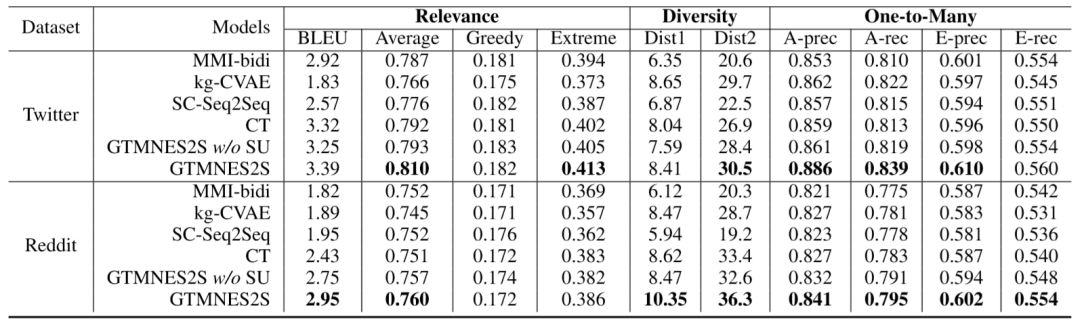
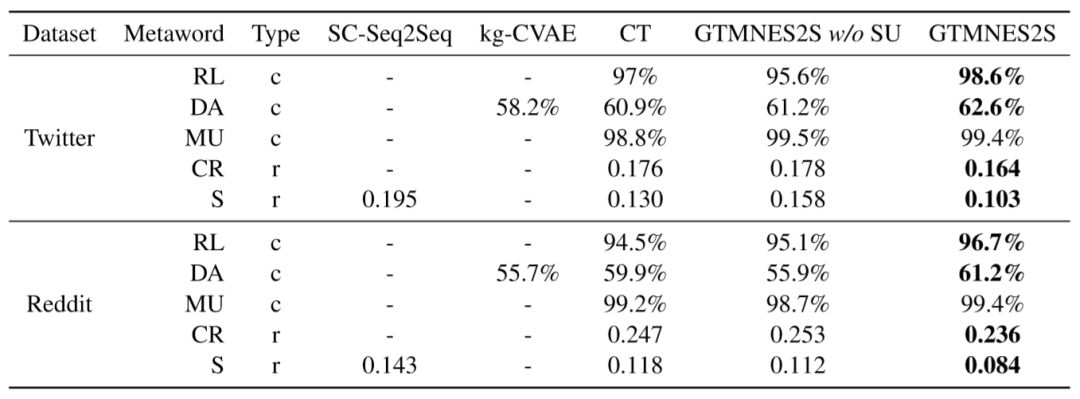
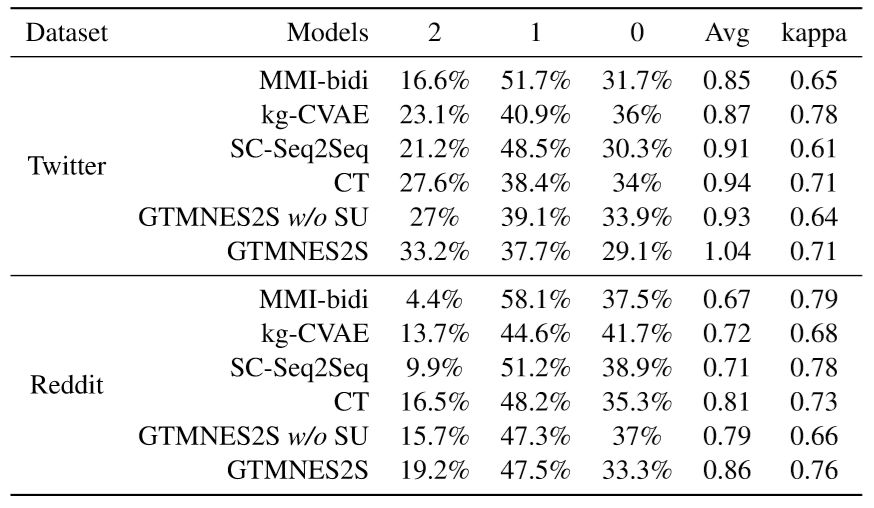
更有意思的是,当我们逐渐地增加meta-word中的属性变量,我们发现验证集上的PPL会逐渐降低,这也印证了“通过调整meta-word可以不断提升模型性能”的论断。
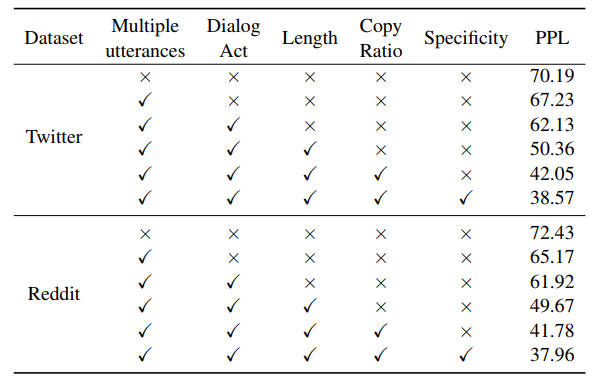
表15:不同属性带来的验证集PPL变化
点击“阅读原文”,即可下载相关录取论文。
你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




